
Univerzita Hradec Králové
Fakulta informatiky a managementu
Katedra informačních technologií
Diplomová práce
Autor: Bc. David Zejda
Informační management
Vedoucí práce: Mgr. Daniela Ponce
Chrudim duben 2005
Anotace – abstract
Práce v úvodních částech systematizuje současný stav na poli webových portálů, e-business a jiných aplikací, sleduje trendy a odhaduje budoucí vývoj. Dále předkládá výběrový přehled formalismů pro zachycení složité informační struktury, s důrazem na sémantické sítě a ontologie a jejich možnosti. Především na případových studiích aplikací pro evidenci a organizaci dat, elektronický obchod a administraci serveru - aplikací, u kterých zatím není využívání ontologií běžné - ukazuje potenciál ontologií a zároveň odvozuje parametry univerzálně použitelného meta modelu ontologie. Větší část práce je tvořena analýzou a podrobným návrhem meta modelu a souvisejících provozních a konfiguračních požadavků. Na tomto základě je postaven návrh knihovny pro zachycení ontologie odpovídající tomuto meta modelu a manipulaci s ní. V závěrečné části jsou zvažovány architektury případných aplikací, které by na knihovně mohly být postaveny, a také technologie, nástroje a standardy, které mohou sloužit pro jejich implementaci.
Ontological model for portals
Introductory parts of the work systematizes current state of web portals, e-business and similar applications, traces the trends and predicts the incoming advancement. Following sections consist of the selective summary of formalisms for a tangled information structure representation, with emphasis on semantic networks, ontologies and their potentialities. Especially on the sequent case studies of applications for data organisation and management, e-shop and server administration – applications which are not enriched by ontologies commonly – demonstrates the potential of ontologies and simultaneously deduces, which parameters of ontology meta model would lead to its possible universal utilisation. The major part of the thesis contains analysis and particularly detailed design of the meta model and the related operational and configuration requirements. The requirements makes the basis for design of the library, which will be able to catch and manipulate the ontology conforming the meta model. In the last part, the diverse architectures of applications utilising the library and also the technologies, tools and standards, useful for implementation are considered.
Poděkování
Moje poděkování si zaslouží vedoucí práce, Mgr. Daniela Ponce za podnětné připomínky a především za to, že mě před asi třemi lety vůbec přivedla na stopu ontologiím.
Nemohu rovněž zapomenout na ten dlouhý zástup vývojářů a výzkumníků, kteří vložili svou energii a čas do kancelářského balíku OpenOffice.org, ve kterém práci píši, do vývojového prostředí NetBeans, systému pro jednotkové testování JUnit a mnoha a mnoha dalších nástrojů a knihoven, které jsem použil při vývoji prototypu.
Velké poděkování zaslouží také celý velký sbor autorů těch všech knih, článků a webových stránek, ze kterých jsem tolik načerpal...
Prohlášení
Prohlašuji, že jsem diplomovou práci zpracoval samostatně a s použitím uvedené literatury.
V Chrudimi dne 26. dubna 2005 David Zejda
Copyright ©2005 Informace, které jsou v tomto dokumentu zveřejněny mohou být chráněny jako patent. Jména produktů jsou použita bez záruky jejich volného použití. Některé názvy mohou být registrovanými známkami nebo jinak chráněny. Při sestavování textu jsem se snažil postupovat pečlivě, nicméně nemohu poskytnout záruku bezchybnosti. Všechna práva vyhrazena. Žádná část nesmí být reprodukována a distribuována bez předchozího svolení autora, výjimku tvoří použití krátkých části textu pro akademické, nekomerční účely a pro účely recenzí, vždy ale musí být uveden zdroj včetně adresy http://www.zejda.net/ontoportal.
Obsah
I Úvod 1
A Cíl 2
B Motivace 3
C Jak číst dál 5
II Teoretická část 6
A Úvod a systematizace internetových aplikací 7
A.1 Typy webových aplikací 7
1.1 Systémy pro správu obsahu (CMS) 8
1.2 Kolaborativní systémy 10
1.3 E-Commerce 12
1.3.1 B2C 12
1.3.2 C2C 12
1.3.3 B2B a B2G 13
1.4 .. a mnohé další 14
A.2 Vize: Virtuální firma 14
B Úvod do problematiky ontologií 16
B.1 Zachycení složité informační struktury 16
1.1 Pojmenování a meta data 16
1.2 Grafy 18
1.3 Sémantické sítě 19
1.4 Ontologie 22
1.4.1 Význam 22
1.4.2 Ontologický model a meta model 24
1.4.3 Souvislosti s jinými formalismy 24
1.4.3.a Ontologie a datové modelování 25
1.4.3.b Ontologie a objektové modelování 25
1.4.3.c Ontologie a rámce 26
1.4.4 Ontologické inženýrství 27
1.4.4.a Nástroje 28
1.4.4.b Činnosti 29
1.4.4.c Znovupoužití ontologií 29
1.5 Konkrétní ontologické slovníky 30
1.5.1 Top-level ontologie 30
1.5.1.a WordNet 30
1.5.1.b Cyc 30
1.5.1.c The Suggested Upper Merged Ontology (SUMO) 32
1.5.1.d Další zajímavé projekty 34
1.5.2 Vybrané ontologie pro podniky a obchod 34
1.5.2.a KSL 34
1.5.2.b AIAI Enterprise 34
1.5.2.c Business Management Ontology (BMO) 35
C Synergie ontologií a webových aplikací 37
C.1 Vize: Ontologický Internet 37
C.2 Obecné přínosy 38
2.1 Přehled a zvládnutelnost 39
2.2 Spojení 40
2.3 Komunikace a vzájemné porozumění 41
C.3 Sémantický web 42
3.1 Obsah, tvorba a údržba 42
3.2 Využití 44
C.4 Podle typu média 45
4.1 Lexikografická data 45
4.2 Procesy a spolupráce 46
4.3 Multimédia 46
4.4 Správa sítě 47
C.5 Podle architektury 48
C.6 Podle oborů a činností 49
6.1 Komerční 49
6.2 Nekomerční 50
III Projektové studie 53
A Evidence a organizace dat 55
A.1 O co jde 55
A.2 Běžné řešení bez ontologií 56
A.3 Přínos ontologií 57
A.4 Problémy a rizika řešení s ontologiemi 59
A.5 Kostra architektury ontologického řešení 60
5.1 Struktura 60
5.2 Charakter 61
5.2.1 Charakter logiky dotazovacího modulu 62
5.3 Cíle 64
5.3.1 Složitost modulů 64
5.3.2 Kritéria posouzení úspěchu 65
5.4 Stav 66
A.6 Klíčové parametry ontologického meta modelu 69
A.7 Významné koncepty a vztahy 69
7.1 Základní koncepty 69
7.2 Příklad doménově specifické aplikace 70
7.3 Důsledky ontologického modelu pro dotazování 71
B Elektronická komerce 73
B.1 O co jde 73
B.2 Běžné řešení bez ontologií 74
B.3 Přínos ontologií 74
B.4 Problémy a rizika řešení s ontologiemi 76
B.5 Kostra architektury ontologického řešení 77
5.1 Struktura 77
5.2 Charakter 81
5.2.1 Uživatelské rozhraní 81
5.2.2 Ostatní moduly 82
5.3 Cíle 82
5.4 Stav 83
B.6 Klíčové parametry ontologického meta modelu 83
B.7 Významné koncepty a vztahy 87
7.1 Základní koncepty 87
7.2 Příklad doménově specifické aplikace 88
7.2.1 Produkty 88
7.2.2 Tvorba ontologie 90
C Administrace serveru 93
C.1 O co jde 93
C.2 Běžné řešení bez ontologií 93
2.1 Výchozí stav 93
2.2 Běžná řešení 94
C.3 Přínos ontologií 95
C.4 Problémy a rizika řešení s ontologiemi 96
C.5 Kostra architektury ontologického řešení 97
5.1 Základní komponenty 98
5.2 Některé podstatné podrobnosti 100
5.3 Spolupráce 101
5.3.1 Základní model spolupráce 101
5.3.2 Architektura založená na naslouchačích 103
C.6 Klíčové parametry ontologického metamodelu 103
C.7 Významné koncepty a vztahy 104
D Další možnosti praktické integrace 108
IV Projekt ontologického systému 111
A Meta model ontologie 114
A.1 Koncepty a instance 114
1.1 Dilema instance 115
1.1.1 Problémy rozlišení konceptů a instancí 116
1.1.2 Řešení těchto problémů 118
1.1.2.a Odvozené rozlišení konceptů a instancí 119
1.2 Entity 120
1.3 Hodnotnost, umístění, externí zdroje 121
1.3.1 Samohodnotná ontologie 121
1.3.2 Meta ontologie 121
1.3.3 Parametry řešení 122
1.4 Hierarchie 123
1.4.1 Kategorizace 123
1.4.2 Dynamická kategorizace 124
1.4.3 Dědičnost, nejprve obecně 125
1.4.4 Dědičnost vícenásobná 127
1.4.4.a Potřebujeme ji? 127
1.4.4.b Komplikace vícenásobné dědičnosti 129
A.2 Atributy 132
2.1 Doména 133
2.1.1 Datový typ 133
2.1.2 Relevance 136
2.2 Prostředky pro zvýšení robustnosti 137
2.2.1 Mechanismy vyžádání 137
2.2.2 Mechanismy podsouvání 138
2.3 Odvozený atribut 138
A.3 Vazby 139
3.1 Orientace a navigabilita 140
3.1.1 Neorientované 140
3.1.2 Orientované 140
3.1.3 Navigabilita 141
3.2 Hierarchie vazeb 141
3.2.1 Vztahy meta modelu 141
3.2.2 Vztahy modelu 142
3.3 Vazby více prvků 143
3.3.1 Multilaterální 143
3.3.2 Násobné 145
3.4 Prostředky zvýšení robustnosti 146
3.4.1 Rozhodovací řetězce 146
3.4.2 Struktura rozhodovacích řetězců 147
3.4.3 Rozhodnutí v rozhodovacích řetězcích 148
3.4.4 Mechanismus aplikace pravidel 149
3.4.5 Automatický typ vazby 149
3.5 Důsledky dědičnosti účastníků 150
3.5.1 Dědictví vazeb 150
3.5.2 Další automatické manipulace vazbami 151
A.4 Pravidla 152
4.1 Struktura pravidel 153
4.2 Predikát 153
4.2.1 Báze 153
4.3 Efekty pravidel 155
4.4 Operátory 156
B Provozní požadavky 157
B.1 Sledování provozu 157
1.1 Správa změn a událostí 157
1.1.1 Statistika 157
1.1.2 Návrat 158
1.1.3 Zachycení faktoru času 158
1.2 Události – naslouchači 158
1.2.1 Probublávání zpráv 159
1.2.2 Využití pro RSS 160
1.3 Strategie vývoje 160
1.3.1 Strategie likvidace 160
1.3.1.a Nakládání s potomky 161
1.3.1.b Nakládání s instancemi atributů 161
1.3.1.c Nakládání s vazbami 161
1.3.2 Strategie duplicity 162
B.2 Konfigurovatelnost meta modelu 162
2.1 Důvody pro konfigurovatelnost 163
2.2 Mechanismus vynucené integrity 164
2.3 Konfigurovatelné vlastnosti meta modelu 164
2.3.1 Provozní nastavení 165
2.3.2 Dědičnost 165
2.3.3 Atributy 165
2.3.4 Vazby 166
2.4 Profily nastavení meta modelu 166
2.4.1 Smysl a charakter profilů 166
2.4.2 Vybrané profily 168
2.4.3 Znovupoužití profilů 169
2.5 Režimy a módy 170
2.5.1 Základní režimy 170
2.5.2 Základní módy 170
C Struktura a technologie 172
C.1 Systém jako celek 172
1.1 Základní a rozšiřující části 172
1.2 Příklad komunikace 173
1.3 Původ jednotlivých komponent 175
C.2 Jádro a API 176
2.1 Model 176
2.1.1 Relační model 177
2.1.2 Model založený na XML 179
2.1.3 Objektový model 179
2.1.4 Logické, deklarativní, pravidlové apod. 180
2.2 Platforma 182
2.2.1 Přenositelnost 184
2.2.2 Jazyky kompilované 185
2.2.3 Jazyky interpretované 186
2.2.4 Jazyky interpretované s bytekompilací 187
2.2.5 Volba jazyka 188
C.3 Zajištění perzistence 189
3.1 Soubory 189
3.1.1 Serializace 189
3.1.2 XML mapování 190
3.2 Objektově orientované databázové systémy 191
3.3 Objektově-relační mapování 191
3.4 Objektově-relační technologie 192
3.5 Mnoharozměrné databáze 193
3.6 Úložiště pro stromové struktury 194
3.6.1 LDAP (Lightweight Directory Access Protocol) 194
3.6.2 Nativní XML databáze 194
3.7 Snahy o univerzální přístup 195
3.8 Zvolené řešení 196
C.4 Uživatelské rozhraní 199
4.1 Scénář „desktop“ 200
4.2 Scénář „z intranetu“ 201
4.3 Scénář „z Internetu“ 201
4.3.1 Vytváření dynamického obsahu 202
4.3.1.a Pull 203
4.3.1.b Push 204
4.3.2 Formuláře 205
4.3.3 Kontroler 206
4.4 Scénář „mobilní“ 206
4.5 Scénář „hendikepovaní“ 207
4.6 Jak to tedy vyřešíme? 207
C.5 Neinteraktivní rozhraní 209
5.1 Sestavy zejména pro tisk 209
5.2 Netiskové výstupy, komunikace 212
5.3 Univerzální řešení 213
5.3.1 Rizika 213
5.3.2 Požadavek a řešení 214
C.6 Infrastruktura nasazení 216
6.1 Nevrstvená infrastruktura 217
6.2 Dvouvrstevná infrastruktura 218
6.2.1 S mohutným klientem 218
6.2.2 S tenkým klientem 219
6.3 Třívrstevná infrastruktura 219
6.4 Software jako služba (SaaS) 220
6.5 Data jako služba (DaaS) 221
6.6 Nezávislí agenti 223
6.6.1 Inteligentní agenti 224
6.6.1.a Charakteristické rysy 224
6.6.1.b Použití 225
6.7 Infrastruktura pro navrhovaný systém 226
V Příloha - CD 227
VI Závěr 229
A Shrnutí výsledků 230
B Jak pokračovat 232
Na titulním listě jste si mohli povšimnout obecného cíle práce. Ještě než se vrhneme na všechny ty zajímavé otázky okolo webových aplikací a ontologií, potřebujeme tento cíl trochu více rozvést – stanovit, o co nám vlastně jde.
Co cílem není
Tak tedy, hlavním cílem není
vytvořit učebnici pro práci s ontologiemi
popsat nějaký konkrétní nástroj či technologii
srovnávat a hodnotit technologie
vytvořit ucelený a vyčerpávající přehled čehokoliv – třeba internetových aplikací
To vše se ale v práci alespoň částečně objeví, ale pouze účelově, k podpoře cíle.
Co cílem je
Cílem naopak je
navrhnout univerzálně použitelnou knihovnu pro práci s ontologiemi
K tomu bude třeba
prozkoumat souvislosti, východiska a trendy v oblasti internetových aplikací
trochu uspořádat typy těchto aplikací
probrat základní východiska ontologií, částečně i jejich současný význam a vlastnosti
provést několik projektových studií pro odlišné typy nasazení navrhovaného systému
a především, rozebrat vlastní systém z různých hledisek
při tom všem hledat souvislosti se současným stavem poznání v oblasti ontologií
a aplikovat poznatky o těch typech aplikací, v nichž by systém mohl najít uplatnění
Možná se ptáte, co mě dovedlo k námětu, který zdobí desky. Tedy, jsou to především určité nepříjemné zkušenosti s různými systémy, se kterými jsem dosud pracoval - nedostatky některých z nich se staly východiskem již zmíněných projektových studií.
..co se mi nelíbilo
Nelíbí se mi, když musím cokoliv z jednoho programu ručně přepisovat do druhého. Nemám rád duplikaci a bojím se nekontrolované redundance. Považuji za nevhodné, když data o produktech jsou jednou v produktové databázi, podruhé v účetním systému, potřetí v elektronickém obchodě dodavatele, počtvrté v nějaké recenzi na cizím webu... a nikde žádné pořádné vazby, které by hned, jednoznačně a automatizovaně udávaly, že jde stále o ten samý produkt.
Nelíbí se mi, že mi dokumenty leží v adresářích; adresářová struktura sice má určitý systém a logiku, ale je to pořád příliš málo. Že pokud budu potřebovat dokumenty sdílet s někým jiným, narazím na to, že on používá také nějakou organizační strukturu, trochu podobnou, ale přeci jinou. Že spojení těchto struktur lze provést pouze ručně. Ano mohl bych používat systém pro správu dokumentů, ale problémy s univerzálně platnou a univerzálně sdílitelnou organizací tím stejně nevyřeším. Chybí mi strojově srozumitelný slovník.
..a pak přišly ontologie
Před pár lety jsem zkoumal přesně takové věci a hledal jsem řešení. A pak přišly ontologie – nebo spíše já jsem přišel k nim... Od té doby na každém kroku pozoruji možnosti aplikace ontologií. Myslím, že je jen málo programů, které by nemohly být povýšeny v použitelnosti aplikací ontologií. Pokud by data – jakákoliv data - byla lépe zachycena, tedy včetně sémantického významu, případně o tuto významovou rovinu doplněna, otevřelo by to široké možnosti, některými z nich se budu zabývat v dalším textu.
..které toho umí tak moc
Ano, tuším možnosti kvalitnější práce s takovými systémy, ale také obrovské možnosti zvýšení interoperability a především masivní integrace. Totiž, to je to, co podle mého názoru schází současným aplikacím především – možnost budovat z nich integritní, kompaktní celky s hodnotou společně realizované služby pro uživatele. Když ale říkám integritní, v žádném případě nemyslím monolitické, spíše poskládané z mnoha nezávislých komponent, pouze překrytých jednotící vrstvou. Masivní integrace především obchodních aplikací může být první fází integrace v mnohem větším měřítku, integrace odpovídající trendům ekonomiky nové doby. K tomu ale ještě dospějeme...
pokud spěcháte..
Pokud spěcháte celou teoretickou část možná přeskočíte – jejím smyslem je pouze uspořádat různé souvislosti, a tak vybudovat základ pro návrh ontologického systému. Možná si prolétnete pouze nadpisy, tuším, že se zastavíte asi v částech s vizí, protože vize jsou obecně lákavé.. Pokud víte co jsou ontologie zač, asi přeskočíte celou část o nich a skončíte až u projektových studií. Z nich považuji za nejzajímavější tu poslední, o administraci serveru, vás třeba ale zaujme některá jiná.
Dál to již nechám na vás; každopádně jádrem práce je rozbor meta modelu ontologie navrhovaného systému, v závěsu podle významu jsou kapitoly o provozních požadavcích a konfigurovatelnosti. Část Struktura a technologie obsahuje už zase spíše spoustu přehledového a srovnávacího materiálu pro nalezení odpovědí na otázky související s architekturou aplikací na systému postavených, a tak ji můžete třeba přeskočit.
Pokud toho času máte opravdu málo, asi bude nejlepší prolistovat nosné části, prohlédnout obrázky a větší nadpisy a samozřejmě přečíst závěr – tak si uděláte ucelenou představu o tom, co vlastně práce řeší a třeba se k ní vrátíte někdy později...
jak se vyznat aneb formátovací konvence
Základní text je na celou použitou šíři stránky, pouze ty skutečně veliké obrázky ho občas přesáhnou. O dva řádky výše vidíte styl používaný pro uvození definovaných anebo vysvětlovaných položek, někdy sloužící také jako podnadpis nejnižší úrovně.
a toto je ta vlastní definice
takhle vypadá příklad, co má charakter souvislého textu
a takhle zdrojový nebo pseudozdrojový kód
..a ještě tohle je poznámka na okraj, která dodává nějakou zajímavou souvislost, ale pro pochopení hlavních myšlenek je vedlejší
Vraťme se zpátky na zemi a pěkně od podlahy probereme, s čím se můžeme na Internetu setkat. V tuto chvíli nám nejde o vyčerpávající seznam a ani o dokonalé členění, koneckonců ani hranice nejsou pevně definovatelné. Cílem je spíše nastínit šíři typů webových aplikací, aby náš rozhled nebyl příliš zúžený, až budeme promýšlet ontologický systém, který by se mohl stát jejich jádrem. Zmiňuji zde především typy a pokud mluvím o technologiích, většinou jen obecně. Výjimku ale učiním hned v úvodu:
portálové systémy
Existuje mnoho systémů, které se zabývají integrací komponent pro účely prezentace uživatelům. Komponentám se často říká portlety, jsou to taková malé okénka do dat z různých zdrojů – z místní databáze nebo třeba z nějakého zpravodajského serveru. Tvorba portálu pak znamená především výběr a vhodnou kombinaci portletů.
Příkladem portálových systémů jsou například Jakarta Jetspeed, Liferay, Exo, Pluto, JA-SIG uPortal, Jahia, Gluecode Portal Foundation Server, jPortlet...
Vzhledem ke zvoleném námětu cítím povinnost v úvodu vymezit, co rozumím pojmem portál. Pojem je to totiž značně vágní.
portál v užším smyslu
Pan Hlavenka v [BYZNETH99] píše: „Na začátku roku 1998 se v oblasti internetových médií objevil nový pojem – portál. Představa několika webů, které budou sloužit jako vstupní brány do Internetu, rozcestníky k dalším službám, obchodům a médiím. Samozřejmě opět s určitou manipulací – portály měly ukazovat jen na ty služby a obchody, které vlastníkům portálu zaplatí peníze. … Idea portálu v této podobě zahynula v rekordní době – dnes se sice pojem ze setrvačností dále používá, ale v jiném smyslu, spíše jako hodnotná destinace – místo kam uživatel přijde a kde najde dostatečně zajímavé a provázané nabídky, které neodmítne a kde zůstane. Pokus o zmanipulování Internetu nevyšel.“
Výrok je z roku 1995 a to, že myšlenka podobně manipulativních portálů se postupně opět vrací, u nás v podobě portálů jako seznam.cz či atlas.cz, je dokladem neobyčejného tempa vývoje Internetu. Každopádně, takovými portály se příliš zabývat nebudeme.
My budeme pod pojem portál shrnovat mnohem širší paletu aplikací:
portál v pojetí práce
V zásadě jakýkoliv počítačový systém, který integruje heterogenní zdroje a využívá síťovou infrastrukturu.
Občas se ale nevejdeme asi ani do takto široce pojaté definice, protože cílem je, aby v dalších kapitolách navrhovaný systém byl opravdu hodně univerzální.
A ještě jedna věc - nebudeme se příliš zabývat těmi typy „webů“, které má na mysli většina lidí, když mluví o webové prezentaci.
webová prezentace
Plní pouze roli jakési reklamní vývěsky, bezostyšně propaguje firmu nebo výrobek. Soudím, že reklamní vývěsky jsou přežitkem doby, nevhodným přenesením starých modelů do dynamického prostředí elektronického věku. Nezajímavost, uzavřenost, neupřímná a neobjektivní sebechvála, to jsou znaky, které na Internetu spolehlivě odradí, zejména když objektivní informace jsou na dva kliky daleko.
systémy pro správu dokumentů (DMS)
Znalosti se stávají základem ekonomiky. Intelektuální kapitál může být nejsilnější zbraní v silné konkurenci. Je třeba zachytit a řídit tok informací v organizaci, dost možná je to důležitější než tok vlastního zboží. Systém pro správu dokumentů dělá přesně to – umožňuje řídit proces získávání, sdílení, zaznamenávání, revidování, distribuce dokumentů a informací, které obsahují. Kompletní systém správy dokumentů umožní kontrolovat všechny procesy spojené se všemi typy dokumentů v organizaci, jako s tabulkami, prezentacemi, textovými dokumenty..
redakční a publikační systémy
Podporují spolupráci týmu na sdíleném obsahu. Definují role jako autor, redaktor, korektor, překladatel a podle rolí přidělují práva. Oddělují proces schvalování od vlastní publikace. Články postupně procházejí různými stavy. Většina publikačních systémů obsahuje také podporu pro definici rubrik, souvislostí, typů článků a také pro včlenění obrázků, příloh.
blogy
Blog je médium dostupné přes web. Publikace nového článku je „blogování“, správce a autor je „blogger“. Pro blogy je také typické, že jsou tvořeny spíše krátkými články a jsou aktualizovány často, lépe pravidelně a nejlépe denně; obsahují subjektivní názor autora. Blogovací software jsou programy, které umožní snadno a rychle zveřejňovat zprávy a blog spravovat bez nutnosti rozumět technickým aspektům – nejčastěji přímo přes webové rozhraní. Tudíž blogovat může každý kdo chce a najde dostatek času. Blogy tvoří paralelu ke klasickým zpravodajským, ale i oborovým webovým serverům a více odpovídají původní myšlence decentralizovaného Internetu.
galerie
Systémy pro zveřejnění a správu kolekcí fotografií a obrázků. Většinou s pohodlným rozhraním, efektními výstupy, možnostmi řadit a prohledávat, připojovat klíčová slova atd.
publikačně - aplikační systémy
Redakční systém je speciálním typem obecnějšího systému. Systému, který umožní volně definovat datové objekty, jejich možné stavy a přechody mezi stavy, role tvůrců a uživatelů... Na základě takového systému lze postavit jak redakční systém, tak třeba systém pro podporu jednání a hlasování na různých poradách, podporu různým komunitám a skupinám... V zásadě je v takovém systému možné nadefinovat i prostředí podobné blogu nebo třeba Wiki, jež bude popisován dále.
Příkladem takového univerzálního systému je třeba plně objektový Plone postavený na aplikačním serveru Zope.
P2P pro sdílení dat
Nemá cenu je definovat – snad jen některá jména: Bittorent, eDonkey, Gnutella, DC++, eXeem, Soulseek
MUD (multi user dungeon)
Zařadil jsem jej jako příklad kolaborativní zábavy. Je to počítačový program, typicky běžící na internetovém serveru, umožňuje mnoha uživatelům sdílet virtuální realitu obvykle smyšleného světa. Většina MUD je z větší části textově provedenou variantou RPG (role-playing games).
webmail
Vlastně jen webové rozhraní poštovní schránky, ale v důsledku usnadňuje komunikaci, tudíž jsem jej zařadil jako příklad kolaborativního systému.
groupware
Systémy pro podporu práce ve skupině. Obvykle sestává z několika softwarových komponent, jako sdílený adresář kontaktů, webmail, plánovací kalendář, řízení workflow, nástěnka, sdílené dokumenty apod.
Pěkný přehled konkrétních systémů je třeba [GRPWREB].
wiki
Původní definice wiki podle autora myšlenky a tvůrce prvního wiki systému p. Warda:
The simplest online database that could possibly work.
Wiki je kus softwaru, který umožňuje uživatelům volně tvořit a upravovat webové stránky pomocí libovolného prohlížeče. Podporuje hyperlinky a, což tyto systémy odlišuje od čehokoliv jiného, disponuje jednoduchou syntaxí pro tvorbu nových stránek a vazeb mezi nimi.
Je opravdu vzrušující a dosud nepříliš běžné povolit návštěvníkům upravit kteroukoliv stránku. Musíte při tom počítat s tím, že občas se objeví nějaký vandal, kterého těší, když může stránku poškodit. Na druhou stranu wiki systémy uchovávají kompletní historii úprav, a správce může stránku kdykoliv vrátit k předchozímu stavu. Wiki znamená pro web skutečnou demokracii a otevřenost a podobně jako je tomu u blogovacích systémů umožňuje i netechnickým uživatelům publikovat. [WIKIDEF]
Neodpustím si poznámku, že jako experiment jsme stránky [OWIKIZF] společnosti, ve které působím jako jednatel postavili právě na jenom takovém systému, konkrétně na MoinMoin.
systémy pro řízení vztahů se zákazníky (CRM)
Customer Relationship Management, jinak též Customer Information Systems, Customer Interaction Software (CIS), Technology Enabled Relationship Manager (TERM).
Aplikace, které pomáhají společnostem spravovat všechny aspekty vztahů se zákazníky. Pomáhají vybudovat trvalé vazby, obrátit zákazníkovu spokojenost v loajalitu. Informace o zákaznících získané z prodejů, marketing, doprovodných služeb a podpory jsou posbírány a uloženy v centrální databázi. Systém může nabízet schopnosti dolování dat, může být také propojený s dalšími systémy, například pro účetní evidenci, výrobu... [FRDICTH]
Nedávno jsem stál před potřebou zvolit kvalitní systém z této kategorie, porovnáním asi dvaceti kritérií jsem z dvaceti vytipovaných projektů nakonec zvolil open source systém OpenCRX. Ten je pozoruhodný mimo jiné svou architekturou – byl vystavěn na platformě OpenMDX pro tvorbu aplikací podle zásad MDA (Model-Driven Architecture). S Davidem Klímou jsme systém lokalizovali do češtiny a p. Klíma zřídil i českou stránku projektu [OPECRXK].
znalostní systémy (KM)
Mnohé podniky neznají, co znají. To vede k duplikaci činností, neefektivním rozhodnutím a ztrátám. Bez ohledu na charakter organizace, efektivní management znalostí se zaměřuje na celý systém: organizaci, lidi a technologie.
Počítače a komunikační prostředky mohou být cennou pomocí při získávání, transformaci, distribuci a používání vysoce strukturovaných znalostí, které se mění každým okamžikem. Dobře implementovaný znalostní systém pomáhá analyzovat, plánovat, mnohdy drasticky zvýšit kvalitu rozhodování, alokace zdrojů, správy systémů, šíření know-how a přístupu k němu a v důsledku celkovou výkonnost. [KMFAQ98][ZTECHMP02]
systémy pro řízení zdrojů (ERP)
Enterprise Eesource Planning je software, který podporuje a automatizuje obchodní procesy, obvykle je dimenzován pro střední a velké podniky. Podporovanými procesy může být výroba, distribuce, řízení lidských zdrojů, řízení projektů, finanční řízení apod. ERP mají silné vazby s účetnictvím, pomáhají plnit požadavky zákazníků a obdržet za to náležitou odměnu. [FRDICTH]
Jsou také nedílnou součástí, možná dokonce jádrem aplikací, které jsou označovány jako podnikové informační systémy.
obchodní dům
To, co se vám vybaví, když se řekne elektronický obchod, e-shop. Virtualizace kamenného obchodu, většinou včetně nezbytných rekvizit, jako nákupní košík nebo pokladna. Typický e-shop slouží koncovému uživateli. Může být specializovaný místně nebo sortimentem, anebo zeširoka pojatý, v tom případě ale bude vyžadovat mnoho úsilí, aby obstál v tvrdém konkurenčním boji.
Pojem to není dokonalý, ale snad trochu vyjadřuje myšlenku, že uživatelé si mohou být vzájemně zákazníkem; stejně tak obchodníkem není jedna firma, ale může jím být každý.
virtuální aukční síň
Každý může vrhnout nějakou věc do veřejné elektronické aukce. Elektronický systém následně umožní ostatním uživatelům přihazovat, důležité jsou také různé prostředky pro ověření důvěryhodnosti účastníků.
Mezinárodně nejúspěšnější je na tomto poli eBay, u nás fungují servery jako aukce.cz a aukro.cz.
inzertní systémy
Každý může nabízet co mu zbývá ve webové obdobě inzertních novin. Oproti novinám přináší elektronický inzertní systém mnohem lepší možnosti vyhledávání, pohodlnější zpětnou vazbu, dostatek prostoru pro obrázky a další informace..
Pokud B2C obchodování přináší úspory a zvyšuje efektivitu, pak v systémech B2B je v tomto směru ještě mnohem vyšší potenciál.
V oblasti B2B je zřejmá tendence k integraci všeho, co se integrovat dá. Formát elektronické výměny dokumentů (EDI) a sama technologie existuje již více než 40 let a jeho popularita (i přes některé problematické pasáže v návrhu dané právě dobou jeho vzniku) postupně spíše roste, protože koneckonců až v nedávné době Internet poskytl skutečně univerzální infrastrukturu pro masově využitelnou vlastní výměnu. Kromě toho je zde množství novějších formátů, které jistě stojí za zmínku, v čele s rodinou jazyků okolo standardu XML. Z nich se velké oblibě těší například SOAP, odlehčený formát pro výměnu informací, za kterým stojí organizace W3C. Zajímavé jsou v této souvislosti také pokroky v oblasti multiagentních systémů. A samozřejmě, kromě standardů existuje mnoho různých proprietárních řešení.
e-marketplace
V principu stále jednoduchá aplikace, podobná aukční síni, s tím rozdílem, že je určena společnostem. Pokud někdo potřebuje nakoupit služby, zařízení, cokoliv, zadá do takového systému poptávku a stanoví kritéria hodnocení. Systém zorganizuje výběrové řízení, jednotliví účastníci zadají nabídky a zadavatel je nakonec s podporou systému vyhodnotí a uzavře obchod s vítězem. Provozovatel tržiště si nechá zaplatit drobnou provizi.
Také stále více veřejných zakázek je realizováno přes taková tržiště – jmenujme třeba centrade.cz nebo allytrade.cz. Organizace a celé řízení je mnohem méně pracné, proces je unifikovaný a transparentnější. V tomto případě můžeme hovořit o B2G.
Takto bychom mohli ještě poměrně dlouho pokračovat. Nezmínili jsme třeba elektronické bankovnictví, podatelny úřadů, meteorologické, geografické a kartografické informační systémy a mnohé další....
A už jsme zase u toho – velké plány, velké změny: Zákazníci, dodavatelé, subdodavatelé, předměty, lidé, aktivity, služby, úlohy, procesy, sklady, značky, data, služby... to vše bude propojeno. Jak konkrétně, to ještě ukáže čas. Každopádně, za nosnou myšlenkou elektronického obchodování platí právě taková integrace.
Modelem silné obchodní korporace elektronického věku nebude velký moloch disponující vším od výroby po distribuci. Myslím, že budoucnost bude patřit spíše malým, dynamickým firmám, které dokáží pospojovat dodavatele pod střechou jedné značky. Taková firma vlastní jen značku (a s ní spojené zákazníky), vše ostatní nakupuje – sklady, služby, zboží, logistiku, servis. [BYZNETH99] Díky své štíhlosti se dokáže mnohem lépe přizpůsobovat extrémně rychlému vývoji internetového světa, než megakorporace staré doby. Stačí jeden příklad za vše: amazon.com. Navenek B2C, ale na pozadí je propracovaný stroj B2B vztahů.
V této oblasti probíhá také intenzivní výzkum. Zajímavý je projekt Process Integration for Electronic Commerce (PIEC), který usiluje o vybudování platformy, nástrojů a technik pro analýzu meziorganizačních procesů a identifikaci a modelování transakčních služeb pro virtuální podniky. PIEC pomáhá při vývoji transakčních služeb, ale také definuje, jak je možné zapojit do celku staré (legacy) informační systémy. Právě to autoři považují za klíčové pro úspěch počátečních fází integrace. [SERVIYHP01]
Jiní autoři posouvají hranice ještě dále. Například autoři [VPRINBD01] chápou virtuální firmy jako dočasné spojení firem za účelem splnění konkrétní zakázky, také označované jako rapid teaming nebo virtual teaming. Takové dynamické obchodování, vedené hrstkou schopných analytiků a manažerů, kteří místo lidí sestaví tým z celých společností. Schopnost formovat, operovat, zrušit virtuální spojení bude klíčová. Takové krátkodobé, příležitostí zřízené společnosti mohou poskytnout stejný potenciál, jako klasické vertikálně integrované korporace, ale flexibilita je mnohem vyšší. Přináší to ale problémy a výzvy jiného druhu – budování důvěry, schopnost spolupráce mezi pracovníky zúčastněných společností, a v neposlední řadě masivní nároky na informační infrastrukturu pro zvládání toků informací, znalostí, zboží, v ideálním případě just-in-time dodávky anebo alespoň tak, aby bylo vyráběno co je třeba, budování optimálních koalic, překonávání obav z případné konkurence současných partnerů...
Nároky na informační systémy na pozadí takového spojení jsou řádově vyšší, než u všech předchozích typů aplikací. Je tady mnoho rozhraní mezi jednotlivými systémy jednotlivých subjektů, je tady potřeba transformovat data, domlouvat se společným jazykem, to všechno rychle, efektivně, spolehlivě – za chyby v kvalitě služeb se na Internetu platí asi ještě více, než kdekoliv jinde, konkurence je totiž neobyčejně ostrá a zákazníci vybíraví...
Svět okolo nás je komplikovaný. Nejsme schopni plně ho popsat, vystihnout skutečnost, vztahy, závislosti. Již jsme ale přišli na spoustu možností, jak tento problém prozatím obejít a alespoň určité aspekty světa nějak formalizovaně popsat – nedokonale, ale aspoň nějak. K tomu slouží rozličné hierarchie (jakákoliv alespoň částečná seřazení) nebo ještě obecněji, konceptuální struktury. [MATHBKS01]
Samotný přirozený jazyk poskytuje různé prostředky konceptualizace.
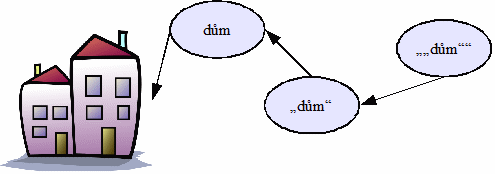
V minulých několika stovkách let jsme vybudovali techniku (efektivní proceduru) psaného slova. Díky ní můžeme jednoduše a automaticky generovat pojmenování jakéhokoliv konceptu. Prehistorické jazyky touto, pro nás možná samozřejmou, technikou nebo technikou ekvivalentní nedisponovaly. Konvencí je, pokud chceme cosi pojmenovat, uzavřeme to do uvozovek. Pokud chceme pojmenovat termín dům, napíšeme „dům“. Tedy například „„dům““ je odkaz na „dům“, a ten je zase odkazem na termín dům, který odkazuje na konkrétní entitu reálného světa. Zde série odkazů končí. Prakticky cokoliv, co se objevuje v řeči nebo jiných konceptuálních strukturách vede k něčemu v reálném světě. Výrazem konceptualizační schopnosti jazyka jsou třeba slovníky.
Když chceme popisovat svět, potřebujeme definice. Zajímavých je např. sedm druhů definic, které zmiňuje Norman Swartz [DEFDICS97]:
smluvní definice
lexikální definice
zpřesňující definice
teoretické definice
operační definice
rekurzivní definice
argumentační definice
Data jsou vždy nějakým odrazem, zachycením reality – data tvoří vlastní meta realitu. Meta data přidávají další rozměr datům, dodatečnou informaci, hodnotu, popisují data, jsou to data o datech. V tomto smyslu bychom ale mohli pokračovat dále – meta meta data, meta meta meta data....
Jak tedy popíšeme svět? Můžeme využít různé informační struktury, například (částečně podle [MATHBKS01]):
množiny, pytle, sekvence, seznamy
funkce, relace
lambda kalkulus
grafy, mříže, stromy, herní grafy
propoziční logika
predikátová logika (first-order)
axiomy, tvrzení, důkazy
formální gramatika
formální specifikace
teorie modelu
teorie množin
stromy, mříže a jiné hierarchie
Petriho sítě, Markovovy řetězce
Za každým uvedeným formalismem je široká teorie, spousta metod, technik, nástrojů...
Z hlediska popisné schopnosti si ze všech těch formalismů zvláštní pozornost zaslouží grafy – koneckonců, od grafů vede k ontologiím poměrně krátká cesta.
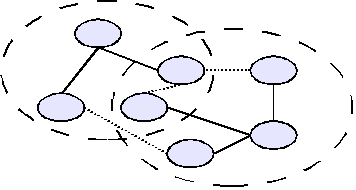
graf
V diagramech je graf znázorněn jako síť uzlů spojených hranami. Konkrétní vizuální reprezentace není důležitá, nezáleží na to, zda jsou hrany krátké, dlouhé, rovné, klikaté, zda jsou uzly malé nebo velké, tečky nebo čtverečky. Jde čistě o existenci vztahu. Proto je grafické znázornění chápáno pouze jako neformální pomůcka pro zvýšení názornosti, vlastní graf je primárně zachycen formálním jazykem.
Následující diagramy tedy znázorňují stejný graf:
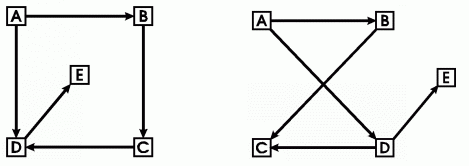
Obecný graf povoluje libovolné počty rodičů a dětí, povoluje rovněž kruhy, jako např. ABCD z příkladu výše. Hierarchie obsahující kruhy je někdy také označovaná jako nestrom nebo „tangled hierarchy“.
Pokud se na graf podíváme z jedné strany, z pohledu jednou uzlu (třeba když si představíme, že za uzel graf pověsíme), můžeme sledovat určitou hierarchii tvořenou rodiči a potomky. Podle povoleného počtu rodičů a možnosti nebo nemožnosti tvořit kruhy můžeme sledovat speciální případy, např:
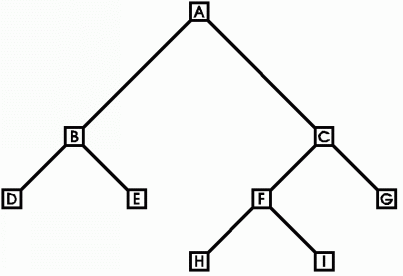
strom
Je graf, který neobsahuje kruhy. Podle počtu rodičů a dětí můžeme rozlišovat různé varianty.
Např. takto vypadá binární strom – každý prvek kromě nejvyššího má právě jednoho rodiče, maximální počet potomků jsou 2 – proto binární:
mříž
Ta vypadá zase třeba takto:
Počítačová podoba sémantických sítí měla původně sloužit umělé inteligenci a strojovému překládání, ale již mnohem dříve byly tyto sítě používány ve filozofii, psychologii a lingvistice. Nejstarší známou sémantickou síť sestavil ve třetím století našeho letopočtu řeckým filosof Poryfyros ve svém komentáři k Aristotelovým kategoriím. Poryfyros ji použil k ilustraci Aristotelovy metody definování kategorií specifikací genu, všeobecného, základního typu a diference, která rozlišuje jeho podtypy [SEMNETS02]. Mimochodem až tak hluboko a možná ještě hlouběji sahají myšlenky dědičnosti používané nejen v definičních sémantických sítích, ontologiích, ale i objektovém programování nebo třeba v relační analýze.
I moderní pojetí sémantických sítí a pojem samotný sahá hluboko do počítačové prehistorie – pojem jako takový můžeme vysledovat až do r. 1968, kdy jej použil Ross Quillian's ve své disertační práci jako způsob uvažování o lidské sémantické paměti (paměti pro slovní koncepty).
Sám pojem sémantické sítě je značně široký:
sémantická síť
O sémantickou síť jde vždy, kdykoliv je informace zachycena v grafu (viz výše), kde uzlům a hranám jsou přiřazeny významy a topologie grafu je důležitá pro tyto významy. [SEMNETG82]
Jedna trochu konkrétnější definice tvrdí, že je to graf, sestávající z uzlů reprezentujících fyzické nebo konceptuální objekty a hran, které popisují vztahy mezi těmito objekty. Používá se mechanismů dědičnosti, čímž je možné vyhnout se potřebám data duplikovat. Smysl konceptů vyplývá vazeb na jiné koncepty a informace je uložena právě a především v podobě těchto typových vazeb.[FRDICTH]
Nejednotnost a vágnost definice je i důvodem, proč žádnou konkrétní neuvádím jako nějaký typický příklad - spíše by zmátla než pomohla.
Všem sémantickým sítím je společná deklarativní grafická reprezentace. Mohou zachycovat znalosti, podporovat automatizované systémy při rozhodování a usuzování. Některé z nich jsou vysoce neformální, jiné naopak velmi formální a precizně definované, pak často slouží jako systémy logiky. John F. Sowa považuje následujících šest typů sémantických sítí za nejdůležitější [SEMNETS02]. U každého typu zrovna uvedeme přibližnou definici či popis.
definiční sítě
Zdůrazňují vztahy dědičnosti reprezentované vazbami „is-a“ (subtyp) mezi koncepty. Výsledná síť je označována jako generalizace nebo zahrnující hierarchie (subsumption hierarchy). Podporuje pravidla dědičnosti pro přenášení vlastností definovaných u nadtypu na podtyp a všechny jeho podtypy. Protože definice jsou pravdivé z definice, informace v těchto sítích je považována (alespoň teoreticky) za nezbytně správnou – mluvíme-li o takové síti, jde vlastně o jednu velkou definici.
prohlašovací sítě
Jsou navrženy k prohlašování tvrzení. Na rozdíl od definičních sítí informace je považována za případně pravdivou, pokud tak není explicitně označena modálním operátorem. Některé prohlašovací sítě byly navrženy jako struktury pro zachycení sémantiky přirozeného jazyka
implikační sítě
Používají implikaci jako primární vztah pro spojování uzlů. Mohou být použity k reprezentaci vzorů myšlenek a představ, příčinnosti nebo k inferencím.
vykonatelné sítě
Zahrnují mechanismy jako předávání značky nebo připojené procedury, které umožňují provádět inference, předávat zprávy nebo hledat vzory a souvislosti.
učící se sítě
Vytvářejí nebo rozšiřují svou reprezentaci získáváním znalostí z příkladů. Nové znalosti mohou změnit starou síť přidáním nebo odstraněním uzlů a vazeb nebo modifikací číselných hodnot, nazývaných váhy, připojených k uzlům a/nebo hranám.
hybridní sítě
Kombinují dvě nebo více předchozích technik, ať již v jedné síti nebo v sítích oddělených, ale silně spolupracujících.
Notace sítí a lineární notace jsou obě schopny vyjádřit stejné informace (jejich vyjadřovací schopnosti jsou ekvivalentní), ale konkrétní reprezentační mechanismy lépe odpovídají jedné nebo druhé formě. Hranice mezi jednotlivými typy sítí jsou značně vágní a co víc, je prakticky nemožné přesně definovat co sémantické sítě jsou, aby definice zahrnula vše, co je do nich obvykle počítáno a naopak vyloučila, co mezi ně počítáno spíše není. Mnoho prací se věnuje takovému rozlišování, případně porovnávání vhodnosti jednotlivých systémů reprezentace informací a znalostí pro konkrétní použití.
Sémantické sítě jsou stále zajímavé i v takové obecné podobě, jak byly původně pojaty. Ovšem čím dál větší pozornost si získává jedna jejich aplikace – ontologie. Ontologie silně vycházejí z toho, co jsme označili jako definiční sítě včetně klíčového mechanismu dědičnosti. Vlastně jsou jejich aplikací a přidávají k nim další rozšíření.
ontologie (technicky)
Množiny definic ve formálním jazyce, založeném na diskrétní matematice a teorii grafů. Zachycují třídy (koncepty), vazby, instance, někdy také axiomy, pravidla a funkce.
Kromě formální podoby je ale zajímavé především použití a i to by mělo být součástí definice. Pojem ontologie nepochází z informatiky - ontologie je původně odvětvím metafyziky a zabývá se podstatou bytí. Počítačové ontologie od toho nejsou daleko.
ontologie (podle použití)
Sdílené konceptualizace konkrétní domény nebo rovnou celého světa.
John Sowa nabízí třeba takovouto, na význam a obsah zaměřenou definici: „Je to takový katalog všeho, co tvoří náš svět a také toho, jak je to vše poskládáno a jak to dohromady funguje.“
Můžeme na ně pohlížet také jako na bohaté a strojově zpracovatelné významové slovníky.
Někdo možná řekne dobrá, ale k čemu to všechno bude? Dotaz je to smysluplný a vyžaduje odpověď.
Když už mluvíme o použití, je třeba mít na paměti, že vždy tady budou působit dvě protichůdné síly – jedna bude usilovat o co nejrychlejší aplikaci v obchodě, průmyslu, školství, kdekoliv. Druhá bude takové snahy brzdit, protože bude zdůrazňovat kvalitu návrhu a z ní plynoucí snadnou správu, rozšiřitelnost a znovupoužitelnost...
Dnes vznikají dva typy ontologií – odlehčené, doménově specifické, navržené pro konkrétní oblasti lidské činnosti – pro zdravotnictví, výrobu, obchod, matematiku, včelařství, .. cokoliv. Tyto samostatné ontologie již dnes pomáhají komunikovat, spolupracovat a zejména integrovat. Díky nim se mohou mnohem lépe domlouvat nezávislé počítačové systémy, lidé, společnosti.
Kromě nich vznikají tzv. top-level ontologie, které mají ambice zmíněné v úvodu – popsat svět. Bdí nad nimi vážená konzorcia napěchovaná odborníky a na jejich tvorbě spolupracují někdy i tisíce lidí – však také obsahují třeba i milióny konceptů. Využívají se všelijak, například v systémech pro práci s přirozeným jazykem. Především do budoucna ale mohou sloužit také jako prostředek pro spojení jednotlivých doménově specifických ontologií, a tak pomoci překlenout další bariéry k ještě širší integraci.
Jsou tady ale různé potíže. Například s tím, že nemyslíme stejně. Použití ontologií je tak omezeno – uživatelé ontologií přemýšlejí jinak než jejich tvůrci, a tak si vzájemně leckdy neporozumí. Například jedna ontologie reprezentuje červenou barvu jako vztah, druhá jako hodnotu. Zvolená reprezentace je v rámci ontologie vždy správná a pravdivá – správná je z definice, protože jde o definici. Ale zda je to pořád ještě ten náš svět, to je mnohem těžší stanovit.
Podle [ONTADGL02] je význam ontologií především takovýto:
pro komunikaci
mezi implementovanými počítačovými systémy
mezi lidmi
mezi lidmi a implementovanými počítačovými systémy
pro automatizované usuzování
pro vnitřní reprezentaci plánů a souvisejících informací
pro analýzu vnitřních struktur, algoritmů, vstupů a výstupů systémů pracujících s teoretickými a konceptuálními významy a pojmy
pro znovupoužití a organizaci znalostí
pro strukturalizaci a organizaci knihoven, repozitářů, datových úložišť a doménových informací
Myslím, že především v praktické části se dotkneme i lecčeho dalšího..
Tyto pojmy si musíme trochu vyjasnit, protože dále s nimi budeme pracovat. Tak tedy
ontologie
Vlastní, konkrétní slovník, obsahuje koncepty, instance, vazby... a popisuje nějakou část našeho světa.
model ontologie
Tvar konkrétní ontologie, nejde nám o detaily.
meta model ontologie
Popisné a inferenční schopnosti modelu. Formální definice toho, co ontologie může obsahovat, co jsou uzly, co vazby, jaké typy vztahů připouští, jak je možné specifikovat pravidla a funkce apod. Ontologie je jedna a má svůj model. Více ontologií ale může být vystavěno podle stejného meta modelu.
Je známou pravdou, že dva lidé jiných profesí si nemusí porozumět, i když hovoří o stejném námětu. Každý totiž používá jiné vyjadřovací prostředky – specifická slova, specificky utvářené věty. Proto se často i definice, metody, techniky... v různých oborech opakují, byť třeba nikdo o souvislostech netuší. Když si nakonec takoví odborníci porozumí, dost možná se budou divit, co vše mají společného a jak hodně si mohou vzájemně prospět.
Podobně, leccos ontologického můžeme pozorovat i jinde. Můžeme třeba hledat podobnosti s jinými formalismy pro zachycení nějaké struktury. Nepůjde o konečný výčet, spíše jen o náznaky...
Podle [DATAONT05] je zde mnoho podobného, například v nabídce konceptuálních prvků, jakými je integrita, taxonomie, pravidla pro odvozování nebo možnost diagramatické reprezentace a testů kvality. Podobné je také to, že v obou případech jde o konceptualizaci reálného světa.
Hlavní rozdíl typického předmětu datového a ontologického modelování je v šíři použití – datový model je vytvářen pro omezené použití v organizaci, která jej vytváří nebo jinde, zatímco ontologie je v principu tvořena pro sdílení a znovupoužití. Tomu odpovídají i odlišné nároky na specifičnost versus univerzalitu. Odlišnosti jsou samozřejmě ve struktuře, způsobu přístupu a metodách tvorby a manipulace. Ontologie je méně účelová a více se zabývá logickými teoriemi platícími v doméně.
Zde bych rád vyzdvihl především podobnosti meta modelů. Třídě objektového návrhu zhruba odpovídá ontologický koncept, instanci entita a rovněž ontologické vazby mají své protějšky v dědičnosti tříd, v asociacích objektů apod.
O objektovém meta modelu lze uvažovat i jako o speciálním druhu meta modelu ontologie. V této souvislosti je zajímavý výzkum v oblastech generování objektového modelu z ontologií a a naopak. Například podle [ONTPADE05] by bylo praktičtější pro objektové modelování používat místo běžných dosti neformálních UML modelů ontologie, především proto, že:
jsou formálnější, a tedy snadněji automatizovatelné
mohou být snadno převedeny do méně formálního popisu (grafické notace) použitím stylu, opačně je to podstatně složitější
není žádný centrální model softwarového designu ani ústřední bod kontroly. Vizí je, že softwaroví inženýři použijí ontologie pro zachycení návrhových vzorů (design patterns) a zveřejní je na webu. S podporou indexačních služeb, jako např. google, budou snadno dohledatelné díky kvalitním meta informacím.
nabízejí možnosti inference
mohou být snadno rozšířeny přidáním dalších konceptů typických pro konkrétní programovací jazyky nebo jejich verze (java asserty, vnitřní třídy, meta tagy) nebo přidáváním AOP konceptů.
tato rozšíření mohou být implementována jako nezávislé zdroje, které mohou být pospojovány dohromady. Výsledkem bude síť návrhových vzorů.
Osobně si myslím, že je to rovněž perspektivní a zajímavá možnost využití ontologií. Vidím zde ještě další souvislosti, především s principy modelem řízené architektury (MDA). Soudím totiž, že ontologie nabízejí dostatek prostředků nejen k popisu návrhových vzorů, ale celých vlastních programů.
Rámce jsou dalším, dosud nezmíněným druhem formalismu.
rámce
Jsou to struktury pro reprezentaci stereotypních situací a odpovídajících stereotypních činností (scénářů). Inspirují se lidskou schopností na základě zkušeností si utvářet rámcové myšlenkové struktury. Rámce se pokoušejí reprezentovat obecné znalosti o třídách objektů, znalosti pravdivé pro většinu případů, tedy počítá se s tím, že mohou existovat objekty, které porušují některé vlastnosti popsané v obecném rámci.
Rámec je tvořen jménem a množinou atributů. Atribut (rubrika, slot) může dále obsahovat položky (links, facets), jako např. aktuální hodnotu (current), implicitní hodnotu (default), rozsah možných hodnot (range). Dalšími položkami slotu mohou být speciální procedury, jako např. if-needed, if-changed, if-added, if-deleted, které jsou automaticky aktivovány, jestliže nastanou příslušné situace.
Mezi rámci mohou existovat vztahy dědičnosti, díky nim lze distribuovat informace bez nutnosti duplikace. Rámec může být specializací jiného obecnějšího rámce (vztah typu specialization-of) a současně může být zobecněním jiných rámců (vztah typu generalization-of). [EXPERTD01] Dědičnost může být u rámců i vícenásobná – jeden rámec je potomkem více jiných.
Rámce jsou preferovaným schématem reprezentace v modelovém a případovém usuzování (model-based reasoning, case-based reasoning). Pro reprezentaci lze použít některý z jazyků jako KRYPTON, FRL nebo KSL.
Rámce se definují třeba tak, jak je uvedeno dále - příklad je inspirovaný [ONTOLED03]. Nedělám si valné iluze o smyslu definovaných rámců, ale i tak bude užitečný. Je z něj zřejmé například to, že nejdříve se obvykle nadefinují typy, a třeba až konkrétní potomek může doplnit konkrétní hodnoty. Nic takového na druhou stranu meta model rámců striktně nevyžaduje.
class-def Keyword
class-def Similarity
slot-constraint keyword1 value-type Keyword
slot-constraint keyword2 value-type Integer
class-def KeywordSimilarity
subclass-of Keyword
subclass-of Similarity
slot-constraint keyword1 has-value BlahBlah
slot-constraint keyword2 has-value 10
Rámce mohou sloužit k popisu prvků ontologie a také se tak občas používají. Uzel v takovém případě bude vlastně rámcem – bude mít sloty, bude zapadat do hierarchie dědičnosti apod.
Ontologické inženýrství zahrnuje podporu v průběhu celého životního cyklu ontologie – v průběhu návrhu, ověřování, validace, správy, nasazení, mapování, integrace, sdílení a znovupoužití. Budování ontologií je náročné, stojí hodně času a je nákladné, zejména pokud je cílem taková ontologie, která umožní provádět automatizované inference.
Jedním z komplikujících faktorů je to, že je třeba získat konsenzus široké komunity, jejíž členové mají radikálně jiné názory a pohledy na věc, na doménu, která je mapována. Konsenzu je dosahováno různě – jedním extrémem jsou malé ontologie tvořené velkou skupinou lidí, jimiž vytvořené kousky se pospojují do výsledné ontologie. Druhým extrémem jsou velké zejména top-level ontologie, jejichž vývoj je obvykle pevně řízen zodpovídajícím konzorciem či standardizační organizací. V prvním případě je klíčová schopnost spojovat, ve druhém efektivně vést tým ke společné práci, navrhovat a analyzovat. [ONTADGL02]
Pro účinný návrh existují metody, techniky a nástroje. Základem je jazyk pro popis ontologie a pomoc v podobě neformálního grafického zobrazení.
formální specifikace ontologie
Obvykle v textové podobě, používá se některý z mnoha jazyků pro popis ontologií. Mezi nejznámější patří DAML+OIL, OWL, RDF a RDFS, Z, KIF (zdá se mi docela přehledný a účelný), RuleML (pro zachycení pravidel v sémantickém webu), CYCL, SUMO a našli bychom i další.
neformální vizualizace
Nástrojem neformální vizualizace ontologie je graf. Tak jak jsme zmiňovali u sémantických sítí, jde pouze o uzly a vazby mezi nimi, tedy o to, zda tam uzel je nebo není a stejně tak zda hrana je a jaké uzly spojuje. Tvar, barva a uspořádání uzlů a hran v ploše není relevantní, to vše by pouze mělo přispívat k přehlednosti. Graf může mít tvar stromu, obvykle jde ale o spletitou (tangled) hierarchii, obsahující kruhy. Význam grafu je v jeho názornosti – z grafu obvykle snadněji pochopíme, co je třeba a stejně tak se nám graficky daří dobře formulovat myšlenky; u strojů je to přesně naopak.
aplikace pro práci s ontologiemi
Existuje mnoho specializovaných nástrojů, které pomáhají tvořit, spravovat i využívat ontologie. Většina z nich podporuje několik formátů, umí generovat grafy, mnohé z nich i prohledávat a třeba provádět i nějaké inference. Většinou jde o samostatné aplikace.
Při svém zkoumání jsem narazil například na tyto nástroje: Protége, DL-workbench, OilEd, Z/EVES, CREAM (anotace textu, zejména webových stránek), OntoWeaver, WebODE, Jena, Dspace, VOM, Kactus. Kromě Protége, který je poměrně známý mě zaujal především aplikační server pro sémantický web nazvaný Kaon [KAEVOH04] univerzity Karlsruhe.
dolování ontologií
Ontologie může být budována výhradně ručně, inženýr vytváří veškeré koncepty a vazby mezi nimi. Může být ale také alespoň z části načerpána (vydolována) z nějaké jiné reprezentace. Existují nástroje na generování ontologií z textu, z databází, z dalších ontologií a z různých kombinací datových zdrojů. Podobně automaticky získaná ontologie ale samozřejmě vyžaduje dodatečnou revizi a validaci.
mapování ontologií
Jde o hledání vazeb mezi ontologií a neontologickými entitami nebo naopak připojování ontologických meta informací datům. Příkladem intenzivního využívání těchto postupů je tvorba tématických map (topic maps).
spojování ontologií (merge)
Výsledkem jsou stále dvě ontologie, ale s definovanými společnými místy a přesahujícími vztahy. Význam má především tam, kde se očekává budoucí rozvoj a údržba spojovaných ontologií.
integrace ontologií
Výsledkem je jedna nová ontologie, která zahrnuje informace z ontologií původních. Jde o nejtěsnější možné spojení. Integrovaná ontologie je již nezávislá na ontologiích původních.
transformace ontologií
Může být přinejmenším dvojího druhu - transformace meziformátová, tedy mezi jazyky pro zachycení ontologií (RDF -> OIL) anebo sémantická, tedy změna vnitřní struktury podle jiného meta modelu nebo pro jiné použití.
evoluce ontologií
Tedy údržba, doplňování nových konceptů, slaďování se současnými poznatky o doméně nebo o ontologiích.
Konkrétních slovníků existuje velké množství, možná tisíce. Několik málo z nich si stručně představíme. Zaměřil jsem se především na dvě skupiny, které v kontextu práce považuji za významné - na top-level ontologie a ontologie pro podniky a obchod.
WordNet
WordNet je online lexikální referenční systém, inspirovaný současnými psycholingvistickými teoriemi lidské lexikální paměti.
Anglická podstatná jména, slovesa, přídavná jména a příslovce jsou zorganizovány do systémů množin, kde každá reprezentuje příslušný lexikální koncept. Mezi koncepty jsou různé vazby, například jsou takto zachycena synonyma. [WORDNET]
Pro práci s ontologií je možné použít webové rozhraní nebo speciální klientský program.
Cyc
Znalostní server Cyc je velmi rozsáhlá multikontextová znalostní báze a inferenční stroj vyvinutý společností Cycorp [CYCORP].
Jejím cílem je překonat slabá místa současných aplikací jednou provždy vytvořením základny všeobecného poznání – sémantického substrátu termínů, pravidel a vztahů, které umožní vytvářet širokou paletu znalostně orientovaných produktů a služeb. Cyc se snaží nabídnout hlubokou úroveň porozumění, které přinese programům nebývalou flexibilitu.
Hlavním výsledkem jejich snažení je, jak jinak, obsáhlá a univerzální ontologie. Autory deklarované příklady možného použití jsou docela inspirativní, lze je chápat i jako obecně široké možnosti top-level ontologií, proto si je zde vyjmenujeme; posbíral jsem je z více míst na jejich webu:
porozumění textu a příprava dokumentů
porozumění řeči
inteligentní strojový překlad
generování textu
expertní systémy
tréningové simulace
umělá inteligence her
online komerce
online poradenské služby
cílený marketing
čištění a integrace databází
čištění a integrace tabulek (spreadsheets)
aktivní menu a formuláře
praktická encyklopedie
odpovídání na otázky
vyhledávání dokumentů a fotografií
distribuovaná umělá inteligence
zprostředkování prodeje zboží a služeb
chytrá rozhraní
inteligentní simulace pro hry
bohatá virtuální realita
sémantické dolování
inteligentní agent – osobní poradce pro nakupování
Inspirativní je i architektura systému:
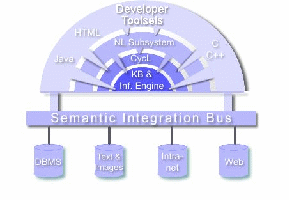
Existuje i open source verze Cyc ontologie a nástrojů pro práci s ní [OPENCYC].
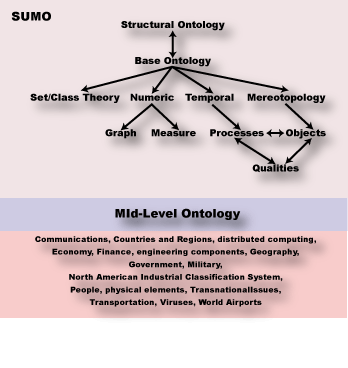
SUMO
SUMO, MILO (MId-Level Ontology) a související doménové ontologie společně tvoří největší současnou formální veřejně dostupnou ontologii, dohromady obsahují 20000 konceptů a 60000 axiomů.
Ano, není to pouhá taxonomie, ale je bohatě axiomatizovaná. Všechny koncepty jsou formálně definované ve vlastním jazyce SUO-KIF. Významy nejsou závislé na konkrétní implementaci inferenčního mechanismu, ovšem systém pro inference a správu ontologie je k dispozici. K dispozici je také grafický nástroj KSMSA pro pohodlné prohlížení a editaci. [SUMONP01]
Toto jsou současné doménové ontologie a je pozoruhodné, o jak odlišné domény jde:
komunikace
země a regiony
distribuované výpočetní systémy
ekonomie
finance
inženýrské komponenty
 geografie
geografie
vláda
vojenství
severoamerický klasifikační systém průmyslu
lidé
fyzické elementy
mezinárodní otázky
doprava
viry
světová letiště
terorismus
zbraně hromadného ničení
Na rodině SUMO je založena spousta výzkumných projektů i funkčních aplikací z oblastí prohledávání, lingvistiky a usuzování. SUMO je také jedinou formální ontologií, která je plně namapovaná na lexikon WordNet zmíněný výše. Vlastníkem je IEEE, konzorcium ji vyvíjelo pro svobodné použití. Rozšiřující ontologie jsou zveřejněny pod GNU General Public License.
Bez povšimnutí nelze nechat také to, že SUMO disponuje šablonami pro generování jazyka; podporována je angličtina, němčina, italština, čínština, hindština a (což nás především těší) čeština.
Dolce
Popisná ontologie pro lingvistiku a kognitivní inženýrství.
OntoMap
Portál pro ověřování a porovnávání upper-level ontologií a lexikálních znalostních bází.
OntoKhoj
Portál pro ontologické inženýrství.
KSL provádí výzkum v oblastech reprezentace znalostí a automatizovaného usuzování, za projektem stojí Stanfordská univerzita. Současné práce se zaměřují na sémantický web, hybridní usuzování, vysvětlování odpovědí z heterogenních aplikací, deduktivní odpovídání na otázky, reprezentace usuzování ve více kontextech, agregace znalostí, ontologické inženýrství a znalostní technologie pro analytiky. [KSLSTANF]
Kromě jiného je na serveru projektu k dispozici několik jednoduchých, ale zajímavých ontologií. Pro použití v obchodu jsou použitelné především dvě z nich:
Product-ontology
Component-Assemblies
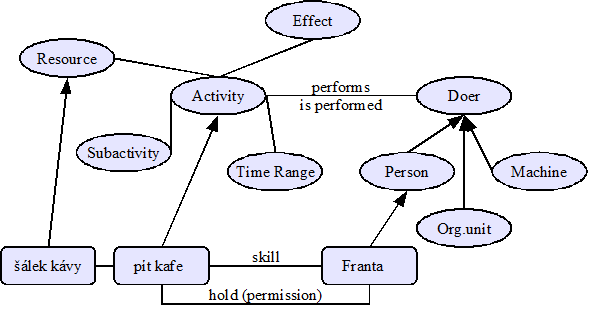
Projekt štědře financovaný britskou vládou, cílem je propagovat používání znalostních systémů v modelování obchodních aplikací, cílem je pomoci organizacím zvládat management změny. Ontologie, která je součástí projektu má být schopna popsat různé aspekty toho, jak komerční organizace funguje a jak je řízena. Smyslem je reprezentovat organizaci v takové podobě, která může být použita jako základ pro rozhodování. [AIAI]
Pročetl jsem si různé materiály o této ontologii a na jejich základě jsem sestavil jednoduchý neformální diagram některých ústředních konceptů (aktivity, aktéři, čas, cíle, zdroje, prodeje) vč. příkladů instancí, který pomůže získat přehled o tom, co konkrétně ontologie řeší:
Open source integrovaný informační model pro spojení informačních technologií s prostředím obchodu. Zabývá se návrhem obchodních procesů, správou a řízením projektů, řízením požadavků, řízením obchodní výkonnosti (v podobě vyrovnaných výsledkových listů).
Vytváří základ pro integrovanou, nezávislou znalostní bázi řízení podniku, ze které mohou být generovány rozličné artefakty. Ontologie je určena především pro obchodní analytiky, může posloužit i IT expertům jako základ pro spojení definic specifických pro IT (software, web...) a konceptů obchodních. [BUSMANONT]
Ontologie působí přehledně, jako nejpoužitelnější mi připadá ta část, která se zabývá definicí procesů. Má také modulární a rozšiřitelnou architekturu. Důsledně rozlišuje koncepty, těm říká „entity“ (např. „zákazník“, „dodavatel“) a instance, kterým říká pro změnu objekty („zákazník Franta“).
Na stránkách projektu je pěkně ilustrovaná myšlenka využití ontologie jako centrálního repozitáře pro návrh programu s možností generovat jiné reprezentace:
Již jsme se lehce zabývali tím, jak Internet změnil zaběhnuté pořádky. Že přinesl mnohem větší změnu, než třeba telefon, že má potenciál nahradit nejen telefon, částečně poštu, ale také televizi, rozhlas, knihovny, banky, podatelny úřadů a částečně možná i úřady samotné...
Internet poskytuje především technickou infrastrukturu, propojuje celý svět. Jeho obsah ne nesmírně rozsáhlý, ale také silně decentralizovaný. To je jistě výhoda – přináší odolnost, umožňuje aplikovat principy volného trhu – můžeme říct, že neviditelná ruka Internetu určuje, který projekt má smysl a který nikoliv.
V současné době můžeme pozorovat postupný posun těžiště významu od typických desktopových aplikací k aplikacím webovým. Zatím nikoliv ve všech oborech a typech aplikací, ale především tam, kde klíčovou roli hraje komunikace a sdílení je tento trend zřejmý – podnikové informační systémy, systémy vládních a samosprávných úřadů, groupware, CRM, ale také počítačové hry a multimediální zábava.
Tuším, že je jen otázkou času, kdy podobný vývoj bude čekat i další aplikace – především ty, kde opět jde především o spolupráci, tedy např. systémy CAD/CAM, vývojová prostředí pro budování softwaru, možná i ty kancelářské balíky, které dnes považujeme za typicky desktopové. Brzdou pro takové pojetí dosud byla rigidita tvůrců těchto systémů (ta zmizí nebo zmizí oni), ale také nedostatečné technické parametry sítí s Internetem v čele (rychlost, spolehlivost, bezpečnost) a jejich nedostatečná rozšířenost.
Internet již dnes poskytuje ohromující výpočetní výkon. Z jednotlivých počítačů lze sestavit výpočetní klastry nebo gridy, kterým se především na poli úloh, které lze rozdělit a paralelizovat žádné sebedokonalejší superpočítače nemohou rovnat – viz SETI@home nebo novější a zajímavější iniciativy COINC, například pro predikce vývoje klimatu [CPREDICT].
Většina prostředků Internetu slouží lidem, tedy přímo lidem. Obrovský a z větší části stále ještě z větší části nevyužitý potenciál je naopak v autonomní komunikaci mezi počítači, jednotlivými systémy. Takovou spoluprací by mohly vznikat další hodnoty – pro lidi.
Svoboda a decentralizovanost také vede k tomu, že nikoliv vždy se podaří nalézt přesně tu službu či produkt, která by vyhovovala nejvíce. Značnou moc získávají služby, které přinášejí určitou centralizaci a tak vnášejí do živelného prostředí řád – velké portály s diskuzními skupinami, zpravodajstvím, obrovské elektronické obchody (amazon.com)... a zejména indexační a prohledávací servery s Googlem v čele.
Taková centralizace přináší nebezpečí – například vyhledávací portál může značným způsobem ovlivňovat, které projekty budou úspěšné a které nikoliv. Stačí, když do vedení takové společnosti pronikne někdo se záměrem prosadit své myšlenky, politické cíle, názory. S růstem významu Internetu rostou i taková nebezpečí.
Je vůbec nějaká alternativa? Je možné vnést řád do aplikací a služeb nekoordinovaně vznikajících, bouřlivě se rozvíjejících a nečekaně končících? Je možné propojit Internet na úrovni obsahu a významu zdola, bez nezbytné asistence mocných společností nebo alespoň s omezením jejich moci? Je možné efektivně spolupracovat na velkých, výpočetně náročných projektech?
Myslím že ano. Jak již asi tušíte, myslím, a že cesta vede přes masivní nasazení ontologií. Ontologie samy o sobě nabízejí prostředky poznání, porozumění a pochopení, umožňují propojit odlišné myšlenkové mapy, subjekty působící ve stejných i jiných konceptuálních doménách, lidi a stroje. Internet k tomu nabízí infrastrukturu. Spojením vznikne nová kvalita.
Při vývoji ontologického systému potřebujeme budeme potřebovat široký rozhled - usilujeme přeci o univerzálnost. Proto se nyní zamyslíme nad obecnými efekty spojení ontologií a webu, nad sémantickým webem a také nad přínosy pro jednotlivé obory lidské činnosti a pro architektury aplikaci pracujících v síťovém prostředí. Jako v celé práci, nepůjde nám o vyčerpávající přehled, ale o náznaky a ukázku směrů.
popis
Ontologie dokáží velmi kvalitně a precizně popsat problém, situaci, produkt, službu nebo obecně cokoliv. Popis je vysoce strukturovaný, a tedy mnohem snáze uchopitelný, strojově zpracovatelný.
souvislosti
Součástí kvalitního popisu mohou být souvislosti s dalšími koncepty. Vztahy mohou být na rozdíl od klasických hyperlinků typové a mohou být jednosměrné i obousměrné. Jednotným způsobem je možné zachytit alternativy, doplňující informace, výhody, použité technologie, příklady použití, varianty..
porovnávání
Ontologie je prostředkem domluvy. Překlene tak bariéry dané rozdílným jazykem, rozdílným způsobem vyjadřování, rozdílné jednotky, způsoby reprezentace. Umožní uživateli mnohem snáze a z velké části automatizovaně porovnávat – produkty, jejich vlastnosti, ceny..., postupy, technologie, definice... a leccos dalšího.
ovladatelnost a prohledávání
Určitým rysem dnešní doby je informační zahlcení, plodící v lidech informační úzkost až averzi k informacím či apatii. Pokud potřebujete konkrétní jednoduchou informaci, vyhledávač vám nabídne několik miliónů možností. Je pravda, že výsledky jsou seřazeny podle významu a relevance, ale je to pořád nedostatečné. Pokud chcete mít alespoň nějakou jistotu, že nalezená informace je opravdu ta, kterou hledáte a ta nejlepší možná z nich, možná musíte projít spoustu z nich. To vás stojí čas a úsilí. S daty obohacenými o ontologií zachycenou sémantiku by bylo mnohem snazší automatizovaně posuzovat relevanci.
clustering
Jednoduché fulltextové hledání dnes již nestačí. Je třeba nabídnout prostředky třídění a organizace výsledků do smysluplných kategorií, které umožně uživatelům načerpat mnohem více znalostí a vhledu do problému. Díky kategorizaci výsledků si snadněji vyberou, kterým směrem dál zaměřit pozornost.
Příkladem poměrně úspěšného nástroje, který něco takového provádí s klasickým webem je Vivísimo. Technika, která běhá v pozadí dokáže kategorizovat velké objemy dat bez komplikovaného zpracování konkrétních dokumentů. Vystačí si i bez nějaké speciální taxonomie (bavme se zrovna o ontologii), ale s ní funguje ještě podstatně lépe. Dramaticky by se účinnost této metody zvýšila, kdyby byly dokumenty explicitně doplněny alespoň o základní vazby s ontologickými koncepty. [VIVISTAXO]
agragace, integrace, unifikace
Podniky a instituce jsou prostoupené informacemi ve všemožné podobě, struktuře a kvalitě.. Ontologie by mohly být prostředkem propojení a následné unifikace takových heterogenních zdrojů.
Databáze které obsahují cenná data a již dnes jsou cenným aktivem by mohly sloužit ještě mnohem lépe v integrovaném celku. Ontologie by se staly jádrem informačního systému, prostředkem pro kompozici nezávislých webových služeb, ale také pro spojování nejen v rámci organizace ale i mezi organizacemi – to jsme ale již párkrát zmínili.
snížení redundance
Redundance zvyšuje náklady - znovu a znovu jsou vytvářeny, shromažďovány, zpracovávány, ověřovány, porovnávány informace již mnohokrát předtím vytvořené, shromážděné, zpracované... Kromě toho, redundance vede k nekonzistenci, když si duplikovaná data vzájemně protiřečí. S použitím ontologií by mohla být data by místo duplikace sdílena, a tak by redundance i nekonzistence mohla klesnout anebo by se alespoň stala lépe kontrolovatelnou.
znovupoužití
Konceptualizovaná data by bylo mnohem snadnější použít, a to nejen jednou a jednoúčelově, ale mnohokrát a i doposud netušenými způsoby.
propojení
Ontologie by mohly vytvořit komunikační platformu pro spojení lidí vzájemně, lidí a technologií, technologií mezi sebou. Rozdíly mezi výsledky práce lidí a strojů by se mohly postupně stírat.
Pokud vám například robot v centru technické podpory dobře porozumí a přesně a sofistikovaně poradí, je vám koneckonců jedno, že je to robot a nikoliv operátor z masa a kostí.
S podporou ontologických technologií by mohlo nastat mnohem těsnější propojení informací a procesů reálného světa a informací a procesů v elektronickém prostředí.
Překlenuly by se různé bariéry dané třeba nekompatibilními jazyky (mnohojazyčná ontologie). Otevírají se také možnosti automatického přizpůsobování nejen vzhledu, ale i obsahu webu hendikepovaným osobám.
sdílení
Čím dál více popularity si získává architektura P2P systémů – koneckonců nabízí úplnou decentralizaci tak, jak to bylo původním záměrem tvůrců Internetu. Mnoho z nich slouží především sdílení dat – nejčastěji hudby, filmů, dokumentů, programů.
Mám na mysli obecné systémy jako Direct Connect, eDonkey, ale také BitTorrent nebo specializované, jako třeba SoulSeek.
Většina systémů umožňuje vyhledávat podle omezené množiny charakteristik dat – nejběžnější je hledání podle názvu souboru. Všechny tyto systémy by mohly postoupit na kvalitativně vyšší úroveň, kdyby umožnily uživatelům popsat a sdílet (ať je to zajímavější, vytvořme nový veselý termín D&S, describe & share) svá data pomocí ontologie. S využitím ontologie by šlo hledat data podle mnoha charakteristik, šlo by ale rovněž snadno a efektivně objevovat třeba uživatele se společnými zájmy.
Myslím, že k podrobnostem se dostaneme ještě v případové studii o popisu a organizaci dat a také v samotném závěru práce, která bude věnována architektuře ontologických systémů.
Kromě sdílení dat existují i zajímavé projekty sdílení meta dat v rámci komunity. Za zmínku stojí třeba různé projekty sdílení a znovupoužití odkazů na zajímavé informační zdroje, někdy spojené s hodnocením a kategorizací. [STUMBLEUP]
spolupráce
P2P systémy ale nelze chápat pouze jako nástroje sdílení dat. Cítit jsou tendence zapojit uživatele do tvorby obsahu a hodnoty, chápat je nikoliv pouze jako prosté konzumenty, ale jako spolupracovníky.
Ať doplňují ontologii, ať popisují informace meta informacemi z ontologií, ať se cítí jako součást celku, ať v to všem vidí možnost seberealizace. Budou z toho mít radost a my získáme zpětnou vazbu, vytvoříme komunitu a v neposlední řadě dostaneme více či méně kvalitní obsah prakticky zadarmo.
Inspirací mohou být internetové komunity, především okolo open source projektů nebo různých jiných svobodných forem spolupráce – například budování svobodných sítí [CRFREENET].
Sémantický web spojuje zdroje informací do podoby znalostí. Umožňuje tak provoz inteligentních služeb, jako již zmíněný clustering nebo masivní personalizace. Pomáhá uživatelům ve správném uchopení a použití webu.
automatizace
Představme si web, který anotuje a popisuje sám sebe – i to mohou systémy postavené na ontologiích nabídnout. Úspěch sémantického webu totiž závisí na dostupnosti ontologií a také na proliferaci webových stránek anotovaných metadaty odpovídajícími ontologiím. Klíčovou otázkou je, kde vzít tato metadata.
V tomto směru se rýsují slibné cesty – například v práci [ANOTCHS04] je představen systém pro automatizovaný proces kategorizace instancí na základě technik rozpoznávání vzorů, automatizovaný do té míry, že nepotřebuje žádný dohled. Výsledky systému jsou ověřovány a porovnávány s anotacemi vytvořenými lidmi.
Směry dalšího výzkumu jsou například:
sémantický hypertext, konceptuální spojování, vypočítatelná hypertextová struktura (metahypertext)
hromadná a automatizovaná kategorizace webu
katalogizace služeb na webu
generování webu ze znalostí (ontologií)
sémantické dolování (semantic web mining)
agregace
Informační portály či informační služby agregující mnoho zdrojů přidávají novou hodnotu tím že agregovaná data třídí, hodnotí, porovnávají, zajišťují jednotné a přehledné rozhraní.. Ontologie by mohly jejich schopnosti podstatně zvýšit – podle ontologických metadat by mohly být agregovatelné služby vyhledávány, zařazovány do kategorií, podle kterých by si zase jednotliví uživatelé mohli vybírat, co je zajímá. To vše mnohem přesněji, precizněji, s vyšší relevancí.
spravovatelnost, trvalá hodnota
Klíčem k vyšší dynamičnosti, snadnější spravovatelnosti a vyšší automatizovatelnosti je kromě jiného důsledné oddělení obsahu od formy, proces někdy nazývaný sémantizace, tedy konkrétně rozlišení
vzhledu
obsahu
významu
logiky
Díky tomu bude snadné stejnou myšlenku prezentovat mnoha formami, vzhled měnit podle aktuálních potřeb nebo přání uživatelů. Díky oddělení a kvalitnímu zachycení logiky se nestane například, že zastaráním nějaké publikace budou zapomenuty i její stále platné nosné myšlenky.
navigace
Ontologie mohou nabídnout nové možnosti navigace. Můžeme zvažovat různé úrovně ontologické podpory navigace – navigace ontologií podporovaná, na ontologii založená anebo ontologií řízená.
Například ontologií podporovaná navigace může vypadat takto [ONNAVCR00]:
Systém načte profil uživatele – ten obsahuje cíle a omezení.
Automaticky vygeneruje vážené sémantické odkazy mezi dokumenty.
Vazbám dodá role, významy (půjde o typové vztahy). Při tom bude brát v úvahu profil a doménovou ontologii a ontologii diskuze a vyjednávání.
Mezi množstvím odkazů vybere nejrelevantnější vůči kontextu a záměrům uživatele.
Poskládá zdroje s využitím vhodných pedagogických a vypravěčských strategií.
Výpočty provádí v souladu s omezeními časovými a jinými ekonomickými, jak jsou stanoveny v profilu.
hledání
Přínos ontologií je zřejmý, již jsme jej zmiňovali – s jejich použitím vzroste výkonnost a přesnost. Ontologie mohou být použity pro anotaci dokumentů, ale i pro specifikaci dotazů. Pomocí může být i personalizovaný informační asistent jako samostatný program, nejspíše s architekturou inteligentního agenta – o které se ještě zmíníme v závěru.
S podporou ontologií bude snadnější ohodnocovat zdroje, posuzovat jejich kvalitu a relevanci.
objevování (semantic discovery)
Budou-li služby vhodně popsány ontologiemi, silně to napomůže jejich dynamickému objevování a zařazování do kontextů a větších celků.
V této souvislosti jsou zajímavé rovněž principy a důsledky SaaS, jak budou rozebírány ještě v závěru práce.
setkávání (matching)
Snáze se setká poptávka a relevantní nabídka, požadavek a řešení, agent a služba.
V této části se především zamyslíme nad tím, jaké typy dat mohou být obohaceny ontologiemi.
přirozený jazyk
Jednou z hlavních aplikací ontologií je právě reprezentace, přenos a sdílení jazykových konstrukcí, vazeb a významů. Obor, který se tím zabývá se nazývá ontologická sémantika. Cílem je pomoci strojům „pochopit“ text, hledat vazby mezi různými jazyky, což může být základem kvalitních překladových nástrojů, výkladových slovníků apod.
text
Mohli bychom ještě mluvit o extrakci významu z textu, dolování pravidel, hodnocení novosti..
spotřební elektronika
Především výrobci spotřební elektroniky (Sony..) se předhánějí ve zveřejňování vizí, kde spotřebiče budou vzájemně komunikovat a komunikovat s lidmi a počítačovými systémy. Myslím si, že pokud má podobný systém vůbec fungovat, bez značné dávky umělé inteligence se neobejde – alespoň zatím. Ale pravděpodobně i do budoucna nelze očekávat od většiny populace, že se sníží na dostatečně technologickou úroveň, aby se s takovými stroji a přístroji bavila „v jejich jazyce“. Především formální jednoduché ontologie mohou být klíčovým pomocníkem vzájemnému porozumění i v této oblasti.
Viz v textu roztroušené poznámky o informační úzkosti, informačním opaření apod.
procesy
Ontologie jsou často využívány pro modelování, dekompozici, restrukturalizaci a simulaci procesů.
toky dokumentů
Systémy pro správu dokumentů a řízení workflow (mimochodem stále častěji realizované v architektuře webových služeb) mohou rovněž díky ontologiím nabídnout vyšší komfort – lepší možnosti kategorizace, perzonalizace apod.
streamovaná multimédia
Množství takového obsahu na Internetu silně roste. Nemyslím si, že by měla být multimédia reprezentována ontologiemi, ale ontologické anotace (metadata) by usnadnily setkání uživatelů, kteří požadují nějaký obsah a poskytovatelů, kteří jej nabízejí.
multimédia obecně
Mnoho multimédií je v současné době anotováno primitivními prostředky – příkladem mohou být ID3 tagy MP3 dokumentů nebo údaje uváděné v AVI obálce. Ontologická kategorizace by prospěla každému druhu médií a multimédií. Snadnější správa, vyhledávání, organizace, sdílení... vše o čem jsme již mluvili zde platí na sto procent.
práva a oprávnění
Pro zachycení práv a oprávnění v síťovém prostředí jsou nejčastěji používány stromové LDAP databáze nebo jejich obdoba.
Například Active Directory ve Windows nebo třeba Netware NDS, eDirectory...
Podoba mezi strukturou těchto dat a ontologiemi je zřejmá. Reprezentace v podobě ontologií by ještě více usnadnila napojení na další systémy. Pomohla by také při kooperaci subjektů (viz virtuální firma), jinak bolestivé a nákladné integraci (při fůzích a akvizicích), případně transformaci (při změnách v procesech, rolích, kompetencích, zejména jako součást reinženýringu).
plánování a správa síťové infrastruktury
Pokud by byly uzly síťové infrastruktury popsány jako koncepty ontologií, usnadnilo by to plánování a optimalizaci infrastruktury.
Síťové prostředky jsou obvykle spravovány s použitím standardních protokolů (zejména SNMP) a odpovídajících nástrojů. Ontologické systémy pro správu sítě by mohly pro vyšší pohodlí správců taktéž generovat SMTP zprávy.
Zajímavá je myšlenka inteligentních agentů, kteří by putovali počítačovou sítí, hledali by vadná a špatně fungující místa, chyby by sami napravovali, případně hlásili nadřazeným autoritám. Určitě by jim pomohlo, kdyby jednotlivé prvky infrastruktury byly anotovány vhodnou ontologií – agenti by pak mohli snáze učit smysl a význam prvků, spojů, tras, procházejících dat apod.
Webové služby, podnikové informační systémy, P2P – o tom všem jsme již mluvili. Zmíníme proto jen pár zajímavějších a méně běžných..
weboví agenti
Pan Bell navrhl v práci [AGENTRB95] univerzální architekturu inteligentního agenta, vhodného zejména pro práci v prostředí webu. Architektura je tak obecná, že je prakticky jedno, v jaké oborové doméně agent pracuje – jeho jádro je stabilní a jediné, co je závislé na konkrétní doméně a použití jsou senzory a efektory.
Takoví agenti by mohli provádět cokoliv – hledat novinky v oboru, posuzovat aktivity konkurence, sledovat vývoj veřejného mínění, sloužit jako mnohem inteligentnější obdoba botů (indexačních agentů) nebo třeba fungovat jako osobní rádce.
adaptivní systémy
Nejde nikoliv o konkrétní architekturu, spíše o konkrétní výraznou nebo dokonce klíčovou charakteristiku. Jsou to systémy, které reflektují změny v prostředí – např. ve vysoké peci, nebo třeba v legislativě a dynamicky přizpůsobují své chování, případně se učí z důsledků svých minulých akcí. Myslím že takový umělý právní nebo účetní poradce by vůbec nebyl k zahození...
Současný web je pro takové systémy docela velkým oříškem – těžko mu porozumí, je vytvářený především pro lidi. V sémantickém webu by se ale cítili jako doma – ontologie by sloužila jako slovník.
znalostní systémy
Velká kategorie programů pro zachycení, manipulaci, sdílení a využívání znalostí a „korporátních vzpomínek“. Ontologie jsou nedílnou součástí nebo dokonce jádrem mnoha z nich. Stále běžnější jsou tyto systémy jako nástroj znalostního managementu ve velkých společnostech.
Myslím že je zde ale ještě velký potenciál, především v oblastech, které jsou těmito technologiemi zatím ještě nedotčené. Velmi by pomohly například komunitám okolo různých svobodných a neziskových projektů – open source programů, svobodně budovaných a využívaných sítí [CRFREENET]. Přílišná roztroušenost a nízká centralizace vede k tomu, že mnoho cenných znalostí je zachyceno jen v podobě diskuzí a fór, oficiální dokumentace bývá spíše podružná, leckdy neaktuální nebo neúplná. Znalostním systémem by možná nepohrdly ani různé další spolky a zájmové skupiny.
O mnoha souvisejících věcech jsme již mluvili v jiném kontextu, tak jen stručně..
Podle [VALPRBM00] je pro úspěšné elektronické obchodování nezbytné řídit se pěti pravidly:
Jedinou možností je dát zákazníkům na výběr, ale chytřeji než dosud – dostatečná volnost, ale nikoliv přesycení; výběr z možností, které jsou specificky uzpůsobené podle profilu...
Rychlejší je lepší, zákazníci platí za rychlost
Uděláte dobře, pokud nebudete dělat všechno
Zacházejte s partnery jako s partnery
Poznejte, co zákazníci potřebují aneb super služby a perfektní objednávky
Co pomůže naplnit tyto cíle? Například kvalitní popis produktů a nabízených služeb, sběr a analýza informací o zákaznících, unikátní zacházení s každým zákazníkem jednotlivě, sběr a analýza informací o konkurenci, propojení systémů subdodavatelů, zvládnutá logistika a řízení zásob... V tom všem pomohou ontologie.
B2C se sériovým zbožím
Myslím že význam ontologií je zřejmý u klasických obchodů s běžným zbožím – pro snadnější hledání, porovnávání, efektivnější transakce... o tom všem jsme již mluvili.
B2C a C2C se specifickým zbožím
Řekl bych ale, že ještě větším přínosem by byly ontologie obchodům se zbožím specifickým, kde každý kus je originál. U takových obchodů jde především o matching, setkání konkrétní poptávky s konkrétní nabídkou. Mám na mysli umělecké nebo umělecko-řemeslné produkty, ale především širokou oblast obchodů s použitým zbožím - starožitnosti, bazary, autobazary, vrakoviště, antikvariáty, burzy sběratelských předmětů – známek, pohlednic, mincí, pohledů....
Ve všech těchto případech je zákazník ochoten zaplatit i relativně hodně, pokud najde přesně to, co hledá. Na tom ovšem často vše ztroskotá – jak má sběratel zjistit, že konkrétní známka, kniha, komoda, nedostatkový náhradní díl..., kterou/který usilovně shání leží na zaprášené polici v zapadlém podniku v nějakém okresním městečku na druhém konci republiky?
Ontologický systém, který by umožnil anotovat prodávané zboží a následně propojil (integrace nebo brokering) zmíněné podniky, by přinesl značný užitek všem zúčastněným.
B2B a B2G
O tom jsme již také mluvili, snad jen zopakuji klíčové pojmy - integrace partnerů pomocí ontologického modelu, virtuální firmy, automatizace procesů, reprezentace kontraktů s důrazem na řešení neobvyklých situací, ontologie pro B2B tržiště, integrace katalogů, alokace zdrojů a řízení zásob...
Zatím jsme se zajímali především o aplikaci v komerčních oblastech; možnosti použití ontologií a sémantického webu je ale široce přesahují, zasahují do snad všech oblastní lidské činnosti. Jen pár příkladů:
knihovny, muzea
Představme si digitální knihovny s plnými texty miliónů publikací, důsledně anotované podle vhodných ontologií, digitální muzea s obrazovým, zvukovým i multimediálním obsahem, opět důsledně anotované. Když to spojíme s možnostmi techniky blízké budoucnosti – mám na mysli extrémně ohebné displeje s vysokým kontrastem a minimální spotřebou nebo věrnou 3D vizualizaci – potřebujeme ještě vůbec jejich kamenné podoby?
mapy, GIS..
Vezměme si nějakou digitální mapu (třeba InfoMapu od PJSoft). Představme si, že by údaje o objektech na mapě byly popsány vhodnou ontologií. Jak snadno by se nám pak v takové mapě hledalo... A co víc, ontologický systém by mohl automatizovaně dohledávat souvislosti s dalšími externím datovými zdroji – recenzemi, turistickými průvodci, prezentacemi ubytovacích zařízení, kulturních památek.. Mohl by doplňovat provozní doby čerpacích stanic, doporučovat trasy podle mnoha kritérií..
archivy
Možnosti využití ontologií jsou zde nebývalé. Prakticky celé archivní fondy (matriky, historické záznamy, výroční zprávy) by mohly být přinejmenším ontologicky anotovány nebo přímo do podoby ontologie převedeny.
Třeba sestavení rodokmenu (které dnes znamená usilovnou, mravenčí, skoro detektivní práci) by bylo otázkou několika kliknutí myší..
státní správa, místní samospráva..
Ontologie vlády, správních úřadů, místní samosprávy – interoperabilita, efektivní komunikace:
vertikálně i horizontálně mezi jednotlivými úřady - sdílení informací, snížení redundance, úspory stohů papíru, pracovních nákladů úředníků i občanů...; nadřízené úřady by mohly snáze hledat a vyhodnocovat nejen chyby, ale i rizika a hrozby; například policie jednotlivých států a bezpečnostní a zpravodajské služby by mohly spolupracovat a sdílet konceptualizovaná data pro vyhledávání hrozeb, pátrání po nebezpečných osobách, sledování transportů zbraní, drog, chráněných zvířat a rostlin...
mezi úřady a občany – občan by již nebyl horkým bramborem, který si jednotliví úředníci přehazují tak dlouho, dokud nevychladne a nepřestane ho to bavit; každý úředník by díky znalostnímu systému postavenému na ontologii věděl vše – úředník katastrálního úřadu o daních z převodu nemovitosti, finanční úředník o sociálních dávkách..
e-Learning
Význam ontologií pro e-learning je myslím rovněž zřejmý...
Jak vyplývá z teoretické části, možností použití ontologií ve webových aplikacích je nepřeberně. Tuto rozmanitost budu mít na paměti při analýze požadavků vyvíjeného systému. Smyslem práce není detailně zkoumat každé možné použití, pokusím se ale vybrat několik reprezentativních možností, kterým se budu věnovat více a ze kterých především následně odvodím požadavky na systém. Nezapomenu ani na důležitou schopnost ontologií, totiž jejich již několikrát zmiňovaný integrační potenciál. V rámci navazujícího návrhu budu upírat pozornost především k použitím podle případových studií, ovšem pokusím se nezapomínat ani na ostatní možnosti zmíněné v teoretické části.
Při zkoumání parametrů ontologií, které by vhodně naplnily požadavky zvažovaných aplikací budu mimo jiné rozlišovat to, jaká část doménových dat je zachycena ontologií. Podle toho připadají v úvahu dva typy:
samohodnotná
Ontologie hodnotná sama o sobě, obsahuje vlastní doménová data.
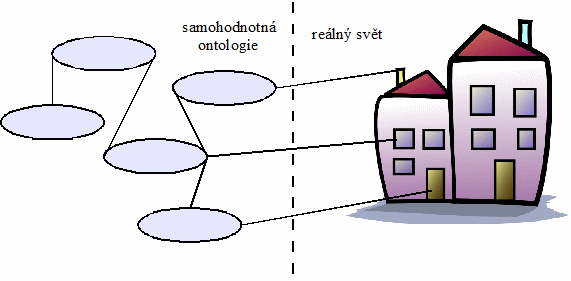
meta ontologie
Ontologie je v v pozici metainformačního systému nad daty reprezentovanými převážně jinak.
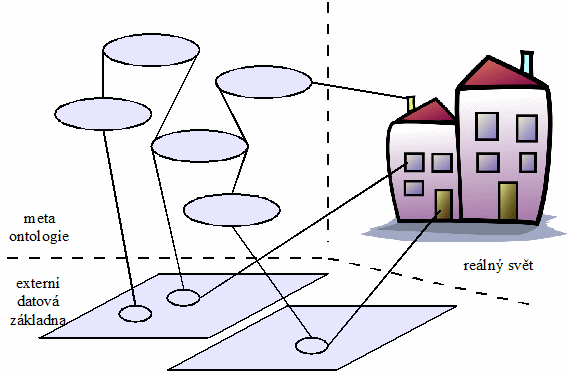
Je zřejmé, že hranice mezi nimi není příliš ostrá, ale rysy jednoho nebo druhého typu obvykle převažují.
Zaměřím se na to, aby byly zvažované případy pokud možno dostatečně různorodé, a to nejen z hlediska role ontologie v architektuře, ale i v jiných parametrech. Cílem je, aby byla výsledná knihovna maximálně ohebná a aby tak pokryla co nejširší paletu možných použití, ovšem s důrazem na různá třeba i nápaditá, ale spíše „konvenční“ využití. Trochu tedy opomenu například ontologie pro reprezentaci jazyka. Netvrdím, že výsledný systém pro něco takového použít nepůjde, ale přeci jenom asi by se našly specifické (a vhodnější) knihovny a nástroje.
Již několik let se potýkám s problémem, jak organizovat například
informace převážně textového charakteru
Mám na mysli to, co je často shrnováno pod pojmem „dokumenty“ - informace v elektronické i tištěné podobě, technické i jiné (obecně libovolné). Především vše, k čemu se buď pravidelně vracím nebo alespoň soudím, že to v budoucnu bude třeba.
programy
Typicky programy pro vývojáře (různé nástroje a pomůcky, systémy pro ukládání dat, různé knihovny, editory, frameworks, apod.), ale i obecně jakýkoliv jiný program, „který by se mohl v budoucnu hodit“. Možná vám to připadá zbytečné, ale jako vývojář potřebuji řádově stovky různých programů a nástrojů a samozřejmě stále vznikají nové verze a také úplně nové produkty. Leckdy se mi stane, že pátrám po určitém nástroji opakovaně. Přitom najít optimální nástroj nemusí být vůbec triviální – možností jsou desítky a kritérií také spousta..
jakákoliv jiná data
Mám na mysli především různá multimédia - obraz, zvuk, hudbu, video… S dostupností digitalizačních zařízení (skenerů, digitálních fotoaparátů, videokamer, ale třeba i syntetizátorů nebo různých autorských programů) potřeba organizovat multimédia rovněž poroste, a to ani nemluvím o soukromých sbírkách hudby, filmů a dalších cizích multimédií.
tak, abych vše potřebné vždy (nebo alespoň většinou) našel. A jak je zřejmé z výše uvedeného, týká se to jak dat z cizích zdrojů, tak dat vytvořených mou činností.
Kdo by měl dodat znalosti nutné pro nastolení potřebného pořádku a jeho další udržování? Z větší části asi jejich správce a uživatel – sám nejlépe ví, jaké typy dat chce třídit, podle jakých kritérií je bude pravděpodobně hledat apod. Má s tím také pravděpodobně dlouholetou (a nejspíše občas i bolestnou) zkušenost. Na druhou stranu by bylo praktické všechno to úsilí vložené do systematizace obecně použitelných dat sdílet – sdílet slovníky kategorií, konkrétní zařazení dat apod.
Na základě průzkumu svého okolí mohu konstatovat, že prakticky každý má podobný problém, byť mu možná nepřikládá přílišný význam. Každý je ve svém systému dat svým expertem a uživatelem, ovšem prakticky nikdy příliš úspěšným, protože technické prostředky pro sofistikované řešení jsou příliš složité (a tedy nepraktické), nákladné nebo vůbec neexistují.
Zmiňovaný systém by ale mohl být užitečný nejen pro jednotlivce, ale rovněž pro společnosti či instituce. V případě takového nasazení je pouze třeba zvážit dodatečné komplikace, které pramení z vyššího stupně sdílení a kooperace. Znamená to řešit otázky jako
efektivní tok dat
bezpečnost (security)
distribuovanost uvnitř sítě
mnoho otázek spíše psychologického charakteru
Zvažoval jsem využití některých klasických systémů pro správu dokumentů, ale nenarazil jsem na žádný, který by byl současně snadno použitelný a zároveň dostatečně flexibilní, aby splnil základní požadavek: „uspořádej cokoliv!“
V současné době vše organizuji v poměrně propracované adresářové struktuře na pevném disku a v databázovém katalogu uchovávám rozličné meta informace. Takový systém má velkou výhodu, že je k dispozici ihned, bez jakéhokoliv speciálního nástroje.
Nedostatky jsou ovšem značné: Není možné rozumně rozmístit data (informace/programy/cokoliv jiného – viz výše) na různá média (např. CD), aby se neztratil celkový přehled a aby byly po ruce náhledy, vazby a souvislosti. A zejména - adresářová struktura je prostý strom a naprosto selže při pokusu třídit v ní data podle více kritérií. Leccos je možné řešit pomocí symlinků (na systémech s Windows zvaných zástupci), ovšem výsledek stejně působí provizorním dojmem a funguje spíše jako karikatura na systém.
I profesionálním systémům pro správu dokumentů a dat chybí sdílený slovník kategorií a možnosti propojit různé instance. To zvyšuje náklady na zavedení systému a ještě dlouho poté znesnadňuje komunikaci mezi subjekty, natož nějakou užší integraci.
Zatím se nebudu věnovat konkrétním parametrům ontologie, která by se dala využít při budování systému pro organizaci dat, spíše vyjdu z nějaké co nejobecnější definice ontologií a zamyslím se nad stejně obecně pojatými přínosy. Tak tedy, dejme tomu že ontologie je sdílená konceptualizace světa. Například jaký prospěch by přineslo spojení systému systému evidence dat s vhodnou ontologií?
Předně, půjde o obecné zvýšení efektivity a kvality vyhledávání. Takový systém by umožnil vyhledat potřebná data libovolného typu, podle mnoha obecných i specifických kritérií, omezených pouze vyjadřovacími schopnostmi použité ontologie a ontologií samotnou.
najdu co hledám
Bez použití kvalitního systému pro správu dat se snadno může stát, že se vůbec nepodaří najít relevantní data. Stát se to může jednotlivci, který organizuje svá osobní data, tím spíše to hrozí v organizaci kde spolupracuje lidí více a mnozí často nemají ponětí o práci některých svých kolegů. Důsledky toho, že se nepodaří najít to, co je třeba mohou být různé, ale obecně negativní. Často to povede k dodatečným nákladům spojeným s opětovnou tvorbou již vytvořeného (redundance, duplikace)...
najdu to nejrelevantnější
Uživatel při prohledávání možná často skončí u prvního trochu použitelného výsledku. Pokud by byl systém založený na ontologiích (včetně souvislostí typu synonym, příkladů, paralel, různých dalších vztahů), zvýšila by se pravděpodobnost nalezení toho nejlepšího, co je ve spravované množině dat k dispozici.
Pokud se spokojíme s prvním použitelným výsledkem, pravděpodobně to přinese různé negativní důsledky:
Vývojář zvolí méně vhodný nástroj, který znesnadní, prodraží nebo v extrémním případě úplně zboří vývoj. Právník nenajde speciální zákon, který se vztahuje přesně k řešenému problému. Konstruktér ve svém výkresu použije méně vhodnou (třeba dražší) normalizovanou součást.
vnější konzistence pro správu i užívání
Vše by spravoval jeden systém, maximálně flexibilní. Výhoda je zřejmá – není nutno instalovat, spravovat více produktů, není třeba učit se a případně školit uživatele v jejich používání apod. Objeví-li se nová kategorie dat, jednoduše ji do pružného systému včleníme… Jednotné rozhraní pro správu mnoha typů dat by tedy snížilo náklady na obsluhu, také by přispělo k tomu, aby byl systém využíván s oblibou a často.. Jednotné rozhraní pro správu firemních dokumentů i soukromé sbírky hudby, pro knihy i fotografie, pro dokumenty vlastní i cizí.
konsolidace procesů
Před zavedením zvažovaného systému každý uživatel má svůj způsob práce s dokumenty. Použití systému sjednotí nejen postupy jednoho uživatele pro dosahování různých cílů, ale také doposud nezávislé a leckdy nekompatibilní, nesourodé a třeba i nepříliš kompatibilní postupy jednotlivých uživatelů. Konsolidace procesů povede k úsporám.
univerzálnost znamená širokou uživatelskou základnu
Kvalitní systém, který by splňoval popsané požadavky by mohl dosáhnout hromadného rozšíření v různých odvětvích. To by byla jistě výhoda, ještě znásobená, kdyby pro různá odvětví vznikly příslušné slovníky (ano, ontologie) a nejlépe také jednotné postupy popisování a třídění dat. Spojíme-li to ještě s možnostmi Internetu a jeho prudkým rozvojem, výhody jsou zřejmé – snadné sdílení dat, až propojování nezávislých systémů z kompatibilních, tedy nikoliv nutně totožných, domén.
uchování cenných expertíz
Znalosti, které pomáhají popsat, třídit a najít potřebná data bývají mnohdy nashromážděny mnohaletou zkušeností. Zkušenost může odejít s pracovníkem, který je jejím nositelem. Kodifikace v rámci znalostního systému by zkušenosti zachovala, zpřístupnila, umožnila opětovně použít.
Většina rizik má původ v relativní vnitřní komplikovanosti systému a také v poměrně značných nárocích na obsluhu, zejména ve fázích zavádění. Jako typické problémy případného nasazení systému jsem vybral:
špatný způsob kategorizování
V případě že by se nevěnovalo dostatek pozornosti výběru evidovaných charakteristik, sledované vlastnosti by byly irelevantní k potřebám, výsledkem by byl sofistikovaný a flexibilní systém, ve kterém by ovšem nikdo nic nenalezl.
Systém musí poskytnout dostatečná vodítka (výchozí slovníky, různé příklady, klást otázky – proč? jak?, možná nějaké průvodce...), aby se toto riziko co nejvíce snížilo.
rizika přechodu – nechuť a obavy
Zejména ve větší organizaci by téměř jistě nastaly potíže při přechodu. Pracovníci téměř jistě svá heterogenní data nějak spravují – ať již centrálně, distribuovaně po odděleních, nebo každý sám, více či méně systémově. Zažitá a do jisté míry fungující řešení by musela být postupně převáděna do systému nového. Ti uživatelé, kteří mají averzi k systému, ke všemu technickému, případně k novinkám a změnám jako takovým, se budou bránit.
Systém by měl umožnit postupné zavádění, aby nedůvěřiví dostali potřebný čas.
moc práce
Ať bude systém sebeinteligentnější, nezbaví nás to nutnosti přeci jenom nějaká meta data pořídit ručně. Zřejmě vzniknou otázky, jako třeba: Kdo to udělá s existujícími a již nějak zorganizovanými daty? Kdo to bude dělat do budoucna? Objeví se jistě i otázky, zda taková práce bude dostatečně vyvážena přínosy.
Jako klíčová se v této souvislosti jeví jednoduchost obsluhy systému.
Z jakých funkčních celků by se systém mohl skládat? V diagramu je znázorněn hrubý návrh architektury včetně vazeb mezi moduly, o jejich významu se zmíním dále.
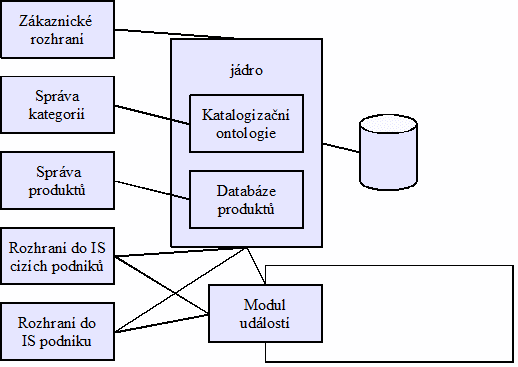
pořizovací modul
Umožní lidskému operátorovi („pořizovači“) doplnit k datům informace, které i chytrý počítačový systém těžko zjistí.
správa ontologie doménových kategorií
Přestože každá položka dat by měla být vhodně „obalena“ svou meta informací nezávisle na jiných, pro účely prohledávání bude třeba na množinu těchto informací nahlížet jako na celek.
Pro úspěch nasazení jde o klíčovou část systému - bez důsledně promyšleného a alespoň místně jednotného přístupu k tvorbě a správě kategorií by celý systém ztroskotal, jak bylo naznačeno výše, v rozboru rizik.
správa rolí
Důležitou vlastností by bylo omezení/přiznání úrovně přístupu k ontologii podle role uživatele. Úložiště kategorií ontologie by bylo pravděpodobně čitelné pro pořizovače, měnit by ho mohl pouze kompetentní správce, který by znal vazby v systému, důsledky případných změn a měl by celkový přehled o doméně. Situace si jistě bude vyžadovat jejich úpravy, zejména rozrůstání, a tak by na požádání pořizovačů databázi upravoval (případně by autorizoval úpravy jejich). U jednouživatelského nasazení role pořizovače a správce splývají v jedinou.
modul fyzické organizace
Bude zajišťovat vyšším modulům přístup k datům – uloženým v souborovému systému, objektové databázi, XML databázi, či kdekoliv jinde.. Na zvážení je, zda by modul pouze zajišťoval spolupráci s fyzickým úložištěm, případně zda by data v rámci tohoto úložiště nějak rozumně organizoval.
dotazovací modul
Brána, kterou uživatelé prahnoucí po datech použijí pro formulování dotazů. Vnitřně by se skládala z minimálně 2 co nejvíce oddělených částí – vrstvy logiky a prezentační vrstvy. Výchozí implementací prezentační vrstvy bude asi nejspíše vhodné grafické uživatelské rozhraní.
Kromě výše uvedených připadají v úvahu další, spíše rozšiřující moduly – modul bezpečnosti (security), modul zálohovací, indexační, vyrovnávací paměť, podpora práce v síti,… Při nasazení ve víceuživatelském prostředí by byly mnohé z těchto modulů rovněž důležité, ale pro jednoduchost je zatím nebudeme dále uvažovat.
Podle [ZTECHMP02] je vhodné volit znalostní čí expertní systém jako základ architektury pokud
problém není formálně vyjádřitelný
řešení není založeno na deterministických reproduktivních postupech
princip řešení nemá teoreticky dobré a ucelené podklady, užité znalosti nejsou formálně dobře vyjádřitelné
užívané údaje jsou vágní, nepřesné, nespolehlivé, vzhledem ke své nedostupnosti neúplné
Které moduly systému splňují uvedená kritéria? Začněme pořizovacím modulem – ten by měl být hodně flexibilní, měl by disponovat i nějakými heuristickými schopnostmi, aby uživatele navedl k zadání správných kategorií metadat. To vše ale lze řešit konvenčními prostředky, tedy v procedurálním objektově orientovaném jazyce. Centrální správa doménových kategorií i centrální databáze meta informací mají charakter databáze – znalostní metody by byly zbytečné. Modul fyzické organizace je pouze vrstvou rozhraní pro komunikaci s úložištěm – rovněž stačí konvenční postupy a stejně tak i uživatelského rozhraní dotazovacího modulu.
Zbývá logika dotazovacího modulu, což je ovšem něco docela jiného.
Shrňme, jaké by měl mít schopnosti. Z nich vyplynou i podrobnější požadavky na zachycená a zpracovávaná data:
maximum informací čerpat samostatně přímo z dat
Lidé by při takovém čerpání dat mohli asistovat – data validovat, zpřesňovat, doplňovat apod., ale systém by je měl ušetřit maxima rutinní práce, kdy se pouze něco odněkud někam přepisuje. Taková práce nejen že je nepříjemná, nudná, ale také přináší redundanci, a tedy riziko vzniku inkonzistence v datech.
Mohl by uvažovat například takto:
má
příponu MP3 => je to hudba
má
příponu MP3 => možná obsahuje ID3 tag
možná
obsahuje ID3 tag => načti meta informace
Pro úlohu by možná mohl sloužit samostatný modul.
zpracovat nejasné, neúplné dotazy
Klíčovým parametrem systému, který by jej měl odlišit od běžných systémů pro správu obsahu by měla být výjimečná vyhledávací schopnost. Uživatele nechceme nutit uvažovat podle počítače, ale naopak.
odpovídat na základě neúplných meta informací
Systém by měl být rozumně použitelný i v době, kdy bude probíhat výstavba katalogů – pokud uživatel (investor) neuvidí první známky přínosu co nejdříve, těžko bude věnovat svůj čas, energii či finance dalšímu nasazování systému. Kromě toho – žádná ontologie není dokonalá, vždy jde o určitou aproximaci či odraz světa. Systém by ale měl vytěžit maximum z toho, co k dispozici má.
snadno „vstřebávat“ doménové zvyklosti pro pokládání dotazů
Mám na mysli doménově specifickou terminologii, strukturu dat, vzájemné souvislosti dat i metadat. Systém by měl být schopný zachytit doménové znalosti nezbytné pro „porozumění“ dokumentům, jejich obsahu a významu, především s cílem porozumět případným vyhledávacím dotazům.
Určitou drobnou znalostí je dejme tomu vztah:
„PDF dokument=>čitelný Acrobat Readerem“
Systém by měl takovou znalost obsáhnout a také využít všude, kde to bude vhodné. Z toho vyplývá, že souběžně s naplňováním stromu společných kategorií meta informací by měla být doplňována rovněž odpovídající pravidla v logice dotazovacího modulu, o kterých bude souzeno, že z hlediska účelu nasazení mohou být praktická.
„chápat“ význam kategorií
Třeba co je to program, zakázka… prvním stupněm by mohla být schopnost rozeznat synonyma, antonyma a jiné lexikální vztahy.
rozpoznávat přirozený jazyk
V ideálním případě by vyhledal vhodné informace na základě dotazu typu
„Chci navrhnout www stránku, ale neumím moc syntax HTML jazyků“
což ale rozhodně snadné není, alespoň při současném stavu poznání v příslušných oborech. Ovšem bude-li systém dobře navržen a zejména budou-li data vhodně a dostatečně popsána metadaty, snad bude časem, při pokroku v rozpoznávání přirozeného jazyka, možné podobné funkce začlenit do dotazovacího modulu.
propojit obecné znalosti se znalostmi v doméně
Systém by měl být vybaven sadou obecných pojmů a vztahů tak, jak jsou například definovány v různých top-level ontologiích, což ušetří práci jednotlivým uživatelům a také usnadní případné propojení vytvořených databází.
Na druhou stranu, primárně by měl být implementován jako prázdný, tj. bez doménově specifických kategorií dat a pravidel v dotazovacím modulu. Místo toho by vznikaly samostatné ověřené, doménově specifické slovníky pro specifické typy uživatelů.
Kromě toho by případný uživatel (a ve svém oboru doménový expert) pravděpodobně budoval další, již silně specifické koncepty, které by nenašel v jiných slovnících.
Klíčové je, aby si se všemi těmito zdroji sytém poradil, dokázal je zařadit do vzájemných kontextů a účinně je využívat při hledání.
Možná v tuto chvíli namítnete, že celý systém bude příliš složitý, aby mělo smysl se jím vůbec zabývat. Kus pravdy na tom je, ovšem skutečná složitost je koncentrována pouze v logice dotazovacího modulu. Dotazovací modul by byl ale pouze jednou (byť docela technicky asi nejzajímavější) částí celku a i bez něj by byl systém přínosný. Minimálně by umožnil již nyní data organizovat s ohledem na budoucnost. A to by mělo být hlavním cílem jakékoliv evidence, organizace a systematizace.
Úplně ideální by bylo rozčlenit dotazovací modul na část obecně použitelnou i v jiných programech a část specifickou. Tvorba univerzální knihovny pro tvorbu, manipulaci a prohledávání ontologií bude předmětem další části práce.
Zvážíme-li náklady a přínosy pokročilých technologií, možnosti (technické i finanční) a také architekturu systému (modulární), asi bude nejrozumnější nejdříve implementovat pouze prototyp bez pokročilých schopností - možná bude zvládat jen dotazy ve stylu SQL nebo ani to ne... - a při tom mít uvedená specifika na paměti. Především, prototypem tvořená ontologie musí být dostatečně bohatá, aby umožnila povýšení dotazovacího modulu bez výraznějších zásahů do dat ze strany uživatele...
Jak již bylo naznačeno - ostatní moduly jsou principiálně triviální (pořizovací, centrální správa doménových kategorií i centrální databáze meta informací) nebo je možné dobře využít existující systémy a tak si ušetřit podstatnou část práce (modul fyzické organizace – s podporou vhodné vrstvy pro perzistenci, např. [OJB]).
Stanovme si nějaká kritéria pro posouzení výsledků. Projekt bude v pokusné implementaci úspěšný, pokud s jeho pomocí bude možné
připojovat takové meta informace k datům, která umožní zachytit vlastnosti, relevantní místa v kontextu kategorií domény a základní souvislosti s jinými daty z domény
přizpůsobovat centrální databázi kategorií
data automaticky, logicky (dle daných pravidel – nejspíše dle přiřazených kategorií) přeuspořádat v rámci fyzického úložiště, zpočátku zejména souborového systému pevného disku.
integrovat více fyzických úložišť, v prvních fázích například „vědět“ o datech, která právě nejsou systému fyzicky dostupná - např. protože byla přenesena na CD.
pokládat jednoduché dotazy (dotazovací modul prozatím bez navrhovaných heuristik)
vytvořit nebo z vhodné top-level ontologie načerpat univerzální kategorie a pravidla
Již jsem vytvořil primitivní prototyp. Sice by se dal použít pro organizaci omezeného množství dat, ale smyslem bylo spíše si ověřit některé uvedené nápady v praxi. Následovat by měl prototyp dokonalejší, který by již splnil uvedené cíle. Prototyp má následující charakteristiky:
technologie
Zvolil jsem jazyk Java, především pro jeho platformní nezávislost a silnou podporu pokročilých technologií (XML, databáze,...)
ontologický model
Používá primitivní interní ontologii, kterou může uživatel z grafického prostředí programu budovat a upravovat. Použitý ontologický meta model umožňuje definovat kategorie pojmů a základní vztahy. Má ale také řadu omezení, například nelze definovat vztahy mezi kategoriemi (pouze mezi daty), vztahy nemohou mít vlastní hierarchii apod. Také chybí podpora pro pravidla.
podporované typy dat
Pracuje výhradně s daty na pevném disku – se soubory a adresáři. Na druhou stranu disponuje určitou inteligencí v rozpoznávání typů dat – podle toho nabízí vhodné kategorie k zařazení, také přizpůsobuje vzhled uživatelského rozhraní (generuje náhledy dokumentů, umožňuje přehrávat audiovizuální data apod.).
úložiště pro databázi kategorií a metadat
Kategorie ukládá do centrálního XML souboru na disku. Metadata ukládá do XML souborů poblíž popisovaných dat. Protože si systém zatím nečiní nároky na kompletní správu zařazených dat (pořád to jsou soubory na disku), bylo zvoleno právě toto řešení, aby příliš nehrozilo, že při běžné manipulaci (přesouvání, přejmenovávání..) budou metadata ztracena či oddělena od jimi popisovaných entit.
Formát pro zachycení metadat je takovýto – použit je vlastní na XML založený jazyk:
<elTree
name="program">
<elDesc
name="verze"/>
<elDesc
name="s/n"/>
<elBranch
name="co" necessity="required">
<elTwig
name="úpravy">
<elTwig name="hromadné"/>
</elTwig>
</elBranch>
<elBranch
name="s čím">
<elTwig
name="dle formátu">
<elTwig name="text">
<elTwig name="web"/>
</elTwig>
</elTwig>
</elBranch>
dotazovací modul a uživatelské rozhraní
Dotazovací modul pro jistotu chybí úplně. Přikládám dvě obrazovky uživatelského rozhraní, které umožňuje popisovat data, budovat ontologii a procházet tím, co již bylo zpracováno. Komponenty uživatelského rozhraní se dynamicky přizpůsobují typu dat (jak již bylo zmíněno) a také podle příslušnosti k hlavním kategoriím.
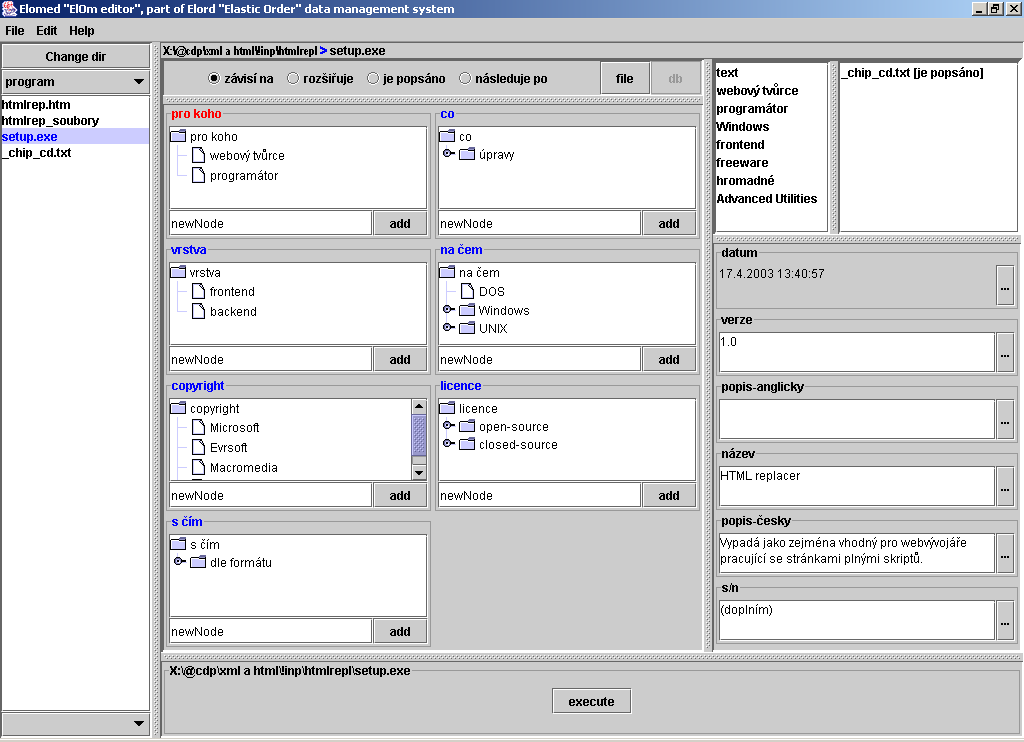
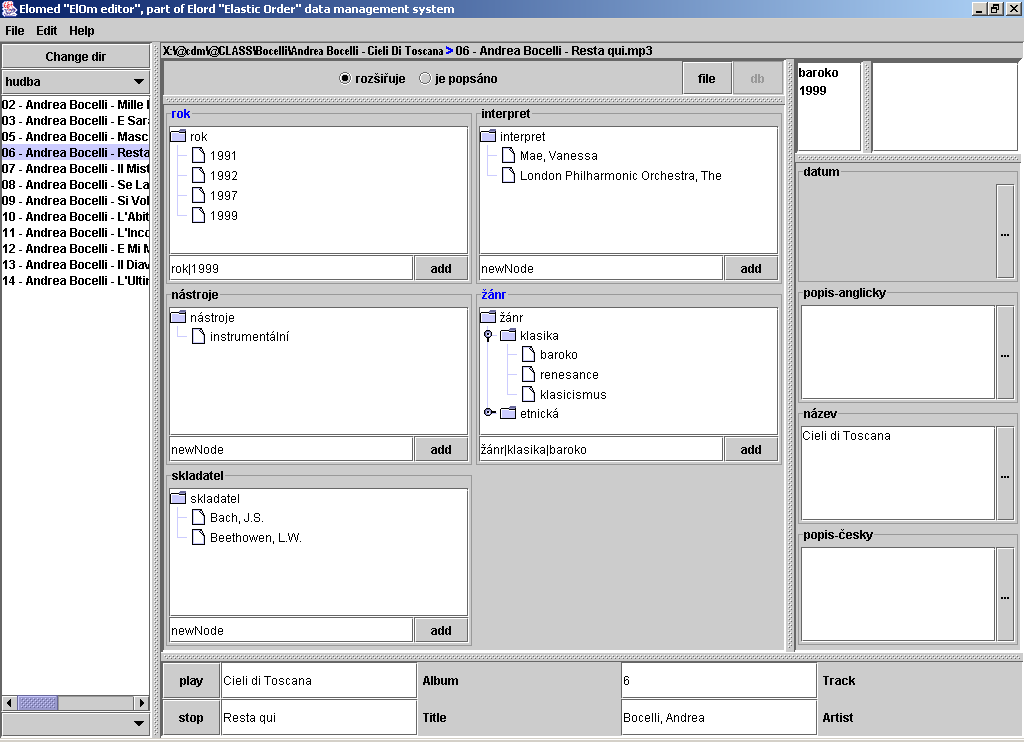
V první řadě, jde o typickou meta ontologii, která pouze popisuje externí data. Informace zachycené v systému budou trojího typu:
příslušnost ke kategorii
v terminologii domény, ve které by byl systém nasazen.
Například ke grafickému editoru pod Linux by mohly být:
„program/pracuje
s/grafika/bitmapy“
„program/poběží
na/UNIX/Linux/Debian“
„program/vrstva/frontend
aplikace“
Údaje k firemnímu dokumenty by mohly obsahovat třeba:
„dokumenty/zakázky/střechy“
vztah k jiné položce v databázi
„rozšiřuje
(odkaz)“
„popisuje
(odkaz)“
„následuje
po (odkaz)“
popisné údaje
Vše ostatní, co nemá charakter čí vazbu ani na centrální členění kategorií, ani na jinou položku v databázi. To bude vždy trochu relativní, protože bude záviset na šíři a hloubce ontologie.
„Pěkně
se v něm ručně retušuje, nemá ale žádné
zabudované filtry.“
Několik konceptů by mělo vyjádřit základní charakter popisovaných dat, tedy zda jde o textový dokument nebo třeba o videozáznam. Vzhledem k poměrně univerzálním ambicím bude třeba zachytit materiální povahu popisovaných entit – jsou abstraktní nebo konkrétní? Existují v elektronické podobě nebo jako hmotné předměty reálného světa?
Určitou kategorii konceptů budou tvořit různé subjekty (fyzické osoby nebo třeba společnosti) v různých rolích (například autor). Dále nesmíme zapomínat na obecné vztahy, zejména isa, součást celku nebo alternativa, ale jistě mnohé další.
Prototyp jsem testoval především na dokumentech převážně textového charakteru, multimediálních datech a také na programech. Konkrétně například u programů z hlediska jejich zařazení do popisovaného systému v roli dat jsem zatím skončil u sady takovýchto metadat:
kategorie
co (= co program dělá)
s čím (= s jakým typem dat)
pro koho (je vhodný)
na čem (poběží – požadovaná platforma)
vrstva (frontend aplikace nebo třeba na pozadí běžící služba)
copyright (výrobce)
licence (ne znění, ale její charakter)
popisy
jméno
verze
slovní popis
vztahy k jiným datům
závisí na (a obráceně „je nezbytný pro“)
následuje po (a obráceně „předchází“)
rozšiřuje (možnosti jiného programu a obráceně)
je popsáno (dokumentem)
Kategorie mohou být obecně větveny jako stromy, nejvyšší stupeň udá kategorii a další stupně jednotlivé možnosti na zařazení v rámci této kategorie. Kategorie pro evidenci programů by mohly vypadat třeba takto:
na čem
DOS
Windows
16-bit
9x
95
98
ME
NT řada
NT
2000
XP
UNIX
Linux
Debian
…
Některé z nich (s čím, pro koho, na čem, copyright apod.) by koncepčně odpovídaly spíše vztahům, ale takové řešení by vyžadovalo již v první fázi reálného nasazení skutečně znalostně implementovaný dotazovací modul. Proto jsou to zatím kategorie, pro další verzi prototypu ale počítám s jejich transformací ve vhodné vztahy.
Jiným velmi dobrým příkladem doménově specifické aplikace by bylo využití systému jako bibliografického nástroje. V tomto oboru není nouze o teorii – existuje mnoho publikací, které odpovídají na otázky co je třeba evidovat, jaké výstupy generovat, jaké dotazy připadají v úvahu apod.
Jednoduchý dotazovací modul by již se současným provizorním ontologickým modelem mohl zvládat
dotazy na kategorie
Například:
„co:úpravy“
„s
čím:dle formátu:text:neformátovaný“
„na
čem:UNIX:Linux“
fulltext
Sice poměrně primitivní, ale pořád přesto relativně účinný způsob prohledávání. Minimálně v prvních verzích bude hrát klíčovou roli, časem by měl být postupně doplněn inteligentními variantami. V úvahu připadá fulltext
v rámci popisných položek
kompletními metadaty a nakonec
daty
Poslední jmenovaný by mohl časem sloužit i při analýze obsahu dokumentu v době zařazování do databáze a na jeho základě by mohly být pořizovači nabídnuty vhodné kategorie. Fulltext by měl být také doplněn o schopnost interpretovat regulérní výrazy, wildcards, apod.
navigace dle závislostí
Na stránce či obrazovce s vyhledanou informací o položce dat budou též odkazy na jiná související data. Modul umožní tyto odkazy sledovat.
Elektronický obchod má budoucnost jistou, otázkou je spíše, jak se na vzdouvající se vlně co nejlépe svézt – konkurence je tvrdá a počítají se milimetry. O stavu elektronického obchodování a jeho problémech jsme již mluvili. Proto si jen trochu připomeneme o co jde a myšlenky rozvedeme více směrem k praktické aplikaci.
B2C
Zákazník se bude vracet na server, který ho přesvědčí svou přehledností, spolehlivostí, nízkými cenami (které pramení z úspor nákladů a velkých obratů), inteligencí, aktuálností, dodatečnými službami. Jak je zřejmé z úspěchu těch, co působí v první lize (amazon.com), klíčem je využít maximum toho, co technologie nabízí (silné stránky) k překonání nevýhod elektronického obchodu (slabé stránky), tedy toho, že chybí osobní kontakt se zbožím, prodavači apod. Technologie umožňuje například sbírat ohromné množství informací o zákaznících – co nakupují, ale i co si pouze „osahají“ v regálech, kdy přicházejí, co je baví, jak rychle se po obchodě pohybují..
C2C
Uživatel bude nakupovat tam, kde najde, co hledá a prodávat tam, kde mu bude umožněno zboží zařadit a popsat tak, aby ho našel ten, kdo ho hledá. Systém také musí umožnit sledovat důvěryhodnost a spolehlivost uživatelů.
B2B
Efektivita procesů, dokonalá logistika, minimum papíru, rychlost reakce, spolehlivost, informace.. Elektronické obchodování a vůbec elektronizace procesů v oblasti vztahů mezi komerčními subjekty disponuje ještě větším potenciálem růstu než u B2C.
Produkty elektronického obchodu je zvykem organizovat do tabulek relační databáze. Elektronické obchody jako samostatné znovupoužitelné produkty obvykle nabízejí jistou míru flexibility, ale ta je samozřejmě omezena datovým modelem – nejčastěji relačním, již méně běžně objektovým. Organizace produktů takového obchodu obvykle nerespektuje doménová specifika a podporuje pouze jednoduchý systém kategorií. Vazby mezi kategoriemi (natož mezi jednotlivými produkty), verze, kombinace – alespoň něco z toho obvykle chybí.
Elektronické obchody šité na míru samozřejmě mohou toto všechno zvládat, ale při vývoji není kvalita jediným kritériem. Svou roli hrají další hlediska – cena, návratnost, účelnost. To je samozřejmě v pořádku, ale výsledkem jsou aplikace silně doménově specifické, které není snadné použít opakovaně.
Procesy integrace a konsolidace jsou v B2B určitě podstatně dál než u B2C, ale i tak to bude ještě dlouhá cesta. Sice obvykle funguje docela dobře výměna obchodních dokumentů (faktury, dodací listy, reklamační protokoly..), horší je to ale s integrací produktových řad.
Sám jsem například v situaci, kdy bych rád nakupoval zboží od několika velkých dodavatelů, jejichž nabídka se zčásti překrývá a zčásti doplňuje. Rád bych jejich nabídky integroval do vlastního elektronického obchodu, což ale není vůbec snadné a je téměř nemožné provést to automatizovaně. Každý totiž ve svých databázích pojmenovává zboží jinak, přiděluje mu jiná identifikační čísla.. navíc přestože se stává zvykem nabízet elektronickou výměnu dokumentů, ceníky ve strojově snadno interpretovatelné podobě zvykem stále ještě nejsou.
integrace procesů
Právě ontologie jako sdílené reprezentace světa by mohly hrát roli lepidla produktových portfólií tak, jako například EDI již dnes mnohde do určité míry sjednocuje a zefektivňuje vlastní obchodní procesy. S integrací více dodavatelů B2B pod střechou jednoho B2C obchodu by se počítalo od začátku. Produktové informace postavené na ontologiích by bylo snadné integrovat, transformovat, modifikovat, vše značně automatizovaně.
informační jistota pro zákazníka
Ontologie jako informačně i sémanticky bohaté, přesné, výstižné... by přinesly nové kvality i do obchodování B2C. Souvislosti, podrobné kategorie podle mnoha hledisek, jednotně zachycené parametry a vlastnosti konkrétních produktů, pro to vše by byly ontologie maximálně vhodné. Uživatel by mohl prohledávat s mnohem vyšší relevancí, díky sémantice automatizovaně porovnávat, a to nejen v rámci jednoho e-shopu, ale i mezi nimi. Snadno by nacházel alternativy, vhodné doplňky a kombinace a další vztahy a souvislosti.
znovupoužitelnost, e-shop reflektuje skutečné rozdíly
A co je klíčové pro úsporu nákladů – detaily o produktech by stačilo udržovat pouze jednou – postaral by se o to například sám výrobce a používat opakovaně, bez dodatečných nákladů. Obchody by se mohly více zaměřit na soutěž v tom, v čem jsou opravdu odlišné, tedy nikoliv v parametrech jimi nabízeného zboží (které je stejné, vždyť všechno vyrábí Čína, že?), ale spíše v dodacích podmínkách doprovodných službách, reklamaci a samozřejmě v cenách.
sdílení
Podobně by bylo možné sdílet třeba i uživatelské připomínky k danému zboží – hodnocení, recenze, nápady, podněty.. Každý obchod by je umožnil doplňovat o připomínky vztahující se právě k jeho obchodu (kvalita služeb..), které by již dále nesdílel.
nový stupeň flexibility
Pokud jsou produktová data zachycena ve struktuře relační databáze nebo v podobě objektů, není snadné strukturu měnit a přizpůsobovat. Objektový model oproti relačnímu sice usnadňuje vývoj, ale stále se nedá mluvit o flexibilitě za běhu – pokud zjistíte, že třída, která reprezentuje nějakou kategorii zboží by měla být doplněna o další atributy, neobejdete se bez zásahu do programového kódu (a nejspíše rekompilaci). Takové zásahy by měly být doprovázeny testováním, navíc bude možná třeba zasáhnout do starých dat.
Ontologický datový model by přinesl novou dimenzi flexibility - umožnil by za běhu podstatně měnit obsah obchodu. V extrémně rychle se rozvíjejícím světě elektronického obchodu je to nezanedbatelný parametr.
Jistě hrozí i technologická rizika. Myslím ale, že silně převažují ta, jež vycházejí ze sociálních aspektů, obchodních politik a vztahů, nepružnosti organizačních struktur velkých společností a dalších záležitostí typicky lidských. Například:
apatie ze strany dodavatelů
Ty největší přínosy by z využití ontologií plynuly pokud by se co nejvíce spolupracujících subjektů dohodlo na jejich používání. Jak mohu potvrdit z vlastní zkušenosti, jednat o čemkoliv (tím spíše o něčem tak závažném) s molochy typu Intel, HP nebo třeba Sun není snadné..
obavy obchodníků
Zvýšení transparentnosti někteří obchodníci ponesou nelibě – dost možná se jim nebude líbit, že uživatel na dvě kliknutí porovná jejich nabídku s přesně odpovídající nabídkou konkurence.
Internet ovšem k otevřenosti směřuje a je čím dál zřejmější, že tradiční metody utajování, těžící z asymetrické informace kupujícího a prodávajícího zde příliš nefungují. Jakmile se navrhovaný systém skutečně rozjede, obchodníkům, kteří zůstanou mimo nezbude než se přidat, anebo živořit někde na elektronické periférii.
nechuť ze strany uživatelů
Myslím že toto riziko je minimální. Výsledek by z uživatelského hlediska měl být velmi přehledný a jednoduchý – na webech zapojených do projektu se snadno zorientuje (respektují jednotné konvence organizace produktů, jednotné názvy, kódy) a navíc dostane do rukou mocné zbraně umělé inteligence pro hledání a porovnávání, které bohatě vynahradí jakékoliv nepohodlí.
rizika slabé vůle k dohodě
Velmi přínosné by bylo sdílení doménově specifických ontologií. Pokud se ale klíčové subjekty z nějakého důvodu nedohodnou na společných postupech, nevytvoří univerzální slovníky, věc sice nebude úplně ztracena, ale promrhá se část integračního potenciálu – neshody bude třeba překlenout technologiemi mapování, propojování a transformace ontologií.
zákaznické uživatelské rozhraní
Ta část aplikace, se kterou bude uživatel přímo komunikovat. Základem budou sady transformačních mechanismů pro spojení
informací čerpaných z jádra systému a
šablon s vizuálním stylem
dále
sada formulářů a jiných prvků pro zadávání dotazů
různí průvodci
a sem tam něco dalšího
rozhraní pro správu
V diagramu jsou naznačena rozdílná rozhraní pro správu kategorií a produktů. V reálném systému by bylo podobných rozhraní pravděpodobně více, podle různých správcovských rolí. V reálném nasazení samozřejmě více rolí může zastat jeden člověk, jindy ale bude praktické například ontologii vytvářet ve větším kolektivu zástupců různých zúčastněných stran, zatímco produkty si bude spravovat každý sám.
ontologie kategorií
Nejzajímavější část systému, klíč k integraci rozdílných systémů a zvýšení informační hodnoty obchodu pro zákazníka. Bylo by zde soustředěno vše obecné (obecné ontologické koncepty a vztahy, nejspíše převzaté z top-level ontologie), ale i koncepty doménově specifické.
V reálném nasazení by byla tato ontologie z větší části tvořena verifikovanými slovníky převzatými od druhých, doplněná vybranými koncepty, které prozatím nikdo jiný nepotřeboval, ale pro činnost konkrétního obchodu jsou důležité. Z těch by se po ověřování a validaci mohly časem stát další sdílené slovníky.
Bude třeba vypracovat přesná pravidla tvorby, verifikace a sdílení slovníků, které by takto vznikaly.
databáze informací o produktech
Sem patří vše, co není dostatečně univerzální, aby se hodilo alespoň obchodům působícím ve stejném oboru s jiným sortimentem. I tak je zde prostor pro znovupoužití – produktové katalogy navázané na kategorie z ontologie by sloužily případným odběratelům jako zdroj pro injektáž obsahu do jejich vlastních obchodů a informačních systémů.
modul událostí (transakční modul)
Klíčový prvek pro zajištění rozšiřitelnosti, taková komunikační brána se dvěma základními úkoly:
odesílat informace o událostech vybraným naslouchačům a naopak
přijímat informace o událostech ve vnějším světě, tedy zejména v jiných systémech.
Typickou událostí ve vnitřním světě by bylo třeba zařazení nového produktu nebo kategorie do ontologie, ale také třeba uživatelská žádost o načtení informací o vybraném produktu.
Na další zvážení bude, zda by ostatní moduly rozhraní, především rozhraní uživatelská, neměla být rovněž alespoň zčásti podřízena modulu událostí.
Tato otázka se řeší v závěru práce, v popisu architektury obecného ontologického systému postaveného na navrhované knihovně pro práci s ontologií.
rozhraní do IS podniku
Modularitu považuji za klíčový parametr architektury, který umožní vybudovat živou, flexibilní a snadno spravovatelnou aplikaci namísto monolitického molocha. Proto nečekám, že by systém řešil vše, co obvykle řeší podnikové informační systémy, byť zde můžeme sledovat mnohé paralely.
Spíše, s podporou transakčního modulu mechanismem zasílání zpráv o událostech, budou moci vznikat rozhraní pro rozšíření funkčnosti.
Mám na mysli propojení s nástroji pro řízení vztahů se zákazníky (CRM), pro evidenci zakázek, plateb, s moduly účetnictví a skladové evidence a dalšími.
Několik z mého pohledu nápaditějších možných rozšíření zmíním dále:
rozšiřující modul objednávek
Je sice integritní součástí každého elektronického obchodu, tudíž by měl možná být modulem základním. Zabývám se především aplikací ontologií, proto vzniká otázka, jak by vypadalo ontologické pojetí procesu objednávání a nákupu. Některé ontologie se specializují vyloženě na reprezentaci podobných procesů, např. [EONUKMZ98].
V našem konkrétním případě by například při objednávání vznikla instance konceptu objednávka, s vazbami na instance objednávaných produktů, doplněných o různé požadované parametry (množství, různé doplňky apod.). Příslušné dynamické vlastnosti instancí zboží (vlastně něco jako metody) spočítají celkovou cenu...
Na druhou stranu je na zvážení, zda by ontologické pojetí nepřineslo spíše komplikace.
rozšiřující modul analýzy chování uživatele
Znát chování uživatelů bylo dříve konkurenční výhodou, dnes je to již téměř nezbytnost. Již zmíněný mechanismus předávání událostí by příslušnému statistickému modulu naprosto postačoval. Co by se mělo sledovat? Nejen realizované nákupy a celé zakázky, ale i pohyb uživatele po webu, a také nerealizované poptávky, nedokončené objednávky..
rozšiřující modul kalkulace nákladů
Ontologie je schopna evidovat vztahy mezi součástmi a celkem, různé podmíněnosti a další vztahy. To ji přímo předurčuje k dalšímu využití – jako základu kalkulačního modulu.
K produktům již tak evidovaným v ontologii bude stačit připojit informace o komponentách a dalších vstupech a vhodná dynamická vlastnost (funkce zachycující mechanismus výpočtu) z nich odvodí náklady.
V ontologii by to mohlo být realizováno tak, že kategorie „nositel hodnoty“ svým potomkům předá dynamickou vlastnost cena. Ta má výchozí hodnotu nula, ale může (a měla by) být překryta konkrétní hodnotou nebo výpočetním mechanismem u konkrétních potomků. Ceny by mohly být počítány v konkrétní měně, případně v určitých systémech bodů, ze kterých by se vhodnými převodními koeficienty výsledné ceny odvodily.
Dejme tomu, že vyrábíme nábytek. V ontologii je zaneseno, že židle je nositel hodnoty (něco co se dá prodat), že se skládá ze čtyř noh a jednoho sedátka, dále ceny každé komponenty a dynamická vlastnost pro stanovení ceny židle.
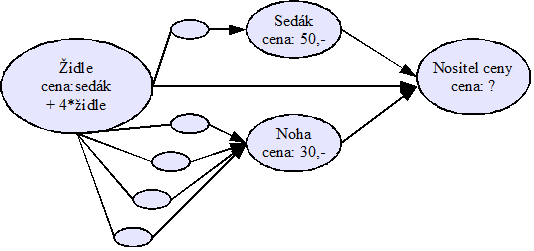
Takže například nás sedák stojí 50 korun, nohy třeba 30 a hodnota celé židle je funkcí komponent a dalších, zde pro jednoduchost vynechaných, vztahů.
Je zřejmé, že náklady jsou funkcí různých typů vstupů:
kdo? ..cena pracovní síly
kde? ..cena nemovitostí, půdy
co? ..spotřebovaný materiál
čím/na čem ..cena výrobního zařízení a dalších tech. prostředků
Kombinacemi různých odpovědí na uvedené otázky (například majetkovými vztahy k výrobním prostředkům, místem výkonu práce..) lze definovat takové pojmy jako prodej, hosting, outsourcing. Kalkulační modul by mohl díky sémantickému porozumění složkám cen počítat i ceny variant dodávky v tomto smyslu.
rozšiřující modul stanovení cen
Náklady spočítané modulem kalkulace nákladů mohou případně sloužit i jako základ mechanismu automatizovaného stanovování prodejních cen různě kombinovaných a parametrizovaných produktů.
Zapomenout nesmíme na různé slevy (množstevní, slevy vybraným partnerům), provize a další obchodní a marketingové nástroje.
V této fázi nemá cenu definitivně volit konkrétní technologie, ale mohu se podělit alespoň o subjektivní dojem. Největší šance dávám technologiím okolo jazyka Java – jazyk je to multiplatformní, výkonný a disponuje vším potřebným pro tvorbu robustních serverových aplikací. Více viz poslední část práce.
U modulů prezentačních je třeba postupovat opatrně. Nejžádanější podobou zákaznického rozhraní bude zřejmě klasické rozhraní webové. Nelze ale opomenout prohlížeče různě atypické – například mobilní telefony a PDA.
Dále musíme počítat s lidmi hendikepovanými, například slabozrakými (rozhraní s velkým písmem), barvoslepými (volby kombinací barev), úplně slepými (hlasové rozhraní). Řešením pro budoucnost by bylo postavit uživatelské rozhraní na vhodném nástroji pro generování různých rozhraní z modelu, například Xermes [XERM].
U prototypu možná zvolíme snadnější cestu v podobě jednoduchého webového rozhraní. Bude to řešení provizorní, na druhou stranu, budeme-li důsledně oddělovat UI od logiky (jádra, transakčního modulu..), cesta pro výměnu rozhraní za kvalitnější podle potřeby a bez zásahů do dat zůstane otevřena. Univerzálnost administračního rozhraní není tak klíčová (prozatím postačí jednoduché webové nebo dokonce klasické okenní rozhraní), ale časem by se s ní rovněž mohlo počítat..
Pro datové úložiště bude nejvhodnější použít abstraktní perzistenční vrstvu typu [OJB]. Transakční modul je vlastně trochu složitější implementací návrhového vzoru naslouchač (listener - viz [GHJV95] a [BMRSS96]) v čisté Javě. Vlastní rozhraní do dalších programů zkoumat nebudeme – již nepatří přímo do navrhovaného systému. V případě vzdálených aplikací bude vhodné využít některý ze standardů pro meziprogramovou komunikaci, například již zmíněný SOAP, u aplikací postavených na Javě možná RMI, u ostatních CORBA.
Jak je již jistě zřejmé, základem jádra programu bude sada ontologií a podpůrných knihoven pro práci s nimi. Implementace prototypu těchto nástrojů je námětem dalších, již ryze praktických, částí práce
Pokud studie proveditelnosti neprokáže, že nemá smysl systém vyvíjet, tak dlouhodobým cílem je samozřejmě co nejšířeji akceptovaný nástroj produkční kvality. Pro nejbližší budoucnost budeme ale skromnější a spokojíme se s prototypem následujících parametrů:
funkční a v zásadě použitelné jádro postavené na vlastních obecnějších nástrojích pro práci s ontologiemi, ovšem bez pokročilejších schopností vyhledávání a inteligence
základní zákaznické webové rozhraní
perzistenční vrstva schopná integrovat více datových úložišť pro ukládání ontologií
spartánské administrační uživatelské rozhraní
Takový prototyp bychom rádi vyzkoušeli na vybraných projektech skutečných elektronických obchodů.
Zatím pouze zvažuji, zda rizika nejsou příliš značná a tedy zda se vůbec vyplatí systém vyvíjet. Souběžně provádím analýzu – zkoumám prostředí, ve kterém by byl systém případně nasazován a snažím se odvodit další klíčové charakteristiky, které by mohly promluvit do analýzy proveditelnosti, a to jak na straně nákladů, tak případných přínosů a z nich plynoucího zájmu uživatelů, investorů...
Ontologie zde vystupuje především v roli meta systému, ale má i některé rysy samohodnotné. Zjevně musí být schopna pojmout (v podobě odkazů nebo i nějak těsněji) existující propagační materiály, obrázky, příklady, obchodní informace apod., a to zejména tam, kde by se na ontologické řešení postupně přecházelo z nějakého konvenčnějšího systému.
Na druhou stranu zároveň značnou dávku informace obsahuje ontologie sama o sobě a lze si představit i elektronický obchod plně vybudovaný na ontologii, který by se bez externích materiálů obešel. Pokud by ontologie obsahovala opravdu vše podstatné, bylo by možné všemožné přehledové i produktově specifické propagační materiály, e-maily, tiskové zprávy, ale i různé formuláře nebo třeba ankety vhodnými transformacemi naopak generovat. Základem by byly výsledky vhodně položených dotazů v kombinaci se šablonami vizuálního stylu. V takovém případě již půjde o ontologii čistě samohodnotnou.
Z požadovaných vlastností vyplývají také další nezbytné charakteristiky ontologického meta modelu:
skládání na různých úrovních
Jeden produkt může být složeninou jiných, a to obecně, na úrovni konceptu anebo u instancí, s udáním konkrétních verzí.
násobnost vazeb
Zejména u vztahů „součástí“ mezi instancemi produktů vynikla potřeba stanovení jeho kardinality.
Mám na mysli možnost definovat to, že židle zahrnuje čtyři nohy, aniž by bylo nutné v systému evidovat opravdu čtyři instance konceptu noha a čtyři související vazby – tedy nebude-li takové řešení v konkrétním případě vhodné z jiného důvodu.
U židle by ještě problém nebyl tak palčivý, větší potíže by nastaly tam, kde je třeba materiál (látku) odvažovat či odměřovat, případně kde stejných komponent není pár, ale třeba tisíce.
události
Ontologický systém musí generovat hlášení o probíhajícím dění (události) a rozesílat je přihlášeným naslouchačům. Je to klíčová schopnost zejména pro funkci transakčního modulu, bude se ale asi hodit i při implementaci uživatelského rozhraní.
Transakční systém by měl disponovat poměrně bohatou hierarchií různých typů událostí, aby pokryly veškeré zajímavé dění, nejen úpravy, ale i čtení. Naslouchači musí dostat možnost registrovat se k vybraným událostem, aniž by byli obtěžováni událostmi pro ně nezajímavými.
sledování času
Zejména v souvislosti s procesy poptávek, objednávek, nákupů apod. bude třeba evidovat okamžik jejich vzniku. Sledování platnosti určité informace bude mít svůj význam třeba i u definic produktů – aby bylo zřejmé, kdy byla která vlastnost zveřejněna, jak dlouho zůstala, kdy se změnila apod.
Takové informace budou hodnotné pro zákazníky (bude je třeba zajímat vývoj nějakého produktu aby odhadli, co se s ním bude dít dále), také pro provozovatele – jako podpůrná informace při vyřizování reklamací, obnovování smluv...
Shrnuto, hodila by se obecná podpora sledování změn v čase nejlépe s možností návratu k předchozím verzím.
Inspirací mohou být schopnosti databáze ZoDB aplikačního serveru [ZOPE] nebo třeba systémy Wiki.
dynamické vlastnosti, možná dokonce metody
Například pro cenové kalkulace bude velmi praktické, pokud budou instance ontologií disponovat vlastnostmi, jejichž hodnota bude dána nikoliv výslovně, ale vhodným funkčním vztahem či pravidlem.
Konkrétní hodnota takové vlastnosti (například číselná) bude na dotaz zjišťována aplikací funkčního vztahu na vhodné hodnoty té samé instance nebo instancí souvisejících.
Například pokud cena židle bude dána jako součet cen zahrnutých komponent. Při dotazu na cenu židle systém projde graf, vyhledá komponenty, jich se zeptá na cenu a zjištěné hodnoty dosadí do funkce, která vrátí výsledek...
Vyšším stupněm jisté „objektovosti“ instancí v ontologiích by byla podpora metod – nějakých obecnějších předpisů, které by již nesloužily výhradně počítání hodnot dynamických vlastností, ale například by nějak ontologií manipulovaly. Zatím nechám na zvážení, zda jejich přínos převáží potíže plynoucí z vyšší složitosti.
základní sémantické souvislosti
Ontologie by měla umožnit definici synonym, antonym, komplementů a antagonismů...
Pokud zákazník zatouží po pramenité minerální vodě, měla by mu být nabídnuta třeba praktická sada sklenic.. Pokud bude hledat housky, které zrovna došly, můžeme mu navrhnout rohlíky.
Také je zřejmé, že pokud hledá „hosting s podporou JSP“, je to to samé jako „hosting s podporou Java Server Pages“ nebo možná i „hosting s podporou Javy“.
vlastnosti
Velký důraz bude kladen na možnost precizně popsat vlastnosti.
To nás vrací k myšlence kombinovat ontologii s rámci.
internacionalizace
V našem stále se zmenšujícím světě stále roste potřeba vyjít vstříc zákazníkům ze všech možných zemí, mluvících rozličnými jazyky, zvyklých na různá prostředí, prostě všemožně jiných. Systém by jim měl nabídnout popisy, charakteristiky, souvislosti, to vše v jejich jazyce. Kromě přímých překladů je dále třeba pamatovat na různé měrné soustavy, časová pásma a další komplikace. Ontologický model s tím vším musí počítat.
verze
Tento bod možná trochu souvisí se schopností zachycovat čas. O co jde?
Konkrétní produkt prochází svou vlastní historií – od prototypů a testovacích modelů, pokračuje v různých verzích, končí jako výběhový typ. Celou dobu ho tvůrci udržují v konkurenceschopném stavu neustálým doplňováním, vylepšováním.
Podpora verzí je pro aplikaci ontologie v elektronickém obhodě poměrně důležitá, zároveň ale přináší některé komplikace, které si vyžádají ošetření. Jak například naložit se vztahy, které novější verze „zdědí“ od starší? Asi nic zvláštního – prostě ji zdědí. Přidat novou vazbu u novější verze také půjde snadno. Co ale když novější verze nebude mít nějakou starou vazbu obsahovat? Bude tedy třeba vypracovat vhodný mechanismus nedědění nežádaných vazeb, případně rušení vazeb již zděděných.
vazby ven
Poměrně běžnou potřebou jistě bude zapojit do ontologií konvenční data – elektronické podoby propagačních letáků, prezentací, fotografií, url...
Ontologie musí být také dostatečně otevřená, aby se snadno propojila s ontologií jiného systému, a také s například podnikového informačního, adres
dilema instance a probublávání vlastností
Nejsem si úplně jistý, zda má praktický význam explicitně rozlišovat koncepty a instance.
Jak to? Instance je z jiného úhlu pohledu může být konceptem.
Například, uvažuji-li hierarchii skripty-JSP, mohu JSP považovat za instanci (vždyť jde o konkrétní skriptovací jazyk).
Na druhou stranu mohu JSP považovat za koncept a až konkrétní verzi specifikace za instanci. Anebo mohu i verzi specifikace považovat za koncept, a jako instanci chápat až konkrétní implementaci (třeba Apache Tomcat) nebo třeba konkrétní využití (zakázku, webovou stránku v JSP apod.).
Jaký je vlastně rozdíl mezi vztahem dědičnosti (isa) a vztahem implementace v říši ontologií?
Nebylo by univerzálním řešením něco, co nazvu a budu dále nazývat „probubláváním vlastností“? Mám na mysli takový mechanismus, že dokud není vlastnosti v hierarchii přidělena hodnota, je hodnota „pasivní“ a celý koncept abstraktní (skript:[model:string]) a až po doplnění všech pasivních hodnot (jsp:[model:push]) se z konceptu stává instance.
K těmto otázkám se jistě ještě vrátíme.
Nastínil jsem, myslím, docela zajímavý meta model ontologií, který možná zaslouží i své vlastní označení. Říkejme mu v dalším textu charakterizační sítě.
Klíčovým konceptem bude zřejmě produkt a rodina konceptů souvisejících – takových, které umožní produkt popsat, zařadit ho do kontextu jiných produktů, stanovit jeho parametry apod. Další koncepty, jako třeba zákazník, dodavatel, správce, případně cena, nositel hodnoty, zakázka, objednávka, poptávka souvisejí s procesy, které by systém mohl ale na druhou stranu zejména v prvních verzích nemusel podporovat formou rozšiřujících modulů.
Důležitou skupinou vazeb budou různá skládání (židle integruje nohy), dále alternativy (houska – rohlík), komplementarity (ke kávě cukr), antagonismy.. Spousta vazeb přichází v úvahu s již zmíněnými procesy poptávání, objednávání, administrace apod.
Nebudu zabíhat do zbytečných detailů, ale zmíním pár bodů specifičtější případové studie obchodu se službami webového a poštovního hostingu. Dejme tomu, že by bylo cílem poskytovat produkty, které byly zhruba shrnuty takto:
obecné a základní služby
monitorování a servis
zálohování dat
služby spojené s doménovým jménem
doména druhého řádu
subdoména
alias k doméně
služby elektronické pošty
poštovní schránka (umožní cizím SMTP serverům umístit zprávu)
přístup k poštovním schránkám prostřednictvím IMAP
přístup k poštovním schránkám prostřednictvím POP
webové rozhraní pro poštu
alias k e-mailu
automatický odpovídač
přesměrování pošty na e-mail
přesměrování pošty na mobil
základní webhostinové služby
SSH přístup pro upload (SCP/SFTP)
upload přes prohlížeč
ankety
kniha návštěv
modifikace chyby 404
statistiky přístupů
odesílání formulářů
obchod
WAP
aktivní technologie pro webhosting
PHP
CGI
JSP a servlety
Perl
PHP
řešení založené na xml obsahu
prezentační framework
dynamické xml řešení (Apache Cocoon)
relační databáze
PostgreSQL
MySQL
HSQLDB
Firebird
jiné databáze
objektová databáze
XML databáze
Jak by vypadalo ontologické pojetí takového portfolia? Zkusím na zkoumaném příkladě naznačit postup tvorby ontologie. Postup by šlo jistě zpřesnit a zobecnit a vytvořit příslušnou metodiku. Tak tedy:
virtuální produkty
Pokud bychom požadovali, aby systém rozuměl vztahům mezi produkty (aby například mohly fungovat kvalitní cenové kalkulace), bylo by v první řadě třeba doplnit virtuální produkty, které vhodně vyjádří (s)potřebu zdrojů.
Produkt hosting místa by vyjadřoval kolik prostoru na disku serveru je třeba pro data zákazníka. Hosting konektivity by zase vyjadřoval kapacitu Internetového připojení. Podobně by bylo možné vyjádřit třeba spotřebu výpočetní kapacity serveru.
závislosti (kompozice)
Dále bychom museli stanovit kompozice jednotlivých produktů – vazby, kdy jeden produkt vyžaduje produkt jiný.
Například dynamické technologie nemají smysl bez obecného webhostingu. Webhosting nelze poskytovat bez hostingu místa na disku a konektivity. Místo na disku budou vyžadovat rovněž produkty databázové...
konceptualizace
Dalším krokem by bylo logické rozlišení konceptů a instancí – byť není zatím jisté, zda má smysl rozlišovat je na technologické úrovni, pro pochopení vztahů je to při návrhu praktické – a vyhledání vztahů dědičnosti mezi nimi.
Tedy například podtypem konceptu databáze by byl koncept relační databáze (a stejně tak objektová databáze a XML databáze). Instancí nebo dalším podtypem relační databáze by byly konkrétní podporované systémy – PostgreSQL, MySQL apod. Webové rozhraní, IMAP a POP jsou všechno podtypy konceptu přístup k poště...
další vztahy
Dále by bylo vhodné explicitně stanovit takové další zajímavé vztahy, které přímo nevyplývají z charakteru konceptu a dědičností.
Je třeba zřejmé, že PHP a JSP jsou alternativy, protože obě technologie by byly subkonceptem aktivní technologie.
Šlo by především o alternativy, komplementarity apod.
cenové předpisy
Jednotlivé produkty by bylo třeba ohodnotit, aby kalkulační model mohl počítat ceny. Některé produkty by dostaly ohodnocení paušálem (konstantou), jiné funkčním vztahem.
Hosting místa v závislosti na počtu obsazených megabajtů, poštovní služby podle počtu schránek apod.
Pro opravdu robustní cenové modely by přibyla ještě část ontologie definující jednotlivé zdroje a jejich ceny, ze které by cenotvorné funkce u produktů vycházely.
detaily o produktech
Samozřejmě nelze zapomenout na vlastní charakteristiky produktů – jak se jmenují, v jaké verzi jsou nabízeny, kdo je vytvořil (čí je technologie a čí konkrétní realizace), nějaké recenze, popisy, hodnocení.. ale také nápady, postřehy, vazby na diskuze uživatelů apod., tedy všechno to, co je zvykem o produktech uvádět i u konvenčně řešených obchodů.
Na následujícím obrázku je znázorněn kousek ontologie. Šipky vyjadřují dědičnost, kolečka nezbytnost (závislost, kompozici) – koncept s kolečkem musí být přítomen (prodán, zahrnut do nabídky apod.), aby koncept na druhé straně vztahu mohl existovat.
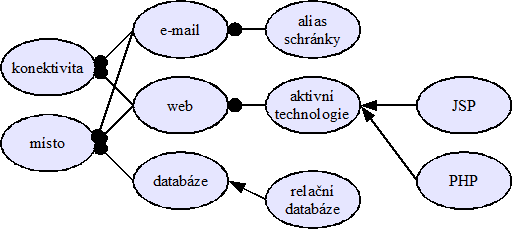
Představte si Linuxový server pro poskytování mnoha služeb. Je to server složený z velkého množství vzájemně nezávislých softwarových komponent.
Nemyslím si totiž, že je dobré, když jeden program umí všechno – kromě toho, že pak většinou sice dělá všechno, ale nic pořádně, přináší to často také řadu dalších problémů. Například problémy bezpečnostní – pokud je kompromitována jedna služba, jsou automaticky kompromitovány i ostatní. Tvůrci monolitů mají také tendence obcházet standardy a nahrazovat je svými proprietárními řešeními, čímž zákazníka napevno k ke svému produktu – to je z pohledu dodavatele pozitivum, ale uživatel trpí – stává se závislým.
Nuže, máme server z komponent – komponent otevřených, respektujících standardy, bezpečných, schopných dobře plnit své poslání. Oproti řešením monolitickým má ale taková „skládačka“ také nevýhody. Prakticky všechny podstatné lze shrnout pod pojem komplikovaná správa.
Jak jsme již zmínili, zvažujeme využití nezávislých komponent. To, že jsou nezávislé obvykle znamená, že je vytvářeli různí vývojáři, podle různých zásad. Každá taková komponenta vypadá jinak, chová se jinak a především se jinak konfiguruje a spravuje.
V prostředí Linuxu je zvykem konfiguraci koncentrovat do snadno čitelných textových souborů na jednotné místo v adresářové struktuře. Každý takový konfigurační soubor je ale jiný – některé mají tvar dlouhé řady voleb (Postfix), jiné jsou vystavěny na XML (aplikační server Apache Tomcat), další sice XML na první pohled připomínají, ale jeho standardem se neřídí (HTTP server Apache).
Pokud je třeba zprovoznit prostředí třeba i se základní sadou služeb novému klientu, vyžaduje to různé zásahy do mnoha takových souborů. Kromě toho je možná třeba vytvořit nějaké adresáře, založit databáze, poštovní schránky... Ještě komplikovanější může být zprovoznění nové služby většímu množství stávajících zákazníků.
To vše lze zvládnout ručně, ale je to otravná práce, náchylná k chybám. Navíc, a to považuji za ještě závažnější, v případě budoucích změn (například zákazník odejde nebo požaduje kompletně jinou sadu služeb) je třeba vrátit všechny úpravy provedené při zakládání. Jednoduše řečeno – ruční administrace je pracná, časově náročná, není škálovatelná, nepružná – je prostě špatná
Pak tady existují různé pokusy, jak správu zjednodušit. Například můžete použít jednu z mnoha grafických nadstaveb, třeba Webmin. Ty ale obvykle nejsou ničím jiným než právě takovou nadstavbou – jejich prostřednictvím lze provádět úpravy v jednotlivých konfiguračních souborech služeb. To ale neřeší náš problém – potřebu integrovat správu tak, aby jeden úkon (přidání zákazníka, odstranění zákazníka, povolení virtuální služby „pošta“...) byl automaticky, bezpečně (s různými validacemi) promítnut do konfigurace více služeb.
Spousta administrátorů se nakonec uchýlí k tomu, že si vytvoří systém jednoduchých, ale účinných skriptů, které potřebné úkony provádějí za ně, a na který jsou pak náležitě pyšní. To je v současné době asi nejlepší řešení, ale stále je špatné.
Především, je plýtváním pracovní silou vytvářet něco obecně použitelného pouze pro sebe. Dále, takový racionálně uvažující autor zvažuje svůj čas vynaložený na tvorbu skriptů a porovnává ho s přínosem, který mu skripty přinesou. Je proto logické, že neimplementuje dokonale automatizovaný systém, ale spokojí se s automatizací toho nejvíce se opakujícího, případně toho, v čem dělá nejvíce chyb.
Například já jsem si na serveru který spravuji vytvořil sadu skriptů pro přidávání zákazníků, protože to se děje docela často, ale změny a odstraňování konfigurace provádím ručně.
Pokud by tady byl systém, který by sloužil spoustě administrátorů, celkové náklady a přínosy by se vyrovnaly někde u mnohem dokonalejšího řešení. Proč tedy takový systém již neexistuje? Potíž je v tom, že když skládáte server z nezávislých otevřených komponent, máte neskutečně mnoho možností, jak to udělat – máte na výběr řekněme ze třech SMTP serverů, čtyř POP a IMAP serverů, třech webových serverů, pěti doménových serverů, dvou SSH serverů, snad několika desítek relačních a jiných databází...., spousty různých modulů a rozšíření, to vše v mnoha verzích a modifikacích.. Posoudíte parametry a vyberete to pro vás nejvhodnější. Nakonec napíšete hrst jednoduchých ale účinných skriptů, přesně pro tu vaši kombinaci – jednoduše proto, že se vám to vyplatí. Nevyplatí se vám ale vytvářet skripty univerzální, protože to by byla již řádově složitější úloha.
Myslím že ontologie by byla vhodným základem maximálně flexibilního systému pro správu nezávislých softwarových komponent. Veškeré klíčové informace o zákaznících a jimi požadovaných službách a jejich parametrech by mohly být primárně zachyceny ontologicky a až od tohoto základu by byly odvozovány konfigurace jednotlivých služeb. Přineslo by to například takové výhody:
přirozená integrace
Integrace by nebyla realizována jako dodatečné „slepení“ nesourodých konfigurací, ale byla by pojata vnitřně integrovaně. Jeden pohled na ontologii by vybral vše, co se týká zákazníka. Jiný pohled by zase sledoval konkrétní službu. Celek by byl vnitřně provázaný.
abstrakce
Administrátor by byl „odstíněn“ od konkrétní technologické realizace jím spravovaných služeb. Nemusel by tolik řešit technologické detaily, ale soustředil by se více na to, co je skutečně důležité – správu požadavků, funkcí, vztahů, definici toho kdo a co a nikoliv jak. Rozhraní by mohlo vypadat prakticky stejně, i kdyby na pozadí obsluhovalo úplně jiné programy.
snadný přechod
Jakmile zahlédnu závislost na konkrétní technologii, řešení, produktu, firmě apod., tak zbystřím – závislostem je třeba se vyhýbat, protože přinášejí rizika. Co se stane, když dodavatelská firma zkrachuje? Když vývoj bude ukončen? Když program přestane stačit?
Pokud budou klíčová data v nezávislém formátu (v ontologii) a konfigurace konkrétních nástrojů bude pouze projekcí těchto dat do specifických šablon, záměnou šablon bude možné bezbolestně, tedy bez zásahů do dat, přejít na jiný systém. Zatím neznám žádný administrační nástroj, který by něco takového obecně umožňoval.
Na následujícím obrázku je naznačena integrace jednotlivých služeb – nejprve zobecnění konkrétního serveru (Posftix..) jako implementace nějaké technologie (SMTP). Pak shrnutí technologií v rámci určitých rodin – mezi jejich členy bude mno dat sdílených. A jako finální integrační vrstva rozhraní, které překlene bariéry i mezi rodinami a umožní sdílet i tak univerzální údaje, jako třeba doménové jméno.
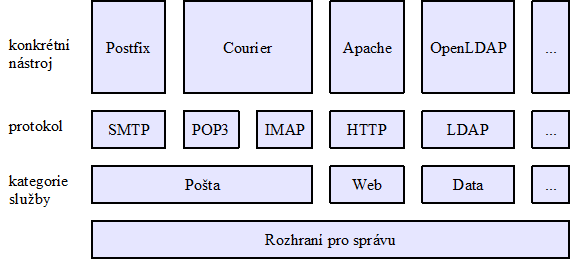
nevhodnost ontologií
Univerzální, nezávislý nástroj pro správu serveru by byl užitečný – to je myslím mimo jakoukoliv diskuzi. Je tady ale určité riziko, že ontologie nejsou tím nejvhodnějším způsobem reprezentace dat.
Možné to je, ale dovolím si tvrdit, že jsou pro toto užití přinejmenším vhodné.
nevhodnost technologií
Mohlo by se stát, že některá použitá technologie nebude vyhovovat prostředí serverů – svými závislostmi na jiném softwaru, svou nedostatečnou otevřeností, platformní závislostí apod.
Toto riziko je třeba mít na paměti při návrhu systému a stále si pokládat vhodné otázky..
komplikace přechodu
Nebude snadné převést nastavení stovek či tisíců účtů různých služeb do podoby ontologie.
psychologické zábrany
Jak mohu soudit z komunikace s některými zkušenými správci UNIXových serverů, jsou to obvykle lidé nadprůměrně inteligentní a také dosti sebevědomí. Jsou pyšní na své znalosti technologií se kterými pracují a mají obecně odpor ke grafickým rozhraním, konfiguračním pomáhátkům a dalším kusům softwaru, o kterých s oblibou prohlašují, že je pro neschopné..
Mnohdy také, co si nenaprogramují sami, tomu často nedůvěřují. A za roky své praxe si již vytvořili obstojná, ale nikoliv univerzální prostředí pro správu. Svému systému dokonale rozumí, ale nerozumí mu prakticky nikdo jiný, díky čemuž jsou skoro nenahraditelní – což je dobrá pozice. Dovedu si představit, že podstatné procento správců by se docela zdráhalo navrhovaný systém nasadit.
V té nejjednodušší a nejobecnější podobě by mohla vypadat architektura systému zhruba takto:
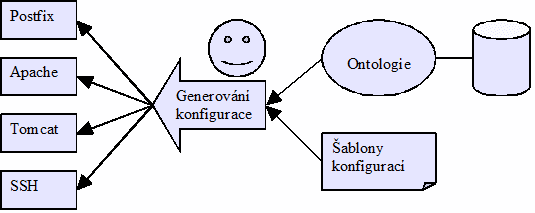
Základních komponent je vcelku málo:
uživatelské rozhraní
V prvních verzích bude stačit primitivní rozhraní v příkazové řádce. Časem by pro vyšší pohodlí mohlo vzniknout webové administrační rozhraní tvořené třídami, které by vhodně vizualizovaly obsah ontologie formou tabulek a přehledů a také by zahrnovalo třídy pro generování formulářů na zadávání údajů a manipulaci ontologií.
ontologie
Jádrem by byla pro změnu opět oborová ontologie. V ní by byly uchovány všechny informace o zákaznících a jimi požadovaných službách. To vše na abstraktní úrovni – bez vazeb na konkrétní programové balíky, které by požadované služby realizovaly.
šablony
V šablonách konfigurací by byla naopak data závislá na konkrétních použitých technologiích, ale nezávislá na zákaznických datech – na informacích o zákaznících, jejich požadavcích apod.
U většiny služeb je třeba v konfiguračních souborech definovat obecné funkční parametry týkající se celé aplikace a také informace specifické podle uživatelů. Pro tyto typy informací by byly definovány dílčí šablony. Části závislé na doménových datech by byly naplněny daty z ontologie a následně spojeny se zbytkem konfigurace.
Konkrétně by ve velké šabloně (se základem konfigurace, tedy definicí obecných parametrů, nezávislých na konkrétních zákaznících) mohl být nějaký symbol či značka, na jejíž místo by se doplnily doménově specifické šablony vyplněné konkrétními daty. Kromě toho by některá z doménově specifických proměnných mohla sloužit jako identifikátor začátku a konce oblasti, aby v případě odstranění záznamu z ontologie bylo možné dohledat příslušná místa v konfiguraci.
Mohlo by to vypadat třeba takto:
…
#mark_start
aaa.cz mark_start
…
#mark_end
aaa.cz mark_end
#mark_appendhere
Určitou komplikací pro proces spojování ontologie a šablon budou obecně vícehodnotové položky – například mailové nebo doménové aliasy. Je třeba na ně pamatovat při volbě či návrhu šablonového jazyka.
modul generování konfigurace
V implementačně nejjednodušší variantě systému by šlo prostě o naplnění šablon daty z ontologie, případně ověření toho, zda existují potřebné databáze, adresáře apod. a jejich vytvoření.
Po každé změně v ontologii by bylo třeba takto zaktualizovat konfiguraci dotčených služeb. Trochu hloupé u takového řešení by bylo to, že i při nepatrné změně by bylo vše generováno znovu. Při velkém počtu uživatelů, případně v nasazení, kde ke změnám dochází často, by asi náročnost opakovaných procesů překročila únosnou míru.
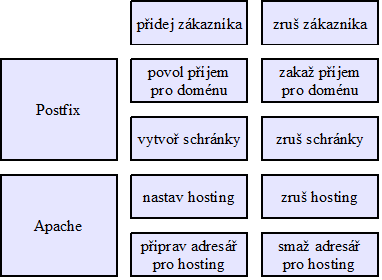 Dokonalejším
řešením by bylo, kdyby systém prováděl
pouze chirurgické zásahy do konfigurace. Architektura
by v takovém případě byla o něco komplikovanější.
Bylo by třeba nadefinovat úlohy jako „přidání
zákazníka“ nebo „zrušení
zákazníka“ a pro jednotlivé podporované
technologie (konkrétní konfigurované aplikace)
vytvořit řetězce úkolů, které je třeba provést
třeba nějak takto:
Dokonalejším
řešením by bylo, kdyby systém prováděl
pouze chirurgické zásahy do konfigurace. Architektura
by v takovém případě byla o něco komplikovanější.
Bylo by třeba nadefinovat úlohy jako „přidání
zákazníka“ nebo „zrušení
zákazníka“ a pro jednotlivé podporované
technologie (konkrétní konfigurované aplikace)
vytvořit řetězce úkolů, které je třeba provést
třeba nějak takto:
Potom, například pří vkládání nového zákazníka do systému by bylo třeba stanovit, které služby mu mají být zprovozněny a systém by provedl všechny úkoly úlohy „přidání zákazníka“ související s požadovanými službami.
kontext
Bavíme-li se o správě, veškeré úpravy budou probíhat v kontextu zákazníka (hostitele) a taktéž instance v ontologii budou ke konkrétnímu účtu patřit. Při výběru kontextu bude pak jasné, které části ontologie mají být zpřístupněny a které skryty.
Takové rozlišení především otevře cestu pro dělbu rolí – různí správci budou moci mít na starosti různé zákazníky, ale především mnoho věcí si budou moci zákazníci přes webové rozhraní spravovat sami. I takové běžné věci jako zapomenuté heslo k některé mailové schránce nebo zřízení dalšího mailového aliasu často řeší hlavní správce. Je to plýtvání jeho časem, navíc možná by bylo i pro zákazníka pohodlnější, kdyby měl nad svým účtem přehled a mohl jej snadno spravovat.
transakce
Veškeré prováděné úkoly by měly být propojeny transakčním návratovým mechanismem pro případ chyby. Pokud se nezdaří dílčí úkol, měl by být systém navrácen do stavu před spuštěním úlohy, tedy všechny úspěšně provedené zásahy by měly být znegovány.
Třeba v případě úlohy „přidávání zákazníka“ pravděpodobně voláním příslušných úkolů úlohy „zruš zákazníka“.
sanity check
Pro zvýšení spolehlivosti systému by každý skončený úkol měl provést explicitní kontrolu úspěšného splnění (např zda vytvářený adresář opravdu existuje) a v případě negativního výsledku nahlásit chybu, která by spustila řetěz navracení.
obsah úkolů
Vlastní úkoly by mohly mít podobu nezávislých skriptů, v rámci kterých by bylo možné používat předem dohodnuté proměnné systému. Některé skripty by generovaly dokumentaci, jiné by vytvářely adresáře, další by volaly nějaké externí programy pro manipulaci poštovními schránkami apod.
řetězce závislostí
Mezi úkoly bude také třeba definovat závislosti.
Například že nelze spouštět úkol nastavení webhostingu pokud ještě nebyl vytvořen adresář pro budoucí prezentaci s provizorní stránkou, která o tom informuje.
Vlastní proces přidání zákazníka do ontologie by mohl spustit příslušný řetěz úkolů. Jak již bylo naznačeno, pokud kdekoliv dojde k chybě, bude třeba vrátit se do stavu na začátku.
Spolupráce jednotlivých komponent by mohla vypadat třeba tak, jak je znázorněno na stylizovaném diagramu sekvencí:
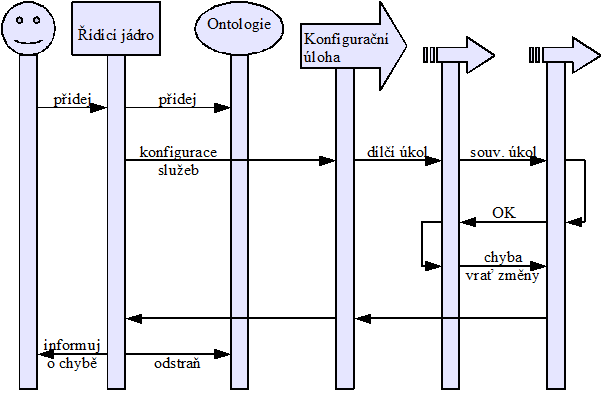
V odpověď na modifikaci ontologie je spuštěna konfigurační úloha. Ta volá první úkol z řetězce. Úkol potřebuje, aby byl nejdříve splněn jiný úkol, na němž závisí, tak ho tedy zavolá. Druhý úkol proběhne úspěšně a vrátí řízení úkolu prvnímu. Ten ale z nějaké vnější příčiny selže. Proto bude třeba vrátit řízení závislému úkolu, aby po sobě odčinil vše, co vykonal a nakonec bude upravena ontologie (aby byla stále zachována konzistence mezi konfigurací a ontologií) a o neúspěchu informován uživatel.
Ve skutečnosti jsou v nastíněném postupu určitá zjednodušení. Například úkoly rekonstruující stav před prováděním nebudou totožné s úkoly samotnými. Dílčích úkolů bude podstatně více a vzájemné závislosti budou komplikovanější. Pro zvýšením robustnosti by také před každým úkolem a po něm měly být prováděny kontroly, takže celý proces provedení dílčího úkolu by měl podobu sekvence činností:
nastav
prostředí pro úkol
zkontroluj
současný stav
proveď
všechny závislé předběžné úkoly
proveď
úkol
proveď
navazující úkoly
zkontroluj
stav
Komplikovanější by byl rovněž dialog mezi řídícím jádrem a uživatelem. Mohl by probíhat třeba takto:
uživatel:
chci přidat zákazníka
jádro:
musíš vyplnit jméno a
příjmení, doménu...
uživatel:
tady to je – Franta Novák, franta.cz...
(ověří
dostupnost domény, provede pár dalších
kontrol)
jádro:
vyber, jaké služby bude požadovat
uživatel:
poštu a web
jádro:
dobrá, přidávám ho do ontologie, spouštím
úlohy přidání pro web a poštu..
(dopočítává
další proměnné podle potřeb úlohy,
spouští
jednotlivé úlohy, provádí kontroly..)
Trochu jiná a možná flexibilnější architektura by spoléhala na naslouchače. Každá podporovaná služba by se zaregistrovala v ontologii k odebírání konkrétních hlášení o změnách. Jakmile by změna nastala, automaticky by spustila příslušné úlohy (skládající se z dílčích úkolů).
Výhoda takového řešení by spočívala především v maximálním oddělení obslužného a řídícího jádra s ontologií od adaptérů pro jednotlivé služby. Přidávání dalších služeb by bylo snazší, jádro by mohlo zůstat nedotčené.
Každopádně jde o typickou samohodnotnou ontologii – veškerá doménová data jsou přímo její součástí. Mnoho parametrů je shodných s těmi, které již byly identifikovány u předchozích příkladů. Proto se zmíním jen o těch nejzásadnějších, nesamozřejmých anebo zatím nepříliš zdůrazňovaných parametrech.
čas a změny
Pro účely fakturací by bylo praktické evidovat od kdy je která služba poskytována, možná i od kdy do kdy je zaplacena. To přináší potřebu evidovat změny v čase a také čas samotný.
naslouchači
Nezbytným parametrem u naznačené flexibilnější varianty bude podpora naslouchačů pro vybrané části ontologie.
Například když se změní cokoliv v konkrétním kontextu, dozví se to naslouchač, který shromažďuje údaje pro fakturace. Pokud se změní něco v libovolném kontextu, ale v kategorii poštovních služeb, dozví se to zase příslušný adaptér, který provede aktualizaci nastavení.
Ke každému prvku ontologie (koncept, vazba..) by mělo být možno přidat takový naslouchač. Ten bude sledovat buďto co se děje přímo s konceptem, anebo jeho instancemi (potomky) kdekoliv v podřízené hierarchii.
závislosti
Celým systémem se prolíná potřeba stanovovat závislosti – které moduly se vzájemně potřebují pro správnou funkci, které úlohy předcházejí dané úloze, jaké musí být pořadí dílčích úkolů apod.
Například pro web a poštu je třeba nejprve zřídit a evidovat doménu (byť třeba ne námi spravovanou). Při zřízení webu bude jako doporučená (ale již nikoliv nezbytná) navazující služba nabídnuto zřízení SSH účtu pro přístup a nahrávání stránek apod.
uživatelské datové typy
Praktická by byla podpora
nepříliš běžných datových typů, jako
email, domain
nebo domainentry. Myslím, že
pokud bude možné definovat aplikačně specifické
typy, nezanedbatelně to zvýší robustnost
programu, jeho odolnost proti chybně zadaným hodnotám a
mnohdy to také zvýší pohodlí.
Například
datový typ domainentry bude
obsahovat položky jako:
www A 194.195.157.141
Ve webovém rozhraní by místo jednoduchého rámečku pro zadání textu mohla být zvláštní komponenta obsluhující speciálně tento datový typ, sestávající ze sady rozbalovacích menu a speciálních formátovaných textových polí. Uživatel by tak byl naváděn k zadání správných nebo alespoň syntakticky validních hodnot.
Kromě konceptů vyjadřujících elementární pojmy a vztahy se zde objevují:
služby
Jako kategorie toho, co lze nabízet.
Například:
pošta – SMTP, IMAP, POP3..
web – HTTP, aktivní technologie
databáze – relační, objektové...
komponenty služeb
Kromě služeb samotných bude třeba nadefinovat obecné elementární kategorie, které se v konfiguraci mohou vyskytovat – doména, poštovní schránka..
Komponenty budou mít například takové atributy (naznačeny jsou datové typy a jejich kardinalita):
MAIL:
address email 1..1
heslo pwd 1..1
mailbox dir 1..1
jmeno jmeno:text, prijmeni:text 1..1
alias email 0..n
DOMENA:
address domain 1..1
entry domainentry 0..n
WEB:
address domain 1..1
alias domain 0..n
…
Jak si můžete povšimnout, jsou zde použity nepříliš běžné datové typy, jak byly zmíněny výše.
technologie
Jako implementace služeb, tedy konkrétní nástroje, které je třeba provozovat, spravovat, konfigurovat.
Apache
Postfix
Courier IMAP
...apod.
Technologicky specifické adaptéry by zahrnovaly šablony konfigurací a také specifické konfigurační postupy (skripty). Každý adaptér také ponese seznam jím vyžadovaných dat, zejména těch trvale uložených v ontologii v podobě konceptů komponent služeb.
komponenty technologií
Konkrétní, technologicky specifické realizace obecných konceptů komponent služeb.
poštovní schránka v Postfixu
poštovní schránka v Courieru
doménový záznam v NSD
...apod.
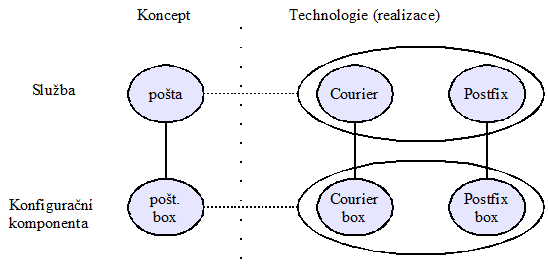
hostitel (zákazník)
Ten, v jehož prospěch jsou služby provozovány. V jeho kontextu budou prováděny úpravy. Vazbami, nejčastěji s kardinalitou n, bude napojen na koncepty jím využívaných služeb.
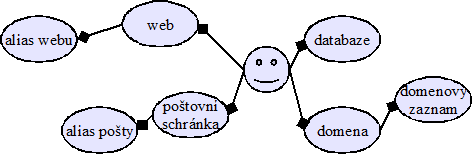
Tedy nějak takto – v obrázku jsou čtverečkem naznačeny násobné kardinality:
Je jasné, že systémy s ontologickým jádrem lze integrovat snadněji. Postupy mapování, spojování a znovupoužití ontologií (zmíněné v teoretické části) jsou dobře formalizované, popsané - známa jsou úskalí i jejich řešení, existují i vhodné manipulační nástroje.
Mnohé integrační možnosti jsem již zmínil výše, nebudu proto zabíhat do detailů. Toto krátké zamyšlení jsem si ale neodpustil, protože považuji ontologie především za vhodné a univerzální lepidlo pro integraci, proto zde shrneme možnosti, které jsme již zmínili a možná naznačíme pár dalších.
Tak tedy - krátce se zamyslím nad perspektivami integrace jednotlivých typů aplikací. Všechny uváděné systémy by mohly těžit z bohatství informací, které ontologie zachycují, a tak by mohly nabídnout vyšší stupeň inteligence, než je běžné. Od drobností opět dospějeme až k vrcholu – k ontologií podpořené virtuální firmě.
systém fakturace
Vhodným propojením systému pro správu serveru a ekonomického informačního systému by mohl vzniknout automatizovaný systém pro fakturace na základě skutečně odebíraných služeb.
CRM
Jak jsme již zmiňovali, pojem nemá jednoznačně definovaný význam, ale obecně se jím rozumí evidence zákazníků, jejich potřeb, jednání s nimi, evidence a správa uzavřených kontraktů, podpora pro marketingové aktivity a pro další činnosti.
Jako základ systému CRM by mohl sloužit adresář informací o zákaznících potřebný již jinde. Nadprůměrná inteligence systému plynoucí z kvalitních údajů v ontologii by se mohla projevit třeba tak, že by systém doporučoval vhodné kampaně na základě statistických dat o zákaznících, jejich činnosti a nákupních zvyklostech. Těsné vazby můžeme hledat také směrem k systémům znalostním – viz níže
sklad a logistika
Informace o zboží z webového obchodu by byly navázány na logistiku a skladové hospodářství. Skladové hospodářství by třeba samo doporučovalo objednání zásob podle vhodného modelu zásob.
správa dokumentů
Ontologie by zde byla v typické meta roli – pouze by popisovala data uložená v jiné podobě. Oproti klasickým systémům pro správu dokumentů by mohla opět nabídnout zajímavé vazby na produkty, zákazníky apod.
řízení workflow, groupware
Ontologie by zahrnovala především adresář kontaktů a pak spoustu konceptů jako „proces“, „úkol“, „cíl“ nebo „schůzka“, „telefonát“. Při vhodném spojení se systémem obchodu by mohly být konkrétní úkoly přidělovány a realizovány zároveň v kontextu zákazníků a kontextu produktů.
systém znalostní
Význam znalostí v konkurenčním prostředí roste. Cílem organizací myslících na budoucnost je uchovat cenné znalosti svých kvalitních pracovníků.
Propojením znalostního systému s CRM by i běžní operátoři na horkých linkách mohli zodpovídat složité dotazy. S kvalitním rozhraním do elektronického znalostního systému by mohl obchodník rychle vyzdvihnout přednosti produktu. Účetní by snadno zjistila, jak má účtovat složitý, ale občas se vyskytující případ...
Nabízí se propojení se systémem správy dokumentů, elektronickým obchodem nebo třeba informačním systémem pro podporu servisu a vyřizování reklamací. Všude by vazby dobře zprostředkovaly ontologie.
podnikový informační systém jako integrovaný portál
To je myslím velkou výzvou v oblasti aplikace možností aplikace ontologií. Tak jako nejlepší server pro poskytování síťových služeb sestává z mnoha otevřených, vzájemně nezávislých komponent, tak by mohl vzniknout podobně komplexní, provázaný a integrovaný informační systém z původně nezávislých kusů.
V oblasti open-source existuje mnoho systémů, které řeší dílčí úlohy klasických informačních systémů. Patří mezi ně například Compiere (CRM a ERP systém) nebo OpenCRX (CRM systém profesionální kvality). Existuje také mnoho účetních programů, programů pro vedení skladové evidence, groupware (OpenGroupWare..) apod. Neznám ale ani jediný, který by byl flexibilní, ale zároveň dostatečně komplexní.
Komunitní způsob vývoje příliš nepřeje podobně rozsáhlým projektům. Výjimkou z tohoto pravidla je třeba monolitický kancelářský balík OpenOffice.org – za ním ale stojí silná společnost (Sun Microsystems), která jeho vývoj podporuje a koordinuje. Mnohem běžnější jsou kvalitně pojaté drobnější projekty. Myslím že ontologie by dost možná mohly posloužit jako společný jazyk a umožnit nezávislým týmům propojit svá díla. Výsledkem by mohl být univerzální a komplexní, flexibilní a integrovaný celek.
integrace subjektů
Zajímavou oblastí jsou možnosti integrace různých subjektů – dodavatelů a odběratelů nebo obecněji spolupracovníků podílejících se na společném velkém díle (zakázce, projektu..). Ontologie by mohly podpořit již existující svazky nebo pomoci při formování nových. Jak vyplývá z úvodu práce a především z části o virtuální firmě, vše to jsou směry, jimiž se obchod téměř jistě bude ubírat.
Zároveň je to bitevní pole, kde konkurence je neobvykle intenzivní – kdo nevyužije maximum technologického potenciálu doby (a ontologie, byť zatím možná ještě v této oblasti nedoceněné do něj jistě patří), neuspěje.
Na základě poznatků načerpaných z případů použití ontologií v různých prostředích nyní stanovíme obecné požadavky dále navrhovaného systému. Pokusím se je vyjádřit stručně a výstižně, aby bylo snadné udržet je v mysli, až se ponoříme do větších detailů. Při stanovování požadavků čerpám kromě předchozího textu také z práce [ASMZEJ03].
univerzálnost, přizpůsobitelnost
Systém musí umět poskytnout cenné služby výše zkoumaným typům aplikací, ale i aplikacím jiným, které jsme podrobně nezkoumali. Na druhou stranu nesmí pro dané použití vnucovat nevhodné a zbytečné funkce.
Klíčem k řešení bude konfigurovatelnost.
použitelnost
Již tuším, že systém bude velmi komplexní. Nesmí to ale být na úkor použitelnosti.
Uživatelská přívětivost: Systém by měl pomáhat uživateli kde to jen půjde a nevyžadovat od něj víc než je nezbytné. V tomto směru bude klíčová opět konfigurovatelnost spolu s mechanismy skrývání.
Snadnost správy: Instalace a konfigurace včetně propojování s dalšími systémy - uživatelským rozhraním, databází a systémy aplikačními - musí být rozumně snadná. Klíčem bude otevřenost, respektování standardů, kvalitní dokumentace.
Snadný vývoj: Při vývoji by měly být používány dostupné prostředky pro udržení přehledu nad projektem, pro a zajištění spravovatelnosti i do budoucna. Důležitá bude kvalitní analýza a návrh, v rámci implementace pak API dokumentace a jednotkové testy. Nesmíme opomenout také volbu vhodné technologie.
nezávislost
Systém musí běžet na všech běžných operačních systémech - Windows, Linux, MacOS… Nesmí být závislý na žádné knihovně nebo aplikaci s restriktivní licencí, která by omezovala jeho další použití. Nesmí být pevně svázaný s žádnou konkrétní databází, aplikačním serverem...
rozšiřitelnost a flexibilita
Musí být otevřený ke změnám a vývoji. Musí být také otevřený pro uživatelské modifikace a doplňky. Kromě toho musí definovat jasná a dobře použitelná rozhraní a mechanismy komunikace, včetně mechanismů hlášení změn v ontologii.
Nebudu se snažit vytvořit jeden překomplikovaný meta model, který by šlo použít všude (ale všude by zároveň překážela spousta nevyužitých funkcí). Spíše systém pojmu jako konfigurovatelný – meta model půjde vybudovat konfigurací pro konkrétní užití.
robustnost
Jakmile bude jednou nakonfigurovaný, měl by kontrolovat a vynucovat validitu ontologie na něm postavené. Nemělo by být snadné porušit integritu ontologie nevhodnou entitou nebo vazbou. Systém by měl kontrolovat veškeré změny a vynucovat dodržování integritních pravidel.
výkon
Výkonové požadavky jsem zařadil až na poslední místo, protože upřednostňuji čistotu návrhu a jsem toho názoru, že výkon je lépe řešit, až když systém funguje správně. Na druhou stranu je třeba mít na paměti, že v reálném nasazení půjde i o výkon, rychlost, spotřebu paměti a podobné parametry.
Ve fázi budování prototypu se ale spokojíme s tím, když budou nároky v zásadě „rozumné“.
Hned od začátku ale budeme pamatovat na budoucí potřebu škálovatelnosti – především co se týče možností ukládat data do více databází, replikovat apod. Prozatím ale ponecháme stranou clustering a rozkládání výpočetní zátěže.
Teď nám již nic nebrání ponořit se do vlastního návrhu. Začneme meta modelem ontologie, časem přejdeme k provozním požadavkům a návrh uzavřeme dekompozicí modulů a vypátráním vhodných technologií. Pak bude následovat již jen implementace prototypu. Pokud práci dočtete až dokonce, myslím že vám bude jasné, že na finální verzi systému si bude třeba ještě chvíli počkat....
Předchozí část zkoumala možnosti nasazení ontologií především tam, kde to dosud není příliš běžné. Předkládala doklady toho, proč jsou ontologie pro dané použití vhodné, jak by systém s jejich využitím mohl fungovat, jak by mohl vypadat. V neposlední řadě jsme dospěli k různým zásadním parametrům ontologického meta modelu právě pro trochu tato atypická využití.
Teď nám půjde právě a především, jak je zřejmé i z nadpisu, o meta model ontologie. Jednoduchou definici tohoto pojmu jsme již uvedli v úvodu práce, sloužila především k odlišení ontologie, jejího modelu a meta modelu. Teď je čas na definici podrobnější:
meta model ontologie
Ontologickým meta modelem rozumím souhrn toho, co ontologie dokáže popsat a jak může fungovat. Tedy její vyjadřovací schopnosti, bez ohledu na konkrétní obsah.
Třeba to, jaké datové typy podporuje v roli atributů, jaké typy vztahů zná, zda umí pracovat s pravidly a jak jsou pravidla definovaná, jaké typy dědičnosti podporuje a tak dále. Jde tedy v zásadě o souhrn parametrů struktury.
Kromě parametrů struktury nás budou zajímat také různá funkční a procesní hlediska – jakým způsobem lze ontologii utvářet, modifikovat, jak se dozvídat o změnách v ní prováděných apod. To bude ale námětem další části.
Je možné, že některé parametry vyvolají spory, zda ještě vůbec jde o ontologii. To ale nepovažuji za důležité – vede mě účelnost. Ať již to pořád ještě jsou ontologie nebo ne, rád bych položil základ flexibilní, univerzálně použitelné knihovny pro práci právě s takovými daty – ať již to ontologie je nebo není. Z klasických meta modelů ontologií přinejmenším vycházím.
Začněme klíčovou položkou struktury – koncepty a instancemi.
Co je to koncept?
koncept
Podle [HMC00] je to všeobecná myšlenka nebo pojem, odvozená ze specifických příkladů nebo výskytů. Něco zformulovaného v mysli, myšlenka nebo představa.
V souvislosti s ontologiemi tato definice docela dobře odpovídá. Mohli bychom ji možná pouze lehce pozměnit a to tak, že jde o formální vyjádření všeobecné myšlenky nebo pojmu.
Koncept je také docela blízký pojmu třída ze slovníku objektově orientovaného návrhu a programování.
instance
Podle stejného slovníku je to případ, příklad nebo výskyt.
U ontologií jde opět o formalizaci informace o takovém výskytu v reálném světě.
A opět můžeme sledovat podobnost s pojmem z objektově orientovaného programování, ten je pro jednoduchost opět instance nebo též objekt.
V případě objektově orientovaného programování technologie jednoznačně vyžaduje takové jasné a jednoznačné rozlišení. Nelze mít objekt, který je zároveň třídou a pokud se to někomu nelíbí, musel by kompletně změnit programovací jazyky a související nástroje.
U ontologií je rovněž běžné takové rozlišení. Podobný je i postup budování ontologie – nejprve se stanoví koncepty, vztahy dědičnosti mezi nimi, pak další vztahy (agregace, ale také třeba synonyma nebo podobnosti – podle možností konkrétního ontologického meta modelu a potřeb řešeného případu). Až poté je čas pro zakládání instancí.
Uvedená struktura i postup mají určitý reálný základ v charakteru světa – pouze postup poznávání je spíše opačný. Okolo nás jsou instance. Pokud ty shrneme do určitých kategorií podle podobnosti, vlastně nadefinujeme koncepty.
Jak jsem ale uvažoval nad možnostmi aplikace ontologií do prostředí elektronické komerce, postupně ve mně začalo hlodat podezření, že takové jednoznačné a ostré rozlišení může být spíše kontraproduktivní.
Vezměme si zboží v elektronickém obchodě, třeba televizi. Je zřejmé že televize je koncept, je subkonceptem „bílé elektroniky“, ta je subkonceptem elektroniky a tak dále. Televize může mít další hierarchii konceptů pod sebou – digitální televize, nebo třeba podle typu obrazovky (CRT, plazma..) Dejme tomu že TV Oravan je konkrétní model klasické televize. Nuže, zaveďme ji jako instanci.
Jako příklad, se kterým budu i dále pracovat jsem si půjčil slavný model Tesly, vyráběný v letech 1960-62: Dvanáctikanálový televizní přijímač - superhet s mezinosným zpracováním zvuku dle normy OIRT (6,5 MHz). Obrazovka s úhlopříčkou 35 cm, na přední stěně vlevo knoflíky pro ovládání hlasitosti s vypínačem sítě, tónová clona, vpravo přepínač kanálů a dolaďování. Pod spodní hranou regulátor kontrastu, řádkového a snímkového kmitočtu, jasu. Na zadní stěně přípojka pro dálkové ovládání jasu a hlasitosti, regulátor zaostření, vyjasňovač, výška obrazu a linearita. Přijímač vyšel z předchozího typu 4102U Mánes, jedná se o první televizor z Tesly Orava vlastní koncepce. První provedení mělo ochranné sklo před obrazovkou s šípovitým tvarem směrem dolů, u poslední série bylo sklo již obdélníkového tvaru a bylo možno ho jednoduchým způsobem vyjmout při čistění od prachu. Přijímač ve své době patřil k nejlevnějším na trhu, stál 2600,- Kčs, pro porovnání televizor Lotos z Tesly Pardubice s úhlopříčkou 53 cm, moderní konstrukcí s plošnými spoji, vychylovacím úhlem 110 stupňů a dálkovým ovládáním stál v téže době přes 4000,- Kčs. [ORAVAN]
U objektového návrhu by nám ani mnoho jiných možností nezbylo. Téměř jistě by se nám nechtělo definovat a udržovat třídy pro jednotlivé nabízené modely – vytvoření nové třídy znamená zásah do programového kódu a určitě není dobrým nápadem běžně takto program upravovat, co víc, mnohdy ani nemáme k dispozici zdrojové kódy.
Jak již bylo naznačeno, u ontologií bychom možná postupovali stejně – vytvořili bychom instanci TV Oravan. Vše by fungovalo k plné spokojenosti. Až najednou...
Výrobce uvede nepatrně modifikovanou verzi TV Oravan+. Jak se s tím vyrovnáme?
Bude třeba ručně přenést veškeré údaje o TV Oravan do této inovované instance a těch pár detailů změnit. Co hůř, pokud výrobce změní nějaký parametr u celé řady Oravan, bude třeba provést dvojí zásah – upravit jak původní, tak i novou instanci.
To je špatné – je to důsledek nepodchyceného vztahu dědičnosti mezi původní a plusovou verzí.
Zdálo by se, že řešením v takovém případě je vytvořit nějakou subinstanci instance TV Oravan.
To ale nelze – do vztahů dědičnosti mohou vstupovat pouze třídy (koncepty).
U objektového návrhu bychom se s tím museli smířit. V případě ontologií by byl problém menší – přeci jenom tvorba ontologického konceptu není takový zásah do vlastního programu jako vytvoření nové třídy...
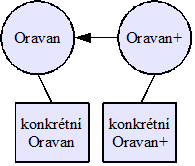
...takže bychom možná povýšili Oravan na koncept a přidali bychom instance původních modelů a od subkonceptu Oravan+ bychom odvodily instance modelů novějších.
TV Oravan je totiž spíše koncept – množina televizorů charakteristických rysů.
Nebo trochu jiný problém. Například jedna konkrétní televize je v něčem výjimečná – má nedopatřením neobvyklou barvu, je trochu kazová, prostě jiná, ale jinak stále ten stejný Oravan. V takovém případě by se nám asi nechtělo vyvářet specifický koncept a pak instanci, asi bychom věc vyřešili nějak provizorně.
Nevím, zda se mi to úplně podařilo, ale snažím se naznačit, že dělící linie mezi konceptem a instancí (stejně jako třídou a instancí) nemusí být úplně ostrá. Pokud bychom postupovali cestou maximální návrhové čistoty, instancemi by byly vždy až konkrétní kusy. Na druhou stranu, takové řešení může v reálných aplikacích působit trochu těžkopádně a udržování příliš mnoha konceptů leckoho odradí – a tak se skončí opět u řešení, kdy za instanci bude považováno něco, co je spíše konceptem.
V praxi se spíše vychází z potřeb konkrétní aplikace. Aplikace udává konkrétní měřítko pohledu; pokud se podíváme blíž (v důsledku situace, která byla při návrhu opomenuta), možná to, co jsme donedávna považovali za instanci budeme muset prohlásit za koncept.
Záměrně jsem vybral příklad z reálného hmotného světa, kde se obecně má za to, že je jasné, co je instance a co koncept. V jiných případech, při definování abstraktnějších pojmů by mohla být situace podstatně složitější:
Třeba v prostředí hostingových služeb - co je instance? Služba, standard či protokol? Jeho verze? Konkrétní program, který realizuje službu? Konkrétní instalace tohoto programu? Nasazení pro konkrétního zákazníka? Všechno? Nebo nic? A je to vůbec důležité? Odpověď, myslím, nemůže být jednoznačná.
Prostě jako lupa – záleží na podrobnosti pohledu.
Je možné úplně se nějak vyhnout naznačeným komplikacím? O objektového programování nelze jinak než postupovat jak bylo popsáno, prostě není na výběr. Ontologický meta model ale není tak striktně omezen, abychom se nemohli zamyslet nad vhodným řešením. Vlastně se jej snažíme navrhnout, tudíž na výběr máme – můžeme striktně a napevno oddělit koncepty a instance tak jako je to v objektovém meta modelu, anebo to nedělat.
Jak by vypadalo řešení bez takového důsledného rozlišení?
Vraťme se k příkladu s televizi. Půjdeme-li po stopách dědičnosti, zjistíme, že subkoncepty se od rodičů vyhraňují několika způsoby:
přidávají nové sledovatelné vlastnosti
U elektroniky můžeme sledovat třeba spotřebu
nově stanovují nebo upřesňují hodnotu nějaké vlastnosti zavedené dříve v hierarchii dědičnosti (a to je v objektovém programování mnohem méně reflektovaná skutečnost)
Dokonce můžou některé vlastnosti či vztahy rušit, což ovšem přinese spoustu dalších problémů. K tomu se ještě vrátíme.
Například pokud všechny televize v našem sortimentu mají záruku 2 roky, můžeme naplnit hodnotu vlastnosti záruka (kterou s sebou koncept nese již od nadřazeného konceptu zboží) konkrétním údajem.
Dejme tomu, že nebudeme explicitně rozlišovat koncepty a instance. Čím se budou technicky lišit jejich formální odrazy v ontologii? Myslím že tím, zda konkrétní odraz (entita v ontologii) má anebo spíše zda může mít vyplněny všechny hodnoty, pokud jsou u ní sledovatelné.
U konkrétní instance totiž můžeme o každé vlastnosti prohlásit jedno z následujícího:
jakou má vlastnost konkrétní hodnotu
případně že nevíme, ale v principu můžeme zjistit
že taková hodnota nelze sledovat
(třeba barva očí u televize – je to spíše známka chybného návrhu)
Možná vám to připadá stále jako nepříliš jasné rozlišení – u konceptů přeci také víme nebo nevíme. Ale u nich připadá v úvahu ještě čtvrtá možnost:
hodnotu sice lze teoreticky sledovat, ale nejsme v principu schopni jednoznačně ji stanovit
Je to sice na první pohled drobná nuance, ale pokud přidáme možnost stanovit, jakým způsobem je hodnota neznámá, bude možné podle uvedených pravidel automatizovaně usuzovat, zda je entita konceptem nebo instancí na dané úrovni podrobností.
Klíčovým přínosem takového řešení bude zjednodušení návrhu ontologie – nebude třeba zkoumat, co je koncept a co instance a řešit naznačená dilemata mezi jednoduchostí návrhu a konceptuální čistotou. Pokud se časem zjistí, že něco, co bylo doposud považováno za instanci je z nového pohledu vlastně spíše koncept, bude stačit doplnit pouze příslušné atributy nebo jejich hodnoty a... to bude vše. Takové odlehčené řešení zvýší flexibilitu návrhu.
Za zmínku stojí i to, že ne všechny běžné ontologie podporují instance – vystačí si pouze s koncepty.
Možnost explicitně rozlišit koncepty a instance bych se ale neodvažoval úplně zatratit. Zabudoval bych ji do systému pouze jako jednu variantu meta modelu. Tak bych tedy prozatím uzavřel dilema instance.
Koncepty a instance budu dál víceméně shrnovat pojmem entity.
entita
Slovník [HMC00] definuje jako „něco, co existuje jako určitá a diskrétní jednotka, fakt existence, bytí, existence něčeho, zvažována odděleně od jeho vlastností“. V našem meta modelu ontologie je jejím základním stavebním prvkem. Shrnuje obvykle rozlišované koncepty a instance.
primitiv
Slovník definuje jako „neodvozený od ničeho jiného, základní, výchozí nebo původní“.
Typickým primitivem v geometrickém významu je bod.
Opět, ontologický význam docela odpovídá – jsou to ty entity, které jsou na vrcholech hierarchií, nejsou definovány jinými entitami.
agregovaná entita
Je entita v konkrétním těsném vztahu k jiné entitě – je její součástí. Agregovaná entita nemůže existovat samostatně bez entity, se kterou je svázána.
V případě profilu s explicitním rozlišením konceptů a instancí můžeme rozlišovat ještě:
konkrétní koncept
Koncept, od kterého mohou být odvozovány instance.
abstraktní koncept
Koncept, od kterého nemohou být odvozovány instance, pouze subkategorie.
Ať již bude meta model jakýkoliv, s budováním slovníku se může začít kdekoliv; případné nezávisle vznikající jednotlivé stromy se postupně pospojují, a tak dají vzniknout výsledné ontologii.
Již dříve jsme rozlišovali ontologie podle toho, zda je v nich zachycena vlastní doménová informace anebo zda pouze popisují nebo nějak organizují informace uložené v jiné podobě.
Zvolil jsem takové trochu podivné slovo, protože jsem neobjevil žádné známé, které by dostatečně vyjadřovalo potřebnou myšlenku. Samohodnotná ontologie má hodnotu sama o sobě. Samozřejmě nemám na mysli, že by musela mít hodnotu bez systému vybudovaného okolo ní nebo dokonce bez uživatelů. Obejde se ale bez vazeb na nějaké externí informace. Sice odráží reálný svět, ale nemá vazby na jiný meta svět – svět dat, informací, dokumentů, databází, médií... Anebo pokud takové vazby má, nejsou klíčové, obraz pouze doplňují.
Jsou ty ontologie, které byly vybudovány nad jinou datovou základnou – sadami dokumentů, multimédií, textů.. Bez jimi popsané základny nemají téměř žádnou hodnotu. Tato základna je primární. Pokud ji odstraníte, můžete s klidným svědomím zlikvidovat i celou ontologii. Meta ontologie popisuje, charakterizuje, kategorizuje, katalogizuje nebo jinak uspořádává externí data.
Typickým příkladem jsou tématické mapy (topic maps).
Je zřejmé, že hranice mezi těmito typy ontologií není ostrá a nejběžnějším případem bude kombinace – ontologie ponese část samohodnotného obsahu a z části se bude odkazovat na externí zdroje. Každopádně meta model musí počítat s možností takového napojení. Musí umožnit definici vazeb na celé dokumenty (nebo jiné datové zdroje), ale také na jejich části – konkrétní odstavce, obrázky, položky v databázích apod.
Bude jistě vhodné zvážit možnosti jazyka XML, především standard [XPATH], případně novější [XLINK] nebo některý jiný.
Při implementaci bude rovněž vhodné čerpat inspiraci z široké oblasti tématických map. Vážně pojatou specifikaci tématických map vypracovalo konzorcium TopicMaps.Org [XTMSPEC]. Jako úvod do problematiky je asi nejlepší článek [PEPP02], který sepsal spolutvůrce již zmíněné specifikace Steve Pepper a možná také článek [GARS02].
externí entita
Tak nazveme externí datový zdroj, který byl propojen s ontologií.
Zdroje mohou být mnoha různých typů, například:
textové dokumenty všech možných formátů (HTML, RTF, PDF, XML, neformátovaný text...), to vše v různých kódováních a znakových sadách)
obrázky
zvukové záznamy
videosekvence
databáze (relační, objektové, XML..)
kvalifikované vazby
Ať již bude uznán za vhodný kterýkoliv standard (což by měl být vždy upřednostňovaný postup), řešení které bude nakonec vybráno musí především podporovat kvalifikované vazby.
I u odkazů na externí zdroje musí být možné stanovit, v jaké roli je externí zdroj vůči ontologii, z níž je odkazováno, nebo lépe přímo vůči konkrétní její entitě. Tedy, zda ontologickou informaci pouze doplňuje, rozšiřuje, přidává nějakou alternativu anebo naopak, zda jde o zdroj primární a ontologie jej pouze popisuje, obohacuje o další souvislosti apod.
celek i části
Vazby mohou propojovat ontologii s celým dokumentem, databází, videosekvencí.. anebo pouze s konkrétním odstavcem, vloženou tabulkou, databázovým záznamem, časovým výsekem videa apod.
Takové propojení bude vyžadovat určité porozumění struktuře podporovaných externí dat.
Hierarchizace v ontologii může být postavena na dvou paralelně využívaných principech.
Umožní volnější definici hierarchie. Definují příslušnost entit k hierarchickém systému kategorií. Kategorizace je realizována vztahy kompozice.
Vhodným příkladem kategorií jsou rubriky v časopise nebo na nějakém publicistickém webu.
Články jsou si více méně podobné, parametry, které u nich můžeme sledovat určují, že jsou součástí stejné třídy entit. Bavíme-li se o hierarchii, jde pouze o to, do jaké přihrádky je redaktor přiřadil.
Příslušnost ke kategorii tedy nezpřesňuje atributy kategorizované entity a ani nedefinuje nové. Ani nevymezuje hodnoty atributů stanovených u předků v hierarchii dědičnosti. Kategorie toho mnoho neumí. Ale mají podstatnou výhodu – jsou jednoduché; na rozdíl od dědičnosti nepřinášejí žádné zásadní komplikace, a to ani když jednu entitu zařadíme do více kategorií.
kontext
Kategorie mohou pěkně definovat kontext.
Pěkným příkladem může být zařazení různých entit ontologie pro poskytování hostingových služeb do kontextu hostitele a zároveň do kontextu služby. Každá taková zaškatulkovaná entita bude patřit jak ke službě, tak k hostiteli, byť nebude ani samotnou službou a ani hostitelem.
V této souvislosti je zřejmé, že pro kategorii by mělo být možné definovat, do kolika kategorií jednoho typu (třeba typ hostitel) může jedna entita patřit.
kruhy
Když uvažujeme o kategoriích jako o analogii přihrádek, je zřejmé, že jejich hierarchie bude mít rysy stromu – kategorie může mít subkategorie a tak až do v zásadě libovolné hloubky.
Vzniká otázka, zda nás taková analogie zbytečně neomezuje – mohly by být ve vztazích virtuálních přihrádek kruhy? Tedy že by jedna krabička byla zároveň v první i ve druhé zásuvce? Přemýšlel jsem nad tím a žádný zásadní problém nevidím – zkusme tedy povolit i kruhy.
identita
Jako praktická se jeví možnost definovat mechanismy jednoznačné identifikace entity v rámci kategorie.
Podobně by bylo praktické umožnit definovat pravidla identifikace entity v rámci hierarchie dědičnosti.
Kromě explicitního zařazení do kategorie bude praktické podporovat automatické zařazení na základě kategorizačního pravidla. Vyhodnocením pravidla budou za běhu entity přiřazeny do kategorií a poplynou z toho pro ně a pro kategorii stejné důsledky, jako kdyby bylo přiřazení explicitní. Při navrhování této funkce jsem se inspiroval především zpětnými kategoriemi v systémech wiki. V úvahu připadají například tyto varianty:
podle výskytu
Každá entita, která disponuje zvoleným atributem nebo kombinací atributů, bez ohledu na jeho hodnotu, patří do vybrané kategorie.
Například cokoliv s vlastností „výhřevnost“ může být automaticky zařazeno do kategorie „palivo“.
podle hodnoty
Každá entita, jejíž konkrétní vlastnost má konkrétní hodnotu patří do vybrané kategorie.
Cokoliv s vlastností „vyžaduje elektřinu“ a hodnotou „ano“ může být považováno za „elektrický spotřebič“.
Dále bychom mohli zmínit kategorizaci na základě vazeb s jinými entitami, na základě postavení v hierarchii dědičnosti... a samozřejmě kombinace všeho uvedeného.
Zachycuje těsnější a ve svých důsledcích mnohem komplikovanější vztah než kategorizace.
Článek je druhem publikace. Stejně tak je dokumentem.
Vztahem dědičnosti entita nabývá anebo může nabývat atributy entity, od které dědí. Nejprve stručně shrnu, co je pro nás teď podstatné a zamyslím se především nad dalšími důsledky a dilematy, které dědičnost přinese.
třída, rodič
Je entita, která ve vztahu k jiným entitám vystupuje nebo může vystupovat jako nadřazená ve vztazích dědičnosti. Vztahy třída-potomek realizují dědičnost.
přejímání atributů
V objektově orientovaného návrhu je běžným zvykem, že potomek zdědí veškeré vlastnosti předka. Podobný mechanismus by měl podporovat navrhovaný meta model.
Pokud entita zboží definovala atribut záruka, pak odvozená entita elektronika jej přejala.
přejímání hodnot atributů
U objektů trochu méně řešený efekt dědičnosti.
Pokud všechny naše televize mají záruku dva roky, není nic systémovějšího než vyplnit hodnotu atributu záruka u entity televize a nikoliv třeba až u jednotlivých modelů.
Konkrétně by přejímání mělo fungovat tak, že za hodnotu atributu specifické entity bude považována první nalezená hodnota tohoto atributu při procházení hierarchií nahoru směrem k obecnějšímu maximálně až k entitě, která atribut zavedla.
Je zřejmé, že pokud entita explicitně definuje hodnotu atributu, hledání se zastaví u ní. Pokud naopak nebude hodnota nalezena až k definující entitě (k té, u které se atribut poprvé objevil), atribut bude mít nedefinovanou hodnotu.
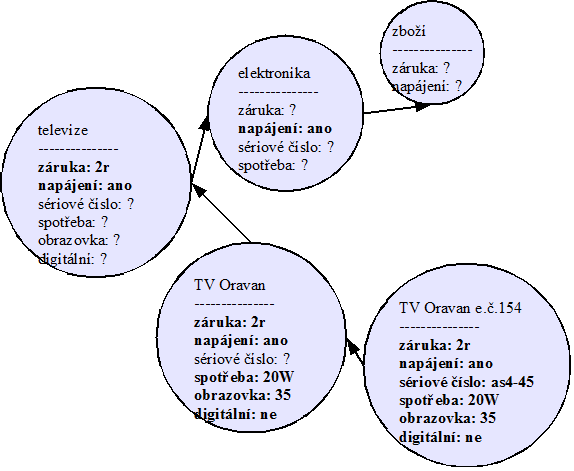
násobnost dědičnosti
Násobnost dědičnosti vyjadřuje, kolik přímých předků může mít jedna entita. Jednoduchá násobnost povoluje maximálně jednoho přímého předka, vícenásobná jich povoluje více.
Zda povolit i násobné vazby, to je docela složitá otázka. Odpověď záleží na váze, jakou přiřadíme jednotlivým kritériím – především flexibilitě plynoucí z násobnosti a jednoduchosti a přehlednosti návrhu v případě jejího zakázání.
Ve světě OOP také není odpověď jednoznačná. Například jazyk C++ podporuje vícenásobnou dědičnost, zatímco novější Java pro třídy nikoliv. Osobně zastávám názor, že zde převažují spíše negativa násobnosti (vyšší složitost a také některé z problémů naznačených níže), k čemuž mě vedou i zkušenosti s uvedenými jazyky, z poslední doby především zkušenosti s návrhem pro jazyk Java. Je pravda, že občas jsem skončil s trochu nečekaným návrhem, ale vždy jsem se bez násobných vztahů dědičnosti obešel a výsledný program je díky tomu i snáze spravovatelný.
U ontologie si zbytečností vícenásobných vztahů dědičnosti zdaleka tak jistý nejsem. Ontologie vidím jako velice flexibilní datovou strukturu, jako prostředek zachycení vztahů a souvislostí světa. Jako takovým by jim, myslím, absence možnosti násobné dědičnosti docela uškodila. Okolo sebe totiž vidíme příklady takového vztahu na každém kroku. S podporou vícenásobné dědičnosti bude také mnohem snadnější ontologie propojovat. Vyhneme se také některým zjednodušením, která musíme přijímat při objektovém návrhu:
Vraťme se třeba k příkladu s televizí. Definovali jsme hierarchii zboží-elektronika-televize.
Vztah elektronika-televize je v pořádku, televize je elektronika. Taktéž zboží-elektronika – prodáváme elektroniku, tak elektronika je pro nás zboží.
Pokud ale opustíme omezené prostředí našeho elektronického obchodu a budeme chtít využít ontologii jako slovník pro domluvu s cizími partnery anebo obecně s kýmkoliv, narazíme na problém.
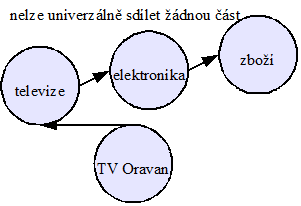
Z jejich pohledu televize zbožím být nemusí. V takovém případě nebudou souhlasit s naší ontologií jako sdíleným komunikačním jazykem, protože vazba zboží-televize by narušila vnímání světa jejich informačním systémem.
Jaký z toho plyne závěr?
Ve sdílené ontologii by měly být zachyceny pouze takové vztahy, které platí dostatečně univerzálně. Vztahy subjektivní musí být odděleny.
Pokud nepovolíme vícenásobnou dědičnost, těžko vyřešíme náš problém ke všeobecné spokojenosti. Řešení nabízí vícenásobná dědičnost. Hierarchii díky ní budeme moci přetransformovat tak, aby univerzálně platné entity nedědily nic od entit subjektivních. Takový stav je totiž jasnou známkou neuniverzálního návrhu.
Řešení s vícenásobnou dědičností:
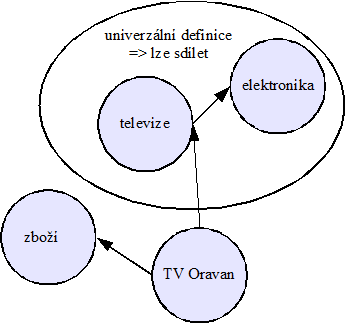
Takové řešení vypadá komplikovaně (a komplikovanější skutečně o trochu je), ale umožní sdílet ontologii s kýmkoliv, což za to myslím stojí.
Koneckonců zboží a televize jsou jiná hlediska charakteru entity TV Oravan, a tak by měly patřit do různých hierarchií.
Vícenásobná dědičnost ale přináší i potíže – kdyby tomu tak nebylo, asi by např. v návrhu jazyka Java nechyběla. Některé z těch, které souvisí s již prozkoumanými tématy zmíníme, o dalších se zmíníme na patřičných místech:
potíže při přejímání atributů
V hierarchii se vyskytne více atributů stejného jména, ale jiného typu. Vzniká otázka, jak situaci řešit.
Jedna možnost je povolit stejně pojmenované atributy a následně podle vkládané nebo žádané hodnoty (jejího datového typu) určovat, o kterým atribut je právě zájem. Atributy by byly jednoznačně identifikovány nejen svým jménem, ale kombinací jména a typu. Navržený postup můžeme nazvat přetěžování atributů. Potíže ovšem nastanou, pokud průnik hodnot přípustných pro použité datové typy nebude prázdný. Je zřejmé, že přetěžování atributů takovou situaci nevyřeší.
Dalším možným postupem by bylo nadefinovat pravidla pro překrývání atributů. Na základě postavení v hierarchii, příslušnosti konkrétní ontologii nebo datového typu určovat, který atribut má mít přednost a který má být u potomků ignorován (nezděděn).
Je tady ještě jedna možnost. Jde o mechanismus, který přinutí vývojáře (návrháře ontologie) situaci v každém konkrétním konfliktním případě explicitně vyřešit – stanovit, co se zdědí a co ne.
Obě poslední řešení jsou sice univerzálnější než řešení první, ale situaci komplikují zase jiným způsobem. Pokud se totiž pro jedno z nich rozhodneme, zaplatíme za to cenu v podobě ztráty jistoty. Nebudeme totiž moci prakticky nic s jistotou prohlásit o jen trochu vzdálenějších potomcích. Veškeré zděděné atributy se totiž mohou v další hierarchii poztrácet.
potíže při přejímání hodnot
Přestavme si situaci, kdy jeden atribut nabude v hierarchii různých hodnot. V případě jednoduché dědičnosti to není problém – způsob stanovení aktuální hodnoty je jednoznačný a byl popsán výše. Násobná dědičnost ale věci komplikuje.
Problém si můžeme přiblížit, když se zmíníme o tom, k čemu může taková dědičnost vést u jazyků OOP, konkrétně v jazyce jako C++. Tady je třeba zbystřit kdykoliv dojde k uzavření kruhu v hierarchii. Proměnné třídy na nejvyšší úrovni hierarchie v kruhu jsou pak třídou nejnižší zděděny vícekrát, u jednoduchého kruhu konkrétně dvakrát, a to pod stejnými jmény. Více o problému se dozvíte třeba v kurzu C++ [CPPKURP00] v časopise Progres.
U navrhované ontologie můžeme vytvořit mechanismus, který se vyrovná s takovým kruhem, kdy v kritické části (na obrázku zvýrazněné) nedojde k redefinici atributů a jejich hodnot. V takovém případě je v rámci celého kruhu sdílena hodnota z nejvyšší části kruhu a její redefinice v nejnižší části problémy také nezpůsobí. Pokud ale dojde v kritické části ke změně, nelze použít žádný obecný postup pro zjištění hodnoty vespod kruhu – můžeme volit kteroukoliv cestu vedoucí kritickou částí kruhu a cesty jsou rovnocenné.
Při jednoduché dědičnosti není žádný problém:
Ale tady nevíme, zda vybrat pětku nebo sedmičku:
Žádné zázračné řešení asi neobjevíme. Některá z řešení naznačených v předchozí části, mírně upravená můžeme uplatnit i zde – asi nelze zvažovat přetěžování, protože už z definice problému jde o atributy stejných typů. Můžeme ale stanovit pravidla pro automatický jednoznačný výběr cesty, anebo zajistit, aby návrhář taková pravidla nadefinoval, případně vždy cestu explicitně zvolil.
Oproti přejímání atributů zde nehrozí, že bychom se některým z řešení připravili o jistotu, že potomci budou disponovat zděděnými atributy. Nejistota zde ale také je – nevíme, zda potomci budou mít stejné hodnoty zděděných atributů. Obecně se ale s možností redefinice počítá i u hodnot jednoduché hierarchie, ale pokud by náš zvolený model podporoval finální atributy (s hodnotami neměnnými v rámci hierarchie), potíže by zjevně nastaly.
Vícenásobná dědičnost, stejně jako v OOP, i v ontologiích přináší vyšší složitost a potíže. Na druhou stranu výrazně zvyšuje jejich vyjadřovací schopnosti. Proto by měla být v různých variantách podporována jako jedna volba nastavení meta modelu, nikoliv povinně. Podle konkrétní aplikace bude třeba posoudit, zda převáží spíše výhody anebo komplikace...
V předchozí části jsme již zkoumali, jaký vliv na vlastnosti (atributy) entit bude mít hierarchizace, především dědičnost. Ještě jsme se ale příliš nezamýšleli, co jsou atributy vlastně zač..
koncept atributu
Primitivní, ale plnohodnotná komponenta ontologie.
Skládá se z povinných komponent názvu a datového typu a volitelně může být doplněn o vysvětlující popisek. Od jednoho konceptu může být odvozeno libovolně mnoho instancí atributu.
hodnota atributu
Konkrétní hodnota (datová položka) či předpis pro její odvození, přiřazená konkrétní instanci atributu.
instance atributu
Potomek konceptu atributu, tvoří ji především trojice komponent: název, datový typ a hodnota, volitelně popiska. Je přiřazena konkrétní entitě, vazba mezi entitou a atributem není rovnocenná – instance atributu entitě patří. Jedna instance atributu patří právě jedné entitě.
název atributu
Název atributu nelze nikde v hierarchii měnit, protože slouží jako identifikátor. Povoleny jsou pouze znaky anglické abecedy, čísla, pomlčky a podtržítka.
popiska atributu
Nepovinný údaj, umožňuje uživatelsky srozumitelnějším způsobem popsat význam atributu. Může být delší, obsahovat znaky národních abeced a může být také lokalizovaný do více jazyků (viz literál níže).
identifikátor atributu
Atribut je jednoznačně identifikován názvem, v případě přetěžování názvem a datovým typem.
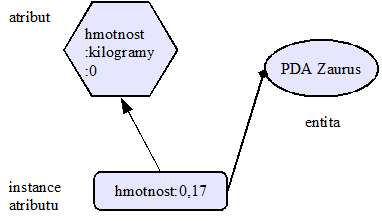
V dalším textu pokud budu mluvit o atributu, budu mít na mysli koncept atributu, případně instanci atributu.
Doména určuje, jaké datové položky jsou přípustné v roli hodnot atributu a také význam těchto hodnot.
I zde je to, co je pod tímto pojmem běžně chápáno – určitý způsob definice množiny přípustných hodnot. Definice může být provedena výčtem všech možných prvků anebo předpisem, který nějak omezuje množinu nadřazenou.
Část hierarchie předpisem definovatelných typů neboli množin povolených hodnot může vypadat třeba takto:
string
numeric
integer
real
...
Způsob definice podtypů nelze stanovit univerzálně – podtypy číselných hodnot budou dány matematickým předpisem (třeba sudá čísla jako dělitelná dvěma), podtypy v řetězcové hierarchii zase regulérními výrazy. Pouze stanovení výčtem je dostatečně univerzální z hlediska typů, na něž je lze aplikovat.
Navrhovaný systém by měl obsahovat kvalitní, univerzálně použitelnou hierarchii typů. Vedle toho by mohly vznikat ontologie oborových typů. Konečně, úplně specifické typy si navrhne sám uživatel / tvůrce ontologie. Smysl je jasný – typ by měl být schopný pojmout veškerá omezení povolených hodnot, aby nebylo třeba vymýšlet další omezující mechanismy.
uživatelský typ
Například takto by mohla vypadat definice specifických typů z oblasti webhostingu; upozorňuji že jde jen o příklad, opravdové definice by měly být deklarovány specifičtěji a měly by to být skutečné regulérní výrazy a ne tyto napodobeniny:
domain a-zA-Z0-9.a-zA-Z
email a-zA-Z0-9@{domain}
ipaddress 0-255.0-255.0-255.0-255
dnsrecord a-zA-Z0-9
'CNAME'|'A' {ipaddress}
Za zmínku stojí druhý a poslední příklad – ukazuje možnosti kompozice typů. Přesné mechanismy kompozice budou specifické pro jednotlivé hierarchie typů, zatím se jimi více zabývat nebudeme.
Podotýkám rovněž, že kompozice datových typů je něco jiného než komplexní datové typy popsané dále.
jednoduchý typ
Hodnota má maximálně jednu datovou položku. Datová položka odpovídá typu.
Příklad: typ domain: www.evidence.cz
komplexní typ
Je datový typ složený z dalších typů. Odpovídající atribut má maximálně tolik datových položek, kolik dílčích typů zahrnuje jeho komplexní datový typ a každá datová položka odpovídá příslušnému dílčímu datovému typu. Každá položka je kvalifikovaná identifikátorem dílčího typu. Dílčí datové typy se mohou lišit. Mohou být jednoduché, násobné, komplexní i komplexní násobné.
Příklad: typ osobnijmeno (jmeno:string, prijmeni:string): jmeno Jan prijmeni Novák
násobný typ
Kterýkoliv typ, jednoduchý i komplexní, může být použit na místě užití jako násobný nebo může sloužit jako základ pro definici explicitně násobného typu – např. typu emails.
Hodnota má minimálně m a maximálně n datových položek. Pokud není stanoveno jinak, číslo m je rovno nule a n nekonečnu a je tedy přípustný jakýkoliv počet položek. Všechny datové položky odpovídají typu atributu.
Příklad: typ email: reditel@evidence.cz, ucetni@evidence.cz
V úvahu připadají též speciálnější možnosti omezení kardinality, obecně dané předpisem. Díky tomu by bylo možno povolit například pouze sudé počty datových položek (třeba seznam účastníků soutěže manželských párů).
U násobného typu navíc může být anebo nemusí být důležité pořadí.
množina synonym
Speciální typ, umožňuje zachytit více položek, ale položky jsou považovány pouze za jiná vyjádření téhož. Vychází z jiného datového typu, v praxi asi nejspíše řetězcového.
mapa
Speciální typ, seznam dvojic klíč a hodnota, obdoba hashovacích tabulek známých například z jazyka Java. Jednotlivé položky lze vkládat pouze v kombinaci s klíčem a přístup k nim bude opět přes klíč.
statická mapa
Je taková mapa, jejíž klíče jsou definovány jednou provždy a od definice nemohou být měněny. Měnit se mohou pouze hodnoty ke klíčům přiřazené.
dynamická mapa
Taková mapa, která může měnit nejen hodnoty, ale i své klíče, případně při definici mohou být klíče opomenuty úplně a naplní se až používáním.
literál
V zásadě pouze speciální případ mapy, typu string a s klíči v podobě kódů jazyků. Umožní vytvářet lokalizované verze textových údajů.
kořenový typ
Veškeré typy budou vycházet z univerzálního kořenového typu. Díky tomu bude snadné implementovat například netypové atributy – jejich typem bude právě tento kořenový typ.
Zatímco datové typy jsou běžné i u konvenčních programovacích jazyků, relevance domény je nový pojem. Relevance přidává k datovému typu konceptuální rozměr – udává význam zachycených hodnot.
V případě běžných jazyků je třeba
význam dodat jiným způsobem, nejspíše
programovým kódem. Takové řešení
funguje, ale nijak nepomáhá vzájemnému
porozumění. Význam datům je přiřazován pokaždé
jinak, a tak někdy sám programátor je zmaten a neví,
zda vlastnost pojmenovat delka nebo
centimetry.
Není snadné takové aplikace propojovat. Vždy musí být doplněna vrstva, která zajistí vzájemné porozumění datům, aby se z nich staly alespoň informace. U číselných údajů musí být doplněno, jaké jednotky jsou používány, u údajů řetězcových třeba kódování, jindy zase použité šifrovací mechanismy. Taková práce není příjemná.
Jsem toho názoru, že ontologie, která má být maximálně věrnou konceptualizací světa, která má podporovat porozumění, a má být sdíleným slovníkem, musí disponovat odpovídajícími prostředky. Relevance domény pomůže porozumět datům.
Typickým využitím
relevance je definice jednotek - centimetrů, kilogramů. Hodnoty
atributu s vyplněnou relevancí tak již nebudou anonymní
bezrozměrná čísla. Univerzálnost a flexibilita
návrhu s využitím relevance bude možná trochu
zřejmější, když si uvědomíme, že třeba i běžný
datový typ datum
lze snadno zachytit jako datový typ číslo
s relevancí dny
(ve významu počet dní řekněme od 1.1.1900).
Relevance je údaj nepovinný – ne vždy má smysl jej udávat.
volitelné (optional)
Výchozí mechanismus, entita i její potomci mohou a nemusí specifikovat hodnoty.
doporučené (suggested)
Do možností ontologie nevnáší žádná pevná pravidla, vyplnění hodnot v celé hierarchii entit je pouze doporučeno. To se projeví například při návrhu varovnými hláškami, pokud není doporučení respektováno. Je věcí konkrétní aplikace, jak bude s nerespektovanými doporučeními zacházet.
požadované (required)
Nejvyšší stupeň vyžádání. Každá entita s atributem v nedefinovaném stavu je považována za nevalidní. Doplnění hodnoty je vynuceno.
V rámci hierarchie dědičnosti lze mechanismy vyžádání zpřísňovat. Potomek s volitelným atributem může změnit stav vyžádání na doporučení nebo požadavek. Žádný z jeho potomků se již ale nebude moci vrátit ke stavu výchozímu.
výchozí hodnoty (default)
Pokud je konkrétní hodnota uvedena již při definici konceptu atributu, dostává roli výchozí hodnoty. Odvozené instance ji zdědí místo hodnoty nedefinované. Mohou ji ale explicitně překrýt.
doporučené hodnoty
Seznam běžných hodnost atributu, může být sestaven a modifikován kdekoliv v hierarchii (u konceptu i instance), slouží pouze jako pomocné vodítko pro uživatele.
nemodifikovatelné (immutable)
Pokud je instance atributu označena jako nemodifikovatelná, nemůže být její hodnota v další hierarchii změněna.
Zatím jsme zvažovali pouze možnost, že instance atributu explicitně specifikuje konkrétní hodnotu anebo je atribut nedefinovaný. Bylo by chybou explicitně evidovat vlastnosti, které přímo vyplývají ze vztahů a vlastností jiných, již evidovaných.
O důsledcích pro konzistenci takového počínání se dočtete dále v části věnované pravidlům.
Princip je jednoduchý – tvůrce ontologie sestaví na dané úrovni hierarchie místo explicitní hodnoty předpis, na základě něhož bude možné hodnotu odvodit.
Opět - inspirativní je v tomto směru oddíl o pravidlech, je pouze třeba mít na mysli, že odvozený atribut nebude definovaný pouze na základě predikátů (výrazů o nichž lze prohlásit zda platí nebo neplatí) ale na základě konkrétních hodnot.
V předpise bude možno čerpat informace z vlastností dané entity a jejich hodnot, z vlastností a hodnot entit okolních, z vazeb a jejich účastníků..
Příklad: obsah čtverce: obsah = strana*strana
Nejjednodušší možné vazby mezi dvěma entitami nedefinují charakter vztahu - jsou netypové a neorientované. Přestože i takovými primitivními vazbami by bylo možno vyjádřit mnohem více informací než bez nich, k blízkému konceptuálnímu popisu světa by měla taková ontologie daleko. Přesto – jednou z možností meta modelu by mělo být povolení netypových vazeb – asi bychom nalezli případy, kdy je naprosto klíčová snadnost použití a typy vazeb by znamenaly zbytečnou komplikaci.
V dalším textu se budeme zabývat vazbami typovými a zejména orientovanými typovými. Nadefinujeme kostru hierarchie typů vazeb, zamyslíme se nad násobností a také třeba nad komplikacemi, které vazbám přináší dědičnost entit.
koncept vazby
Je to typ vazby, myšlenka vyjadřující druh a charakter vztahu, nikoliv nějaký konkrétní vztah mezi konkrétními entitami. Existuje jako samostatný prvek ontologie, jednotlivé instance vazeb jsou od něj odvozeny.
jméno vazby
Identifikátor typu vazby. Při jeho stanovení si návrhář musí vystačit s písmeny anglické abecedy, čísly, podtržítkem a pomlčkou. V hierarchii instancí vazeb je neměnný.
popiska vazby
Pro srozumitelné vyjádření významu vazby, vhodné pro požití v GUI. Mohou být použity znaky národních sad, podpora lokalizace (datový typ literál).
instance vazby
Konkrétní vztah mezi konkrétními entitami. Je odvozen od konceptu (typu) vazby. Nemůže existovat samostatně bez zúčastněných entit.
účastník vazby
Pokud vazbu znázorníme jako hranu grafu, pak účastníky vazby jsou uzly, které vazba spojuje. V ontologii jím může být především libovolná entita, obecněji ale každý prvek, tedy například i atribut nebo jiná vazba.
atribut vazby
Ty informace, které nedokážeme zachytit pomocí prostředků specifických pro vazby (jméno, popiska, účastník, role – ta bude popsána dále) můžeme k vazbě připojit v podobě atributů. Atributy mají stejný význam a možnosti jako u entit.
Z hlediska orientovanosti jsou zjevně nejjednodušší vazby neorientované. Ty mohou sloužit k zachycení symetrických vztahů, kde všichni účastníci vystupují ve stejné roli.
Typickým příkladem neorientované vazby je bratrství – bratři jsou si rovni, každý je bratrem druhému.
jednosměrné
Mají význam pouze v jednom směru. Myslím že v případě ontologií nemá smysl takové vazby uvažovat.
obousměrné
Mají význam v obou směrech, byť podle směru pohledu se jejich charakter ve většině případů bude lišit. Obousměrné vazby jsou tvořeny dvojicí inverzních vztahů, kde žádný z nich není nadřazený. Dvojice je vzájemně nerozlučná – pokud existuje jeden vztah, existuje k němu i vztah inverzní. Pokud toto neplatí, nejde o obousměrný vztah.
Příklad: rodič – potomek, vlastní – je vlastněno, částí – zahrnuje
Neorientované vazby lze implementovat jako orientované, jsou speciální pouze v tom, že jsou tvořeny vazbou, která je inverzní sama sobě.
role
Má význam v případě orientovaných vazeb. Je to postavení účastníka v rámci vztahu.
Například ve vztahu otcovství vystupuje pan Novák v roli otce a malý Franta v roli potomka. Nebo třeba ve vztahu dědičnosti je jeden účastník v roli nadypu a druhý v roli podtypu.
Jde o něco jiného než orientovanost v pravém smyslu. Orientovanost platí na konceptuální úrovni – svázané prvky prostě mají nějaký vztah. Navigabilita definuje nebo omezuje možnost tento vztah sledovat. Podle hodnoty navigability zejména bude nebo nebude uživatelské rozhraní nabízet souvislosti při práci s ontologií.
Podpora takové funkčnosti není v principu nezbytná, ale zpřehlední ontologii z uživatelského hlediska – uživatel nebude obtěžován nezajímavými souvislostmi, byť budou tyto v ontologii zachyceny pro účely odvozování jiných, již zajímavějších skutečností.
Zatím jsme se zamýšleli nad vazbami obecně – nad jejich definicí, parametry apod. Nyní je čas věnovat se trochu specifickým typům vazeb a jejich významu pro ontologii. Rozdělme nejprve možné vazby takto:
Zahrnují souvislosti mezi parametry meta modelu ontologie. Umožňují zachytit nastavení ontologie, podstatně ovlivňují její vyjadřovací schopnosti. Konkrétní podoba bude předmětem budoucích úvah o meta modelu.
Zatím bych zmínil především to, že považuji za užitečné maximum meta modelových vazeb přenést do modelu samotného, a tak zvýšit jeho univerzálnost a flexibilitu. Proto v další části najdete i takové typy vazeb, jako isa pro definici dědičnosti a tvorbu instancí nebo vazbu „je vlastností“ pro připojování atributů, které jsou obvykle vyčleňovány mimo základní hierarchii modelu.
Do této kategorie patří ty typy vztahů, o které jsme se doposud zajímali především – vztahy použitelné ve vlastní univerzální potažmo i v doménově specifické ontologii.
Vsadíme je do širší
hierarchie, která odhalí zajímavé
souvislosti. Když zmiňuji hierarchii, mám na mysli hierarchii
dědičnosti, tedy vztahů isa mezi jednotlivými typy vztahů –
ano můžeme sledovat vztah mezi dvěma dalšími vztahy.
Zasazení do hierarchie umožní pokládat jak
specifické, tak všeobecnější dotazy,
obsahující univerzální, všeobecné
typy vztahů. Například pokud rodič
je nadtyp otec,
pak když je někdo otec,
je to zároveň rodič
atp.
Hierarchii nebudu rozvádět do široka – vlastně jde o samostatnou ontologii vztahů a pro něco takového zde není prostor. Naznačím pouze pár vztahů opravdu univerzálních:
/vztah
/ fyzická
souvislost
/ má
popis
/ má
vlastnost
/ má
(sou)část
/ kontext
/ je (sou)částí (e)
/ je
agregováno (◊)
/ logická
souvislost
/ isa (^)
~je instancí, je podtypem
/je verzí
/ asociace
(→)
/
alternativa
/ je
implementací (o)
Návrh je třeba chápat pouze jako pracovní a měl by být podroben hlubší analýze, především v souvislosti se vztahovými koncepty definovanými v uznávaných top-level ontologiích (SUMO apod.).
Zajímavé bude hledat vztahy
inverznosti. I v takto malé hierarchii je v tomto směru
několik souvislostí, které si zaslouží komentář.
Tak předně, vztahy je (sou)částí
a má (sou)část jsou
vzájemně inverzní. Dále třeba alternativa
je typickým příkladem neorientované vazby.
Vidíme také, že orientovanost se může v rámci
hierarchie vztahů měnit.
Zatím jsme vždy uvažovali vztah dvou prvků (entit, atributu a entity, dvou vazeb). Mohou připadat v úvahu komplikovanější vazby buďto mezi více účastníky kde každý může vystupovat obecně v jiné roli, případně mezi většími počty účastníků, jejichž role jsou totožné?
V reálném světě takové souvislosti jistě existují.
Časté a zřejmé je to například u smluv. Smlouva vlastně vyjadřuje vztah mezi subjekty – vzájemné povinnosti a práva, vztah na kterém se smluvní strany dohodly. Smlouva může mít dva účastníky, ale může jich mít i více.
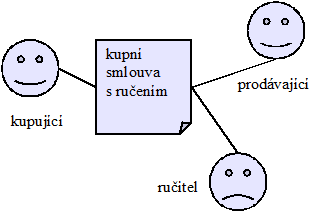
Vzniká otázka, jak takové vztahy zachytit. Jsou obecně dvě možnosti, buďto reálnému světu podřídit meta model ontologie a povolit multilaterální vazby:
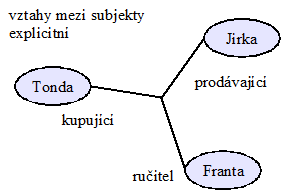
Anebo vztah dekomponovat na více vztahů jednoduchých a přímé vztahy mezi účastníky odvozovat na základě pravidel:
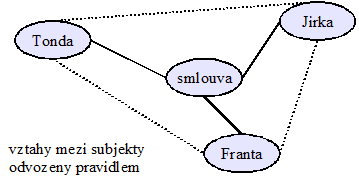
Účastníky jsme nahradili jejich konceptuálním odrazem, smlouva je zachycena v podobě trojité vazby nebo zvláštní entity.
Klíčové je, že obě řešení jsou co do schopnosti zachytit vazbu ekvivalentní, především díky schopnosti vazeb pojímat atributy, jak byla naznačena výše. Máme tedy na výběr. Druhé řešení se zdá od pohledu komplikovanější – je tam spousta vazeb navíc a zdá se že primární vazby ke smlouvě jsou trochu zlomené přes koleno – jde přeci o vztah mezi subjekty a nikoliv o tři nezávislé vztahy ke smlouvě.
Na druhou stranu multilaterální vazby vnášejí do návrhu další technologické komplikace a co víc, u ontologií zdaleka nejsou běžné.
Myslím, že vhodným řešením by bylo tyto vazby povolit, ale pouze volitelně – kdo je využije, nechť mu to systém umožní, kdo ne, zbytečně by mu komplikovaly život.
Násobnost vazby je jiný pojem. Násobná vazba může být i bilaterální, ale minimálně jeden její účastník je násobný, tedy vystupuje v ní v nějakém počtu či množství. Typickou vazbou, která by se mohla často objevit v násobné variantě je agregace či kompozice.
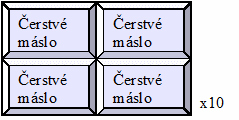
Myslím že nejlepší bude příklad. Dejme tomu, že prodáváme máslo po celých krabicích. V jedné krabici je dejme tomu 40 kusů. Nadefinovali jsme si koncept máslo a koncept krabice.
Jak
zachytíme naznačený vztah? Řekněme že jde o
orientovanou typovou vazbu je
umístěno/obsahuje. Ve směru
máslo-krabice je vše v pořádku, máslo je
v jedné krabici. Obráceně to tak jednoduché
není. Pokud bychom nepodporovali násobné vazby,
bylo by třeba vytvořit 40 instancí másla a všechny
spojit s krabicí nějak takto:
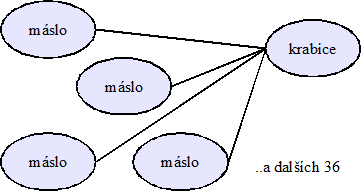
Představa, že by to měl člověk ručně provádět není nijak příjemná, u másla by se to zvládnout ale ještě dalo. Horší by bylo, kdybychom měli dávat do krabiček špendlíky nebo sypat písek do pytlů – jak by bylo možné bez násobnosti vyjádřit množství (hmotnost, délku..) nějaké entity? Proto potřebujeme vhodnější řešení, třeba takovéto:

Myšlenka je zřejmá – vazba je v systému pouze jedna, ale účastník je násobný. Úplně se zde nabízí využít mechanismů násobnosti definovaných u atributů a myslím že to přesně tímto způsobem také zrealizujeme.
Zbývá určit, kde vlastně má být násobnost stanovena. Asi nejflexibilnější bude spolehnout se na mechanismus dědičnosti. Výchozí násobnost u konceptů vazeb bude u všech rolí 1, tedy do vztahu bude moci vstoupit pouze jeden účastník za každou roli. Pokud bude násobnost u konceptu výslovně specifikována (např. 40), bude tato přenesena do všech odvozených vazeb. Obecně bude připadat v úvahu redefinice kdekoliv v hierarchii, pokud nebude redefinice zakázána pomocí prostředků pro zvýšení robustnosti popsaných níže.
Vzniká otázka, jak je možné určit například to, zda je konkrétní vazba přípustná například pro konkrétní kombinaci prvků ontologie v rolích účastníků. Navrhuji mechanismus rozhodovacích řetězců inspirovaný konfigurací firewallů. Rozhodovací řetězce mají jednoduchou strukturu, jsou přehledné a snadno pochopitelné a umožňují poměrně přesně specifikovat, co je povoleno a co nikoliv.
rozhodovací řetězec (decisive chainlink)
Je posloupnost testů a rozhodnutí, která mají být přijata v případě platnosti testu. Na základě rozhodnutí může být provedena určitá akce nebo posouzena přípustnost situace. Pravidla jsou vyhodnocována podle jednoznačně daného pořadí.
test rozhodovacího řetězce (rule)
Skládá se z řady dílčích testů, spojených logickými operátory. V případě testování přípustnosti vazeb pro konkrétní prvky ontologie bude třeba posuzovat jejich parametry – postavení v rámci hierarchie dědičnosti, atributy nebo vazby s jinými prvky (třeba příslušnost ke kategorii).
rozhodnutí (decision)
V úvahu připadá především rozhodnutí o povolení nebo zakázání konkrétní vazby. Přidejme ještě rozhodnutí o změně parametrů vazby – zejména kardinality (násobnosti) na stranách účastníků.
ukončující rozhodnutí (terminal decision)
Ta rozhodnutí, která ukončí další provádění řetězce.
pomocné rozhodnutí (supplementary decision)
Jak asi tušíte, ta rozhodnutí, která neukončí další provádění řetězce, pouze provedou určité akce – třeba změny v nastavení parametrů vazby. Budou vykonána pokud finální ukončující rozhodnutí dopadne kladně.
politka (policy)
Ukončující rozhodnutí, které bude aplikováno pokud žádný test s ukončujícím rozhodnutím neuspěje. Výchozí naložení se situací. Pro každou situaci (kombinaci vazby a účastníků) musí existovat výchozí politika.
Jak bude takový řetězec
vypadat? Půjde o posloupnost testů a rozhodnutí shrnutých
do velkého seznamu. Například pro vazbu je
částí/obsahuje v
prostředí publikačního serveru může část tohoto
řetězce vypadat takto:
vazba prvek= celek= decis.
částí/obs. {have}
schválený=ne {isa} rubrika deny
částí/obs. {isa} článek {isa}
rubrika allow
částí/obs. … … …
částí/obs. default deny
Jak vidíte, pravidlo, které vyřadí neschválené články je vykonáno dříve než to, které povolí zařazení článků obecně. Celé to bude fungovat tak, že bude povoleno zařadit článek do rubriky pouze pokud je schválen redaktorem. Poslední řádek řetězce obsahuje výchozí politku, která zamítne vazby, které nebyly výslovně povoleny.
Možná se zeptáte, jak budou
vypadat rozhodovací řetězce u vztahů dostupných obecně
všem prvkům, například u vazby isa.
Jednoduše:
vazba test decision
isa default allow
Co se testů týče, lze se inspirovat v kapitole věnované pravidlům, konkrétně v části o predikátech. Dále se proto budeme zabývat již jen jednotlivými typy rozhodnutí:
zakázáno (deny)
Ukončující rozhodnutí, vazba je zakázána.
povoleno (allow)
Ukončující rozhodnutí, vazba je povolena.
doporučeno (suggest)
Ukončující rozhodnutí, vazba je povolena (allow) a k tomu navíc doporučena. Konkrétní aplikace může tuto skutečnost reflektovat v grafickém rozhraní – doporučenými vazbami naplní seznam pro snadné ustavení, který zobrazí a zaktualizuje pro každou entitu, pokud je s ontologie otevřena v režimu úprav.
vyžadováno (require)
Vazba je nejen povolena, ale dokonce vyžadována – bez ní bude ontologie invalidní. Konkrétní aplikace na to může upozornit uživatele. Pokud je vazba jednoznačně daná testovým pravidlem, možná ji sama vytvoří, jinak si asi vyžádá doplnění dalších podrobností od uživatele.
změnit kardinalitu (change_cardinalty)
Změní nastavení násobnosti pro jednu nebo více rolí v konkrétní kombinaci účastníků, dané testovým kritériem. Násobnost může být zakázána (změněna na 1), stanovena jednoznačně (40 ks másla do krabice) nebo obecně povolena (uživatel bude asi vyzván k doplnění konkrétního počtu nebo množství).
změnit účastníka (modify_counterpart)
Změní atributy nebo jiné vazby účastníků.
V zásadě je to jednoduché. Pokaždé, kdy se objeví požadavek na změnu ontologie (nová vazba, nová entita..), budou z tabulky pravidel vybrána ta z nich, která by se mohla v dané situaci hodit – v rozhodovacím testu se objevuje prvek nadřazený zařazovanému prvku, jeho předek, případně situace odpovídá na základě jiné shody.
Tento redukovaný řetězec bude třeba projít od začátku do prvního ukončujícího rozhodnutí, případně až do konce, k definici politiky. Všechna pomocná rozhodnutí po cestě k ukončujícímu rozhodnutí budou vykonána v případě, že ukončující rozhodnutí bude kladné.
Trochu zvláštní skupinu pravidel tvoří pravidla pro automatické určení typu vazby. Umožní stanovit jednoznačně typ vazby podle parametrů účastníků tam, kde to lze. Například je zřejmé, že pokud někdo bude chtít definovat vztah mezi technologií a implementací, půjde téměř jistě o vztah implementuje. Takové pravidlo můžete zachytit třeba takto:
vazba prvek= celek= decision
? {isa}
technologie {isa} implementace s_type=implementuje
Je na konkrétní aplikaci, jak si s výsledkem takového pravidla poradí. Pravděpodobně ale asi ochotně nabídne doporučený typ vazby.
doporučit typ (suggest_type)
Pro situaci splňující podmínky testu bude při jejím zřizování navržen konkrétní typ vazby.
doplnit typ (auto_type)
Pro situaci splňující podmínky testu bude automaticky vybrán konkrétní typ vazby. S tímto typem rozhodnutí je třeba zacházet opatrně.
Je-li jeden prvek potomkem druhého, vzniká otázka, zda má zdědit i vazby. Ve většině případů bude odpověď znít ano, potomek možnosti předka spíše rozšíří než že by schopnosti rušil. Na druhou stranu si lze představit i situaci, kdy potomek nedědí vazby předka.
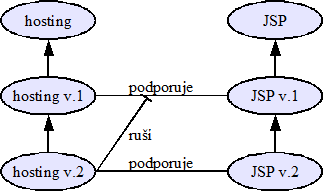
Třeba nová verze programu již nepodporuje zastaralý protokol, který podporovala verze předchozí.
Na druhou stranu, pokud umožníme rušit již ustavené vazby, přijdeme o podstatný díl jistoty – již nebudeme moci prohlásit, že všechny domy mají vstupní dveře – kterýkoliv dům bude moci vazbu na dveře zrušit. Kromě toho, rušení vazeb přinese i další komplikace v podobě složitější práce s ontologií.
Můžeme rozlišovat tři přístupy k nakládání s vazbami v rámci dědičnosti:
zaručené dědictví
Potomek zdědí všechny vazby předka. Nikde v hierarchii se vazby nemohou ztratit.
selektivní dědictví
Potomek zdědí ty vazby, které určí tvůrce ontologie. V úvahu připadají drobné nuance – explicitní dědění a explicitní rušení. Rozdíl je v tom, zda je třeba vyjmenovat ty vazby, které mají být zděděny nebo naopak ty, které zděděny být nemají.
odmítnuté dědictví
V rámci hierarchie se vazby nepřenášejí vůbec.
Napadá mě veselá analogie s dědictvím v občanskoprávním smyslu – dědic jak známo může volit, že dědictví přijímá nebo odmítá, vždy ale jako celek. Tyto možnosti odpovídají první a třetí variantě. Druhá varianta je ze zákona nepřípustná.
Rušení zděděných vazeb je mechanismus, který nelze jednoznačně odsoudit ani schválit, proto jej necháme na volbě tvůrce ontologie – on nejlépe ví, co bude potřebovat a podle toho si nakonfiguruje meta model a tedy vybere, která z těchto třech možností mu vyhovuje nejvíce.
Kromě dědičnosti by bylo možné zkoumat i další použitelné mechanismy rušení anebo naopak vyžádání vazeb. Například automatické zrušení či vyžádání jedné vazby v důsledku vzniku vazby nové. Dejme tomu, že máme dva typy vztahů (A a B) a mezi entitami, které označíme n1 a n2. Obecný mechanismus by se dal shrnout třeba takto:
vyloučení specifické
n1 –A– n2 => ruší n1 –B– n2
vyloučení generální
n1 –A– n2 => ruší cokoliv –B– n2
vyžádání specifické
n1 -A- n2 => musí být/implikuje n1 -B- n2
vyžádání obecné
n1 -A- n2 => musí být/implikuje n1 -B- cokoliv a obráceně
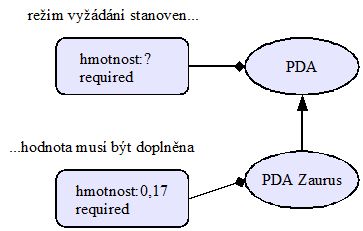
Situace, kdy vazba dvou prvků má za následek vznik nebo zánik vazby úplně jiných prvků už raději rozvádět nebudu..
K čemu jsou pravidla dobrá? Mohou sloužit k odvozování zajímavých důsledků již zachycených vztahů, které pak není třeba explicitně deklarovat. Díky tomu šetří čas při návrhu ontologie a zároveň pomáhají zajistit její konzistenci a jsou tak prostředkem zvýšení robustnosti. Pokud je totiž jedna informace zachycena vícekrát, hrozí, že si informace budou vzájemně protiřečit, což je typický příklad inkonzistence. Proto, pokud z kombinace zachycených informací vyplývají další informace, bylo by chybou explicitně je vetkávat do podoby konkrétních explicitních vazeb nebo atributů. Mnohem lepším řešením je nadefinovat pravidla, která umožní požadované informace odvodit automaticky.
Při procházení ontologie, prohledávání, dotazování bude systém čerpat paralelně jak z explicitních vztahů, tak ze vztahů odvozených na základě pravidel. Z tohoto pohledu půjde o integrovaný celek. Rozdíl bude pouze ve způsobu zadávání a ve vnitřní reprezentaci.
Pravidla lze kromě definice vlastní ontologie také vhodně použít jako prostředek dotazování v rámci interaktivní práce s ní.
Pravidlo je předpis, který se skládá ze dvou hlavních částí:
predikát, výrok
Takové vyjádření, o němž je možno v souvislosti s konkrétní entitou jednoznačně prohlásit, zda platí.
Příklad: works-for :person Franta :company Open-IT
efekt
Důsledek platnosti predikátu. Ta část pravidla, která definuje nový poznatek, vztah apod..
Například systém JADE zná pojem „identifikující referenční vyjádření“, v originále „identifying referential expression“, IRE. [CAIR02] Je to vlastně odkaz na všechny prvky ontologie vyhovující predikátu a používá se především v dotazech a silně se podobá mechanismům intenzivně využívaným v logických programovacích jazycích (Prolog apod.).
Příklad: works-for :person ?x :company Open-IT
Zamyslíme-li se nad predikátem, zjistíme, že je třeba vymezit minimálně dvě věci:
co můžeme zjišťovat, hodnotit, posuzovat a
u čeho, tedy u jakých prvků ontologie.
Odpověď na druhou otázku je poměrně snadná – u entit, vazeb a atributů, další podrobnosti musíme ale rozebrat trochu více..
Na základě čeho mohou být predikáty, potažmo IRE definovány? Za klíčové považuji následující možnosti:
atribut entity
Platí, pokud entita disponuje uvedeným atributem. Jeho hodnota není pro platnost rozhodující.
Příklad: {have} hmotnost
hodnota atributu entity
Platí, pokud entita disponuje uvedeným atributem a jeho hodnota odpovídá podmínce. Podmínkou může být rovnost, ale také >, <, >=, <=. Je zřejmé, že jiné podmínky než rovnost lze použít pouze u atributů takových datových typů, které porovnání umožní a u nichž je mechanismus porovnání definován.
Příklad: {have} hmotnost > 5kg
vazba entity
Platí, pokud entita disponuje uvedenou vazbou a přitom nezáleží na tom, jaké entita je jí ve vazbě partnerem.
Příklad: {have} bratr
partner ve vazbě entity
Platí, pokud entita disponuje uvedenou vazbou a partner splňuje další podmínku.
Příklad: {have} bratr Jan
Stejný mechanismus bude možné použít pro hledání všech členů kategorie:
Příklad: {have} kategorie Recenze
předek entity
Platí, pokud je entita předkem dané entity. Možno specifikovat hloubku hledání – zda je zájem pouze o rodiče nebo i o vzdálenější předky.
Příklad: {ancestor} televize
… nalezne „elektronika“.
potomek entity
Platí, pokud je entita potomkem dané entity. Možno specifikovat hloubku hledání – zda je zájem pouze o děti nebo i o vzdálenější potomky.
Příklad: {isa} elektronika
… nalezne „televize“.
V případě použití pravidel při interaktivní práci s ontologií si vystačíme s predikátem – interpretaci a využití nalezené množiny prvků ontologie provede uživatel. Pokud ale požadujeme pravidla, která nějak doplní ontologické informace o nový pohled nebo rozměr, potřebujeme efekty. Ty nám umožní stanovit, k čemu je vlastně získaná množina dobrá. Již jsme minimálně na jeden typ efektu narazili, když jsme se zabývali dynamickou kategorizací. Stručně ji připomeneme a navrhneme některé další:
dynamická kategorizace
Je to postup, který prvky splňující podmínky predikátu dynamicky zařadí do kategorie.
Příklad: ?x {have} cena => ?x belongs Zboží
dynamické vztahy
Jde o mechanismus odvozování vztahů na základě podmínek v predikátu pravidla.
Příklad: (?x vztah1 ?y) & (?y vztah2 ?z) => ?x vztah3 ?z
Dynamické vztahy umožní třeba definovat tranzitivitu:
Příklad: (?x tranzitivni_vztah ?y) & (?y tranzitivni_vztah ?z) => ?x tranzitivni_vztah ?z
Příklad: „pokud má technologie stejného předka z větve „technologie“, je to alternativa“
JSP1 –> JSP –> webtechnologie <– PHP <– PHP4 => PHP4 alternativa JSP1
pravidla validity
Splnění podmínek predikátu může být také vyžadováno jako podmínka validity ontologie – pokud nová entita či vazba nesplňuje podmínky pravidla validity, nebude povoleno její zařazení, případně modifikace. Tato pravidla zvýší odolnost ontologie proti chybám uživatele.
Příkladem aplikace pravidel validity může být vyžádání/omezení příslušnosti k jedné kategorii na základě příslušnosti k jiné. Pokud je entita produkt, nesmí být zároveň technologie:
Příklad: {isa} produkt => ! {isa} technologie
Za zmínku stojí, že dynamické atributy, přestože jsou jim charakterem blízké, mezi pravidla nepatří, protože místo s hodnotami logickými (pravda/nepravda) mohou pracovat i s jinými, v zásadě libovolnými datovými typy – s konkrétními hodnotami atributů, z nichž dopočítávají hodnoty jiné.
Je zřejmé, že pouze s výše uvedenými podmínkami by nebylo možné definovat i jen trochu komplikovanější predikáty. Pomohou operátory, především
logický součin &
Platí obě podmínky.
Příklad: ({have} bratr ?x) & (?x {have} barva_oci = „červená“)
logický součet |
Platí alespoň jedna alternativa.
Příklad: ({have} bratr) | ({have} dcera)
negace !
Unární operátor negující výsledek jiného testu.
Příklad: ! ({have} hmotnost)
Operátory naleznou uplatnění nejen v části predikátu, ale i u efektu. Trochu problematické by bylo pojetí efektu logického součtu – nebylo by jasné, který efekt zvolit. Proto je logický součet aplikovatelný pouze u predikátu.
Zatím jsme se zabývali především meta modelem ontologie, tedy jejími vyjadřovacími schopnostmi. Snažili jsme se respektovat cíl, totiž navrhnout takový kus softwaru, který by byl univerzálně použitelný pro definici ontologického jádra široké palety aplikací, z nichž o některých jsme se již zmínili.
Cíl zůstává stejný, pouze úkol je teď trochu jiný – zamyslíme se nad ostatními parametry systému, které již tak těsně nesouvisí s meta modelem, ale rovněž značnou měrou ovlivní, zda výsledek bude anebo nebude použitelný.
S provozem systému souvisí kromě zajištění perzistence také to, zda a jak budou evidovány prováděné změny, kdo a co se o změnách bude průběžně dozvídat a také to, co se bude dít se souvisejícími prvky, když bude například smazána nějaká entita. To vše prozkoumáme v tomto oddíle.
Asi to znáte – váš oblíbený textový procesor si pamatuje, jakým úpravám jste dokument podrobili umožní vracet se nazpět v historii změn. Je to velmi praktická funkce a vnímáme ji jako samozřejmost. Podobné schopnosti mají i některé databáze, například objektová databáze ZoDB, která je součástí aplikačního serveru Zope. Veškeré úpravy v ní uložených objektů eviduje a v případě potřeby je dokáže zvrátit.
Náš ontologický systém musí umět totéž. Musí zaznamenávat veškeré změny ontologie, tedy nové entity, nové typy vazeb, nové vazby, nové atributy, změny hodnot atributů a v neposlední řadě výmazy. Možná to dá určitou práci, ale přínos za to stojí.
Evidence půjde využít minimálně takto:
Pokud bude zaznamenáván kromě změny samotné také přesný čas, kdy nastala a nejlépe také kdo ji provedl (jaký uživatel), bude možné generovat sestavy zpráv o vývoji ontologie. Takové sestavy pomohou administrátorům při správě, stanovování práv, omezení, obecně zpřístupňování ontologie na jedné a při jejím zabezpečování na druhé straně.
Pokud se kromě změn budou evidovat i požadavky čtení a prohledávání, možnosti využití se ještě zvětší. Sestavy budou moci sloužit pro analýzy zátěže systému podle času nebo jiných kritérií. V případě ontologií sdílených více subjekty pro stanovování podílů využívání – ty mohou zase sloužit ke spravedlivému rozdělování nákladů. Manažeři budou moci vyhodnocovat aktivitu zaměstnanců pracujících s ontologií...
Asi ještě cennější bude pocit klidu při úpravách ontologie. Žádná změna totiž nebude nevratná. Nestane se, že byste smazali informace o důležité zakázce a o dvě vteřiny později vám už bylo jasné, že v téhle práci nadobro končíte.. Nevím, zda se někdo pokoušel vyčíslit škody způsobené zbrklými uživateli, ale tuším že určitě nebudou zanedbatelné.
Čas každopádně plyne a informační systémy s ním musí umět pracovat. Tuším, že mnoho údajů sledovaných a evidovaných v reálném čase – měřené hodnoty v provozech, čas strávený na projektu, „píchačky“.. by mohlo být realizováno prostředky automatické evidence a archivace změn snadněji a přirozeněji.
Příklad:
Pokud zaměstnanec Franta přijde do práce, řekněme do hlavní
slévárny, svou magnetickou identifikační kartu
prožene čtečkou ve dveřích a informační systém
někde v mozku podniku prostě vytvoří vazbu
Franta–je v–slévárna
a o víc se nestará. Čas příchodu je zaznamenán
automaticky.
Při práci s ontologií budou nastávat události. Událostí je založení nové entity. Nová vazba. Změna hodnoty atributu. Události mohu být ale také neinvazivní – načtení entity, sledování vazby (navigace), prohledávání. Informace o všem tomto dění bude zveřejňována v podobě oborově a místně členěných zpráv.
Jádrem řešení bude..
naslouchač (listener, observer design pattern)
Návrhový vzor, definuje vztah jeden-ku-mnoha mezi objektem-subjektem a libovolným množstvím objektů-naslouchačů tak, že vždy když se změní stav subjektu, všechny naslouchající objekty jsou automaticky informovány a mohou na změnu reagovat. [OBSRLAM98]
V našem případě budeme pro účely definice mechanismu naslouchání změnou stavu objektu rozumět i to, že je například čten, jak bylo naznačeno výše.
Bude třeba věnovat péči vyladění systému zpráv tak, aby byl opravdu použitelný. Naslouchači se budou moci registrovat k jednotlivým typům událostí (základními jsou vznik, čtení, modifikce, likvidace) u jednotlivých entit. Kromě typu události bude muset určit, zda jej zajímá pouze to, co se děje entitě samotné anebo i to, co se děje jejím potomkům (přímým či vzdáleným).
Aby mohla entita garantovat informace o svém potomstvu, musí zde existovat podpůrný systém „probublávání“ zpráv dolů po hierarchii dědičnosti. Při vzniku každého prvku entity jsou registrováni příslušní naslouchači – všichni přímí předkové. Ti budou informováni o všech událostech. Kromě nich se mohou navíc registrovat jiné partie ontologického systému, případně i adaptéry zprostředkovávající spojení s vnějším světem.
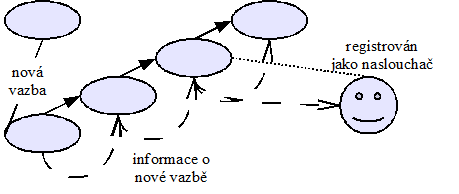
O využití tohoto systému jsme již mluvili, když jsme hledali možnosti využití ontologií v případových studiích. Mluvili jsme například o tom, že tento mechanismus bude základem pro integraci systémů stejného subjektu i systémů externích.
Kromě toho bych se rád zmínil ještě o dalším moc pěkném využití - hlášení budou moci sloužit jako základ velmi snadno implementovatelného systému RSS.
RSS
RSS asi znáte. Používá se pro sledování změn na vybraných webech, případně pro agregaci a syndikaci, tedy další zveřejňování těchto změn.
Pokud napojíme ontologii na systém RSS, kdokoliv se pak bude moci zaregistrovat k odběru pro něj zajímavého kanálu.
Šéf bude sledovat nové zakázky, zákazník nové produkty ve vybraných kategoriích a změny stavů svých objednávek a reklamací...
A co je ze všeho nejhezčí, to vše bude fungovat automaticky, bez jakéhokoliv programování. Postačí definice kanálů a práv k nim – v naprosté většině případů půjde o hrst pravidel v rozsahu maximálně několika řádků...
Zabýváme se provozními otázkami. Už jsme řešili, jak se mají evidovat a hlásit změny, ještě jsme se ale nedotkli toho, co se má dít, když je smazána například entita, která disponuje košatou hierarchií potomků. Co s takovými sirotky provést? Předat do péče prarodičům? Osamostatnit? Nebo je snad dokonce zničit? Při sestavování této části jsem se inspiroval [KAEVOH04].
Problém se týká především odstraněných předků jak již bylo naznačeno.
Již v menší míře budeme požadovat připojení atributů odstraňované entity nějaké jiné entitě – většinou již potřeba nebudou, ale pro úplnost se o nich zmiňuji také.
smazat
Pokud smažete prvek, který má potomka, smazán bude automaticky i tento potomek. Postup může být aplikován v rámci celé subhierarchie.
připojit
Přímí potomci smazaného prvku budou připojeny vazbou isa přímému předkovi smazaného prvku.
osamostatnit
Pokud smažete prvek, který má potomka, potomek bude považován za nejvyšší koncept nově vzniklé hierarchie. Technicky bude připojen ke kořenovému konceptu. Zbytek hierarchie může zůstat beze změny.
dotázat se
Neřešit situaci automaticky, vždy se dotázat uživatele.
smazat
Pokud smažete prvek, který má definované instance atributů, smazány budou i tyto atributy.
připojit
Instance atributů budou připojeny přímému potomkovi, pokud tento nemá již vlastní instance. Pokud je přímých potomků více, instance bude nakopírována pro každého z nich.
dotázat se
Neřešit situaci automaticky, vždy se dotázat uživatele.
smazat
Pokud smažete prvek, který má definované vazby, smazány budou i tyto vazby.
připojit
Vazby budou připojeny přímému potomkovi, pokud je tento doposud dědil a nerušil. Pokud je přímých potomků více, instance vazeb budou nakopírovány pro každého z nich.
dotázat se
Neřešit situaci automaticky, vždy se dotázat uživatele.
Aby likvidace prvku proběhla úspěšně, musí být po jejím dokončení prověřeny podmínky validity.
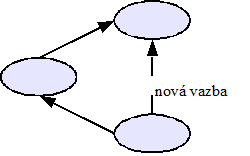 Jak
se má systém zachovat, pokud se uživatel snaží
založit vztah dědičnosti, která již existuje, byť cesta třeba
vede přes jiné prvky například tako:
Jak
se má systém zachovat, pokud se uživatel snaží
založit vztah dědičnosti, která již existuje, byť cesta třeba
vede přes jiné prvky například tako:
Pravděpodobně jde o chybu – taková hierarchie nemá valný smysl. Proto je tady možnost nastavit, co se má v takové situaci stát:
nic specíálního
Nově vytvářená cesta bude přijata jako platná, stará zůstane beze změny.
kratší smazat
Kratší hierarchie vyjadřuje méně informací, proto bude odstraněna.
dotázat se
Neřešit situaci automaticky, vždy se dotázat uživatele.
Na mnoha místech jsme zmiňovali, že to či ono půjde v meta modelu nastavit a tak jej přizpůsobit konkrétním potřebám. Tvrdím, že taková flexibilita je nezbytná, pokud chceme pokrýt širokou paletu aplikací, jak jsme naznačili.
Co obecně může být v meta modelu konfigurováno?
konfigurace meta modelu
Nastavením meta modelu rozumím definici toho, co je v něm
povoleno
zakázáno
vyžadováno
Někdo bude možná oponovat, proč jednoduše neumožnit naráz používat všechny ty vymoženosti – kdo je použije, použije, kdo ne, nebude si jich všímat. Souhlasím, že by to bylo řešení, minimálně v případech kdy nejsou jednotlivá nastavení vzájemně konfliktní. Přineslo by ale problémy:
jak zažít informační opaření
Dejme tomu, že potřebuji řešit nějaký průměrně složitý problém. Pokud k jeho vyřešení dostanu do ruky něco pro mě neznámého, ve svých schopnostech ale velmi mocného a složitého, nějakou dobu se budu snažit pochopit, jak by to mohlo posloužit k vyřešení problému. Dost možná ale po čase usoudím, že úsilí věnované do zvládnutí nástroje bude větší, než přímá pomoc nástroje. Pokud bych nástroji věnoval více pozornosti, časem bych možná zjistil, že mi pomůže řešit i úplně jiné a třeba i komplikovanější problémy. Kvůli prvotní negativní zkušenosti dané složitostí i při jednoduchém použití jsem se o to připravil.
Systém by neměl působit jako kanón, v případě že je třeba sestřelit vrabce. Nastavení a profily v kombinaci s maskovacími dekorátory [PATTGOF95] základních tříd systému by měly společnou silou přispět k rychlému zvládnutí základů. Uživatel poté, co úspěšně sestřelí vrabce, možná začne více bádat a odhalí další, doposud jeho pozornosti skryté funkce a zažije při tom již nikoliv informační opaření, ale příjemné informační dobrodružství.
Za ještě zásadnější argument pro konfigurovatelnost meta modelu považuji toto:
robustnost, logická integrita
Je zřejmé, že ve světě okolo nás jsou složité vztahy. Ontologie je jejich konceptuálním odrazem. Na jedné straně je musí odrážet co nejvěrněji a na druhé straně musí být práce s ní co nejsnazší. K tomu patří i to, že by měla maximálně odolná proti nevhodným zásahům uživatele, lidově řečeno „blbuvzdorná“. Uživatel sice musí myslet, ale není tady pouze od toho, aby po sobě neustále něco kontroloval – co zvládne zkontrolovat počítač, to by taky zkontrolovat měl.
Vhodně nastavený meta model nedokáže odfiltrovat úplně všechny chyby, ale téměř všechny syntaktické a mnohé konceptuální a sémantické.
Autorizovaný uživatel či program bude moci vytvořit v zásadě libovolný prvek ontologie (entitu, vazbu..) nebo sestavu takových prvků. Před vlastním zařazením do ontologie (do kontextu dalších prvků..) musí být ověřena validita. Součástí definice validity je i splnění podmínek nastavení meta modelu. Invalidní změny budou odmítnuty.
Systém bude podle nastavení meta modelu vynucovat takový tvar ontologie, který odpovídá doméně i aplikaci, která s ontologií pracuje. Nedovolí změny, které by s nastavením kolidovaly. Pokud se uživatel pokusí o něco nevhodného, sešle na něj výjimku, která skončí třeba v okně s chybovým hlášením.
Výjimka by měla nést dostatek informací, aby bylo možné říci
co se nepovedlo, nestalo
co je špatně
proč je to špatně
a jak je možno situaci řešit
Téměř jistě zde nezmíním všechno, na mnohé další možnosti pravděpodobně narazíme až časem, při implementaci nebo používání. Myslím že další konfigurovatelné vlastnosti by vyplynuly i z důkladného studia toho, co již bylo napsáno výše. Zaměřím se hlavně na to, jaké oblasti mohou spadat do konfigurace meta modelu.
Především, zda mají fungovat mechanismy sledování času a změn v čase včetně možnosti vracet změny. Také, zda mají být generovány událostí pro registrované naslouchače a vůbec, zda se někdo jako naslouchač může registrovat.
Dědičnost může být podporována v různém stupni:
vůbec
jednoduchá
vícenásobná
A toto nastavení může být jiné pro jednotlivé typy prvků, tedy zejména pro:
entity (koncepty a instance)
koncepty atributů
koncepty vazeb
Kromě toho můžeme vysledovat další parametry související s dědičností, například, zda mohou existovat:
finální prvky
Ty prvky ontologie, od nichž je zakázáno odvozovat jakékoliv potomky.
Nebo zda je povoleno nedědění vazeb a jakým způsobem – více viz oddíl o dědičnosti.
Půjde především o to, zda jsou povoleny atributy
odvozené
finální
uživatelské
A zda mají fungovat mechanismy
vyžádání
podsouvání
Tak jak je vše definováno v kapitole o atributech. Kromě toho mohou být selektivně povoleny složitější datové typy jako mapy nebo literály (pro lokalizaci).
Důležité bude stanovit, zda mohou být v ontologii vazby:
multilaterální
násobné
vazby na externí data
Rozhodovací řetězce mohou být podporovány v různém stupni:
vůbec
pouze ukončující rozhodnutí
ukončující i pomocná rozhodnutí
Dále půjde povolit nebo zakázat mechanismy
vyloučení
vyžádání
Bude jistě pěkné, pokud bude možné nakonfigurovat si meta model přesně podle potřeb. Na druhou stranu, i to bude činnost, která by mohla vést k informačnímu opaření – uživatel by byl zpočátku jistě zmaten tím, co znamená mechanismus vyžádání nebo co jsou rozhodovací řetězce.
Pomocí mu budou profily, zejména ty přiložené do distribučního archivu systému. Prakticky kdokoliv bude moci shrnout své nastavení, nějak jej pojmenovat a vyexportovat, a tak dát k dispozici ostatním.
profil meta modelu
Je souhrn nastavení meta modelu, uložený do přenositelné a sdílitelné podoby.
Kromě prevence informačního opaření, časové úspory a šetření nákladů při zavádění ontologického systému mají profily ještě jeden význam. Použití kompatibilních profilů usnadní integraci.
Pokud se partneři dohodnou, že oba použijí například profil charakterizační sítě, nebudou muset řešit potíže plynoucí z rozdílných stupňů podpory dědičnosti, z rozdílné podpory násobných vazeb apod. A pokud se nedohodnou, informace o tom, jaký profil používá partner jim alespoň pomůže možné problémy identifikovat a využít řešení, která pro kombinace profilů vymyslel třeba už někdo před nimi...
Výběrem profilu se provede základní konfigurace, uživatel bude moci detaily donastavit. V této souvislosti je vhodné definovat co je to
šíře profilu
Profil může shrnovat veškerá možná nastavení – na každou otázku v souvislosti s meta modelem s určitostí odpoví, to je úplný profil. Pokud mnohá nastavení, je to široký profil. Pokud jenom několik málo, je to úzký profil.
síla profilu
Profil k jednotlivým volbám připojuje příznak, zda je o nastavení neměnné nebo pouze výchozí. Jednoznačný profil vynucuje vše, silný profil vynucuje mnoho, slabý profil málo a bezmocný profil nic.
Kromě nastavení je možné k jednotlivým profilům doplnit dekorátory tříd API, které skryjí nepodporované funkce.
základní ontologie
Úplný a bezmocný profil, po kterém by měl sáhnout začínající uživatel. Podporuje pouze to, co je skutečně nezbytné i pro pokusy. Dědičnost jednoduchá, vazby jednoduché, žádné mechanismy vyžádání, podsouvání.. Více méně na všechny otázky z části o konfigurovatelných vlastnostech meta modelu odpoví ne, neumím, snad s výjimkou generování událostí. Každopádně by k němu měly být připojeny odpovídající dekorátory.
meta ontologie
Úzký a jednoznačný, stanovuje pouze podporu vnějších zdrojů, jak byly popisovány v části s případovými studiemi.
samohodnotná ontologie (self-valuable)
Úzký a jednoznačný, vnější zdroje jsou zakázány, opak meta ontologie.
charakterizační síť
Široký a silný profil odvozený v rámci případové studie využití ontologií v elektronické komerci. Podpora externích vazeb, lokalizace, selektivní dědictví...
tématická mapa (topic map)
Profil odpovídající definici jak je uvedena třeba v [GARS02] nebo v [XTMSPEC].
terminologická ontologie
Profil pro budování jednoduchých ontologií, s důrazem na entity a vazby, každopádně bez podpory pravidel.
axiomatická (formální) ontologie
Umožňuje vše, co umí terminologická a přidává pravidla navíc. Pro budování ontologií s důrazem na pravidla a dynamičnost. O terminologických versus axiomatických ontologiích více třeba [ONTOSOW00].
Z příkladů profilů je zřejmé, že jejich šíře je různá – od definice jediného parametru až po kompletní nastavení. Zjevně by bylo praktické umožnit
skládat úzké profily
od univerzálních profilů odvozovat profily speciální
Oba mechanismy mají své opodstatnění a oba je třeba podporovat.
kompozice profilů
Je mechanismus, který umožní definovat profil jako sloučení profilů jiných. Je třeba respektovat omezení jednotlivých profilů a záleží na pořadí kompozice. S jednotlivými parametry bude naloženo takto:
profil
A profil B profil AB
výchozí výchozí A
výchozí neměnný B
neměnný výchozí A
neměnný neměnný nelze
specializace profilů
Je mechanismus dědičnosti, který umožní definovat profil jako speciální případ profilu jiného. Je třeba respektovat omezení předka. S jednotlivými parametry bude naloženo takto:
předek profil
1 výsledné nastavení
výchozí nedefinuje zděděno
výchozí definuje předefinováno
neměnný nedefinuje zděděno
neměnný definuje nelze
Místo násobné dědičnosti, která podporována nebude lze využít kombinaci kompozice a dědičnosti jednoduché.
Nastavení meta modelu a profily řeší trvalé a univerzální parametry a chování, zejména s ohledem na použitelnost ontologie. Smyslem režimů a módů je dále zjednodušit práci s ontologií a především předcházet nežádoucím zásahům ze strany uživatelů.
režim
Zpřístupňuje funkce podle fáze životnosti ontologie a systému vůbec.
mód
Zpřístupňuje ty funkce, které odpovídají oprávnění a záměrům konkrétního uživatele.
návrhu
V tomto režimu bude možno využít veškerých možností API, jak jsou definovány nastavením meta modelu.
provozu
Přestože to nastavení meta modelu umožňuje, v klasickém režimu provozu nebude například možné vytvářet nebo měnit kořenové koncepty, případně provádět jiné podobné úpravy, které spadají spíše do fáze návrhu.
čtení
API povoluje všechno
vytváření
Uživatel může vytvářet nové prvky, zejména entity a vazby, ale nemůže měnit prvky stávající.
úpravy
Uživatel může měnit stávající prvky.
mazání
Uživatel může odstraňovat prvky.
Zejména v souvislosti s potřebou rozdělovat role a spravovat oprávnění jednotlivých uživatelů bude třeba tyto mechanismy rozvést podrobněji, umožnit definovat různé režimy a zejména módy podle oblasti v ontologii.
Nyní je čas zamyslet se nad případnou aplikací využívající navrhovaný systémem jako nad celkem, nasazeným v reálném prostředí, komunikujícím s reálnými uživateli a systémy, pracující s konkrétními daty a nastaveními. Budem především hledat vhodné technologie, které splní jak kvalitativní požadavky definované v úvodu praktické části, tak zároveň funkční a procesní požadavky, které jsme definovali o něco později.
Pokud vás zajímají bližší podrobnosti, případně byste si rádi přečetli něco o tom, jak části zapadají do celkové architektury aplikace a jaké má to všechno důsledky pro snadnost její údržby, rozšiřitelnost a další parametry, můžete se podívat do [ASMZEJ03]. Celá tato část je vlastně aplikací zásad a pravidel Architektury podřízené modelu, včetně důsledků pro volbu technologií.
Za klíčové pro další návrh a implementaci považuji to, aby byly jasně stanoveny hranice vyvíjeného systému. Musí být zřejmé, co je integritní součástí, a co je nadstavba nebo úplně cizí systém. Jsem toho názoru, že je mnohem lepší, když se samotný systém soustředí skutečně na jádro své činnosti, tj. zpracování ontologií a vše ostatní přenechá dalším, jasně odděleným modulům a systémům.
Za základní v tomto smyslu považuji:
Ontologické jádro, které dokáže zachytit ontologii v operační paměti počítače, v rámci běžícího procesu aplikace, která jej využívá.
API rozhraní tohoto jádra, umožňující pracovat s ontologií – klást dotazy, sledovat vazby, provádět modifikace apod.
Systém řízení zpráv, který umožní registrovat naslouchače a tyto bude informovat o veškerém dění v ontologii.
Na obrázku jsou tyto základní komponenty systému zachyceny černou barvou:
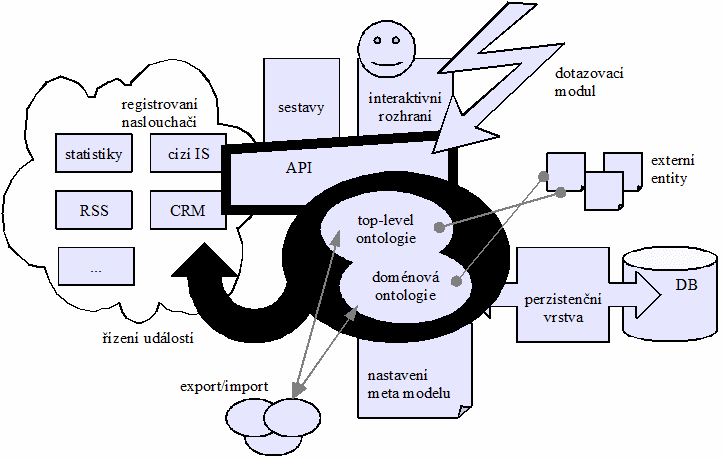
Vše ostatní je rozšiřující, a jako takové není přímou součástí vyvíjeného systému a tedy ani není předmětem vývoje prvního prototypu. Těmito moduly jsme se doposud téměř vůbec nezabývali, přestože pro použitelnost aplikace jsou rovněž podstatné – zkuste vytvořit aplikaci, jejíž data a nastavení nelze ukládat a která nemá uživatelské rozhraní. Myslím že moc nepochodíte. Aby se ale někdo necítil ochuzen, zamyslíme se alespoň nad technologiemi, které by mohly sehrát úlohu v implementaci těchto částí. Přeci jenom i při vývoji jádra je třeba počítat s budoucími nadstavbami – zejména s tím, co budou od jádra vyžadovat a jaké technologie mohou být použity při jejich budování.
Jak bude probíhat komunikace mezi moduly? Vezměme si jeden takový příklad – vyhledávací dotaz.
Pokud uživatel odešle nějaký požadavek, řekněme dotaz, povede to k řetězu akcí. Uživatelské rozhraní zformuluje dotaz v podporovaném dotazovacím jazyce (o něm se stručně zmíníme dále) a odešle ho dotazovacímu modulu. Dotazovací modul jej přeloží do volání API a v této podobě jej předá dále, samotnému jádru. Jádro prověří práva a validitu, zjistí že je vše v pořádku - u dotazu koneckonců nehrozí poškození integrity. Zjistí, že objekty, které reprezentují požadované entity nemá momentálně v paměti, tak o ně požádá perzistenční jádro, ještě předtím ale informuje příslušné naslouchače o zahájení zpracování dotazu. Perzistenční jádro zformuluje příslušný SQL dotaz, který odešle do databáze. Databáze odpoví, perzistnční jádro přeloží relační data do podoby objektů a ty předá ontologickému jádru. Ontologické jádro je zařadí do příslušných kontextů a odkazy na ně předá dotazovacímu modulu a opět informuje naslouchače o vyřízení požadavku hledání. Dotazovací modul sestaví odpověď ve svém jazyce a tu předá uživatelskému rozhraní. Uživatelské rozhraní data převede do podoby HTML stránky a uživatel je naštvaný, že to trvalo celé dvě sekundy.
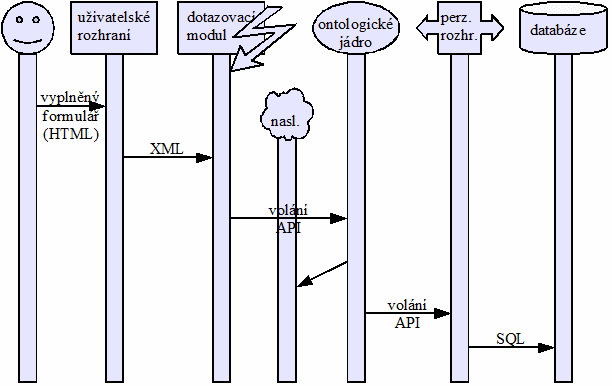
Je zřejmé, že komunikace nebude triviální, a to jsme vůbec nezmínili další systémy a protokoly, které se jí účastní – prostředky síťové komunikace (protokoly TCP/IP, HTTP), databází prováděné čtení z úložiště někde na disku nebo třeba vykreslování komponent HTML stránky prohlížečem.
A opět, vlastní navrhovaný systém je pouze uprostřed.
Za zamyšlení stojí i to, co bude natolik univerzální, že to bude součástí dodávky systému, co bude k dispozici jako doplněk a co vznikne v průběhu instalace a používání.
Nuže, univerzální bude například:
prázdný ontologický systém
základní entity, vztahy, datové typy.. čerpající z vhodné top-level ontologie (isa, part_of...)
prázdná perzistenční vrstva
možná i dotazovací jazyk postavený nad API
Jako dodatek či rozšíření bude k dispozci:
uživatelská rozhraní (HTML, Swing..)
generátory a analyzátory sestav
konektory pro jednotlivá úložiště
doménové a jiné speciální ontologie
Naopak v průběhu života projektu využívajícího náš systém vznikne především:
vlastní ontologie - entity, vztahy...
nastavení a profily
specifické doplňky
Nejprve vymezíme co vlastně máme na mysli, když mluvíme o jádru. Následně se budeme trochu detailněji zabývat tím, jaké základní technologie použijeme pro jeho implementaci.
jádro
Nemá cenu detailně představovat, protože o něm je prakticky celá práce. Je to hrst provázaných objektů reprezentujících ontologii. Patří do něho také API pro manipulaci s ní a API pro konfiguraci. Poslední nedílnou komponentou je systém pro řízení a hlášení událostí.
API
Jak již bylo několikrát opatrně naznačeno, vše potřebné - definice konceptů entit a vazeb, instancí entit a vazeb, modifikace, základní prohledávání podle entit i atributů (Kdo všechno sídlí v ulici Škroupova?), počítání diferencí (rozdílů entit)... lze provádět voláním metod objektů jádra. Inspirací může být API již zmiňované knihovny OJB.
externí entity
Jsou to data a dokumenty uložené jinde než v ontologii – články, obrázky... Již jsme zkoumali, proč je třeba umožnit jejich zasazení do kontextu ontologie. Do jádra sice přímo samy o sobě nepatří, a nepatří do něj ani adaptéry pro různé typy dokumentů a dat. Jádro pouze musí poskytnout obecné rozhraní těmto adaptérům.
Asi jste si již všimli, že když mluvím o jádru, občas zmiňuji nějaké objekty, objektové návrhové vzory a podobné věci. V této části se pokusím obhájit volbu právě takového typu modelu a rovněž dospěji ke konkrétnímu jazyku, který považuji pro realizaci za vhodný.
Nuže, jak by mohl model vypadat? Podle ASM „je potřeba zvolit model, který má dostatečné vyjadřovací schopnosti a tak umožní vytvoření flexibilní aplikace“. Přidejme k tomu ještě robustnost a širokou použitelnost a uvidíme, že mnoho možností nezbude.
Datový model navržený pomocí metodologie zvané strukturální analýza má několik nesporných výhod, které jeho stále ještě přežívající skalní příznivci jistě nezapomenou zdůraznit. Například:
Existuje solidně propracovaná teorie strukturální analýzy.
Databáze jsou podepřeny kvalitní relační teorií. Mocný jazyk SQL je i přes implementační odlišnosti standardní.
Existují silné CASE nástroje podporující tvorbu datového modelu.
Z kterékoliv části programu je možné vidět celý systém najednou, „z ptačí perspektivy“- data jsou všude přístupná, díky tomu nový požadavek zapadající do modelu je „pouze jeden SELECT navíc“.
Ovšem systémy založené na relačním modelu trpí podobnou chybou jakou trpí i strukturální programování a kvůli které možná i někteří příznivci raději poslední „výhodu“ nezmíní: Zásahy v modelu značně ovlivní program a znesnadňují tak údržbu a vývoj celé aplikace.
Co se stane, když máme bohatou košatou databázi a v jedné tabulce změním jednu definici sloupce, anebo dokonce když změním na základě změny požadavků celou vazbu? Co když požadavky na systém natolik narostou, že počty tabulek začínají přerůstat rozumnou mez a jdou do počtu až několika stovek a poté provedu změnu v několika z nich?
Je to jednoduché - procesy začnou „padat“. Systém se stane neudržitelným a jakýkoliv zásah do něj způsobí neustálé problémy pracovníkům z jiných částí týmu, kteří nic netuší a všichni se jenom rozčilují, proč databáze najednou nefunguje. Navíc, a to je horší, nelze mnohdy ani určit, kterých procesů se změny dotknou. Musíte, ať už s podporou programovacího prostředku anebo čistě ručně, projít všechny příkazy SQL databáze, které tabulky, vazby atd. používají, a měnit, měnit, měnit... A protože máte vytvořit systém dost složitý, zákonitě se dostane do kruhu - oprava jedné skupiny tabulek s sebou přináší další opravy jiných tabulek a procesů atd. a systém se stane krajně nestabilním. [ZOOPKR98]
A proč to všechno nastane? Může za to „výhoda veřejnosti“- procesy počítají s datovou strukturou tabulek, kterou jste publikovali všem. Takové řešení by jistě nebylo příliš robustní a snadno spravovatelné, proto musíme pátrat dále..
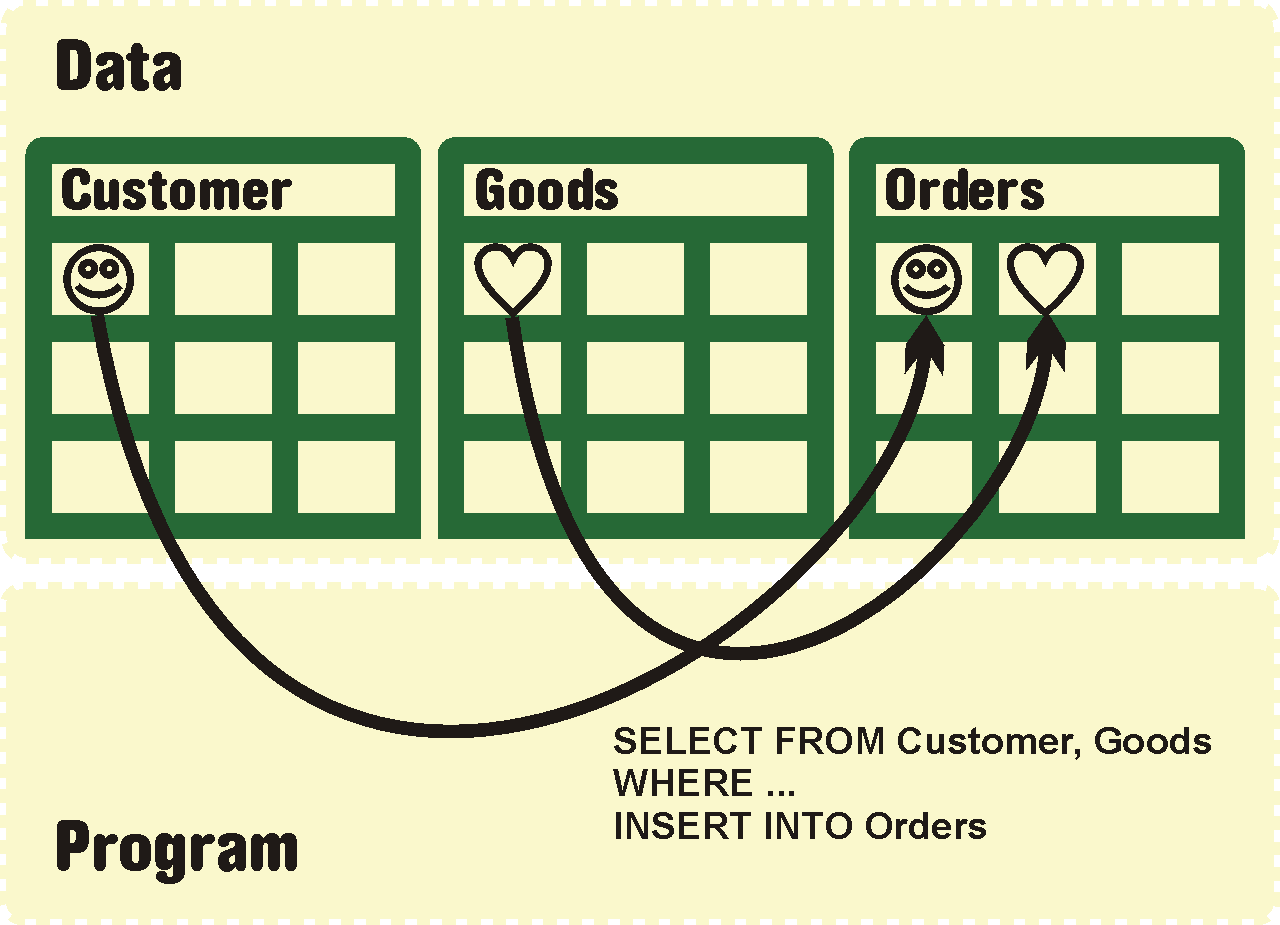
Prosím ale pozor - nezavrhuji zde relační databáze jako takové ani mohutnou relační teorii, pouze nedoporučuji chápat relační model jako jádro aplikace a zároveň nedoporučuji kombinovat SQL s programovým kódem. I přes to jsou RDBMS ověřeným a široce podporovaným standardem pro úložiště, jak prozkoumáme dále.
Na závěr ještě připojím podnětné vzkazy pana Amblera pro návrháře datových modelů. Pokud ale spěcháte, můžete jej přeskočit, o relačním modelu jsem toho, myslím, napsal již až dost. [AMBL]
návrháři logických modelů
Ve skutečnosti již nebude třeba logických datových modelů, pouze tam, kde se ještě nezačalo pracovat v souladu se současným trendem a tedy podle zásad OO, a to jen dočasně. Návrháři logických modelů se proto budou muset naučit navrhovat objektové a/nebo fyzické datové modely. Dobrou zprávou je, že mnohé zkušenosti, které jako návrháři logických modelů získali, budou moci využít - schopnost nadhledu, schopnost modelovat, schopnost dodržovat doporučení. Špatnou zprávou ovšem je, že jejich oblíbený modelovací mechanizmus a datové modely již nestačí a byly překonány objektově orientovaným modelováním. Toto doporučení možná není lehké přijmout, ale čím dříve začnete, tím lépe pro vás.
návrháři fyzických modelů
Ať samozvaní OO guruové říkají co chtějí, fyzické modely jsou stále potřeba. Budete se ale muset naučit navíc mapovat objekty do relačních databází. Dobrou zprávou pro vás je, že po lidech, kteří to dokáží je silná poptávka.
Má své opodstatnění ve speciálních případech, ale spíše jako pomocný model pro zachycení jednotlivých dokumentů, třeba v rámci systémů pro správu dokumentů (document-management). V čistém XML modelu není snadné realizovat dynamičnost – data jsou pouze data a samo o sobě nic neumí. Navíc hrozí podobná nebezpečí jako u relačních modelů, způsobená přílišnou veřejností dat i jejich schémat. Opět - těžko bychom mohli dostát požadavkům robustnosti a rozšiřitelnosti.
Na druhou stranu je zda spousta prostředků pro manipulaci s XML, samotný jazyk dokáže ontologii zachytit docela účelně a pro tyto účely se také hojně využívá. Proto jej rozhodně nemůžeme jednoznačně zatratit a budeme uvažovat o vhodné kombinaci s jiným modelem.
Myslím že platí univerzální poučka „pokud nemáte závažný důvod pro jiný přístup, jakýkoliv informační systém založte na objektovém modelu“. Takovou volbou se zúží volba programovacího jazyka na ty objektově orientované.
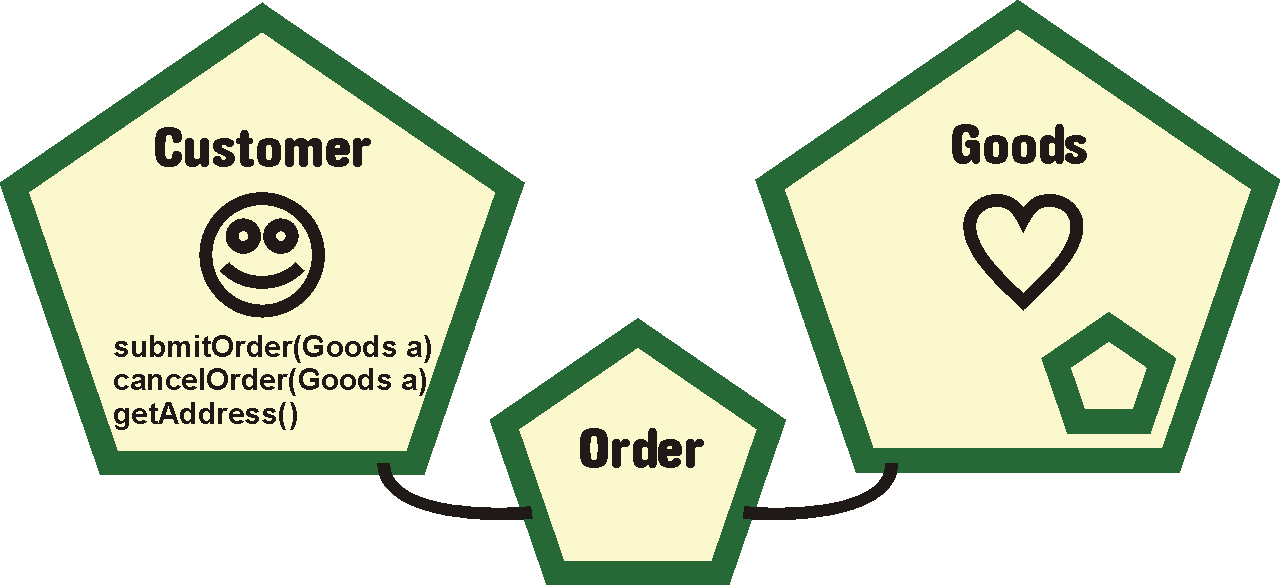
Samotný objektový model sám o sobě samozřejmě žádnou flexibilitu či robustnost nezajistí, pouze nabízí prostředky, kterými je možné „udělat to dobře“ a průběžně vás k relativně dobrým řešením směruje. Nijak tím ale není snížen význam analýzy a návrhu – koneckonců o nich je celá tato práce a stále to ještě nebude stačit.
Pro dokreslení uvádím diagram pokroku v oblasti architektur. Půjčil jsem si jej z [METADIB00]. Ukazuje postupný odklon od relačních modelů a strukturovaného programování.
Jde o různé specifické modely vhodné především pro zachycení znalostí a různé obory umělé inteligence, například dolování informací, rozpoznávání tvarů, práce s lidskou řečí, zpracovávání nejasných a neúplných údajů. Zdá se, že jsou to obory dosti blízké námi navrhovanému systému.
LISP
LISP (LISt Processing, zpracování seznamů) je interpretovaný, plně strukturovaný jazyk, v zásadě se skládá pouze ze seznamů volání funkcí. To mu dodává neobvyklou flexibilitu.
Scheme
Scheme je mnohaúčelový programovací jazyk vyšší úrovně, podporuje operace se strukturovanými daty (řetězci, seznamy, vektory) stejně jako s primitivními typy. Často je spojován se symbolickým programováním, ale jeho bohatá nabídka datových typů a flexibilní struktury pro práci s nimi z něj dělá skutečně univerzální jazyk. Důkazem je, že existují textové editory, kompilátory, operační systémy, grafické knihovny, expertní systémy, výpočetní aplikace, aplikace pro finanční analýzy a snad každý další představitelný typ aplikace. A začít se Scheme není nijak obtížné! [SCHEMED96]
Prolog
Prolog je jazyk pro programování symbolických výpočtů. Jeho název, odvozený ze slov PROgramování v LOGice, naznačuje, že jazyk vychází z principů matematické logiky. Od počátku byl Prolog využíván při zpracování přirozeného jazyka (francouštiny) a pro symbolické výpočty v různých oblastech umělé inteligence. Používá se v databázových a expertních systémech, při počítačové podpoře specializovaných činností, např. při projektování (CAD) nebo výuce (CAI), i v klasických úlohách symbolických výpočtů, jako je návrh a konstrukce překladačů, a to nejen jako prostředek vhodný pro reprezentaci a zpracování znalostí, ale i jako nástroj pro řešení úloh.
CLIPS
CLIPS je nástroj pro tvorbu expertních systémů vyvinutý skupinou Software Technology Branch (STB) v NASA. Nyní je používán mnoha tisíci lidmi na celém světě. V CLIPSu existují 3 způsoby, jak reprezentovat poznatky: pravidly - jsou určena k heuristickým poznatkům založeným na zkušenostech, definování funkcí (deffunctions) a generic function - jsou primárně určeny pro procedurální poznatky, objektově orientované programování - také je určeno primárně pro procedurální poznatky. Program lze sestavit použitím jen pravidel, jen objektů nebo kombinací objektů a pravidel. CLIPS byl také navržen pro plnou integraci s jinými jazyky. [CLIPSMI99]
Sice vše, co dokáží, lze ekvivalentně vyřešit i v čistě objektovém jazyce, ale právě díky specializaci mnoho věcí jde s těmito jazyky snáze, rychleji a přirozeněji. Tam, kde objekty působí těžkopádně a je třeba mnoho kódu možná postačí jedno či dvě krátká pravidla v Prologu. Využití některého takového modelu bych každopádně úplně nezavrhoval, pravděpodobně v kombinaci s modelem objektovým. Bude ale třeba ještě důkladně prověřit dostupnost, platformní nezávislost, licenční podmínky konkrétních nástrojů a další parametry. Oproti objektovým nástrojům a modelům jsou totiž kvůli své specifičnosti tyto nástroje mnohem méně rozšířené a používané.
Čím je dána platforma, na které vaše aplikace poběží? Zejména použitým programovacím jazykem, konkrétně dostupností kompilátoru či interpreteru na různých platformách, ale i dostupností použitých knihoven, závislostí na proprietárních systémech (třeba databázi, uživatelském rozhraní, souborovém systému apod.).
Většina současných programů je vytvářena s pevně stanovenou třídou počítačů a pevně stanoveným operačním systémem nebo třídou operačních systémů, na kterých budou fungovat. Takové řešení je zejména z dlouhodobého hlediska nešťastné - dáváte tím budoucnost aplikace do rukou dodavatele používané platformy. Opět připojím citát od pana Amblera, tentokrát jeho filozofii návrhu (Scott’s General Design Philosophy)
Proprietární řešení vás vždy poškodí: Stále zdůrazňuji: Opravdu přemýšlejte, než přijmete proprietární technologii. Ano, vždy jsou nějaké výkonnostní důvody, a často hraje roli snadnost vývoje, ale nikdy nezapomeňte, že vás musí zajímat rovněž „drobnosti“ jako přenositelnost, spolehlivost, škálovatelnost, rozšiřitelnost a spravovatelnost. Už jsem viděl mnoho společností, které se dostaly do vážných problémů, když použily proprietární vlastnosti, které je svázaly s technologiemi, které se v budoucnu prokázaly jako nedostatečné. [AMBL]
Co když dodavatel operačního systému zkrachuje? Co když vybraná platforma postupně přestane vyhovovat rostoucím nárokům provozovatele aplikace, například z hlediska výkonu či bezpečnosti, zatímco jiná (nová, lepší, rychlejší, bezpečnější...) by vyhovovala? A proč by měl být uživatel vaší aplikace nucen učit se pracovat s jiným operačním systémem, případně za něj platit, pokud jediné, co potřebuje, je fungující aplikace?
Navíc, my nenavrhujeme běžnou obchodní aplikaci, ale univerzální knihovnu, která by měla mít široké použití v mnoha různých prostředích. Určitě by měla fungovat na kterékoliv platformě. Změnou hardwaru či operačního systému kteréhokoliv z počítačů by funkčnost aplikace měla zůstat nedotčena.
Zmiňme nyní krátce některé běžně používané objektově orientované programovací jazyky, abychom následně zlehka prozkoumali, jaký vliv bude mít jejich použití na platformní závislost:
C++
Kompilovaný, hojně využívaný v praxi, vyvinul se ze strukturovaného předchůdce jazyka C zejména přidáním objektové orientovanosti.
Object Pascal
Object Pascal se vyvinul ze strukturovaného předchůdce, jazyka Pascal zejména přidáním objektové orientovanosti. Stejně jako C je kompilovaný. Podporuje jej především firma Borland, která prodává odpovídající vývojová prostředí Delphi a Kylix.
Smalltalk
Smalltalk považuji za velmi zajímavý jazyk. Je možná jako jediný plně objektový, v zásadě interpretovatelný (ale se současnými rozšířeními již nikoliv na 100%). Převzal rovněž dost z myšlenek neméně zajímavého LISPu. Pěkným úvodem do práce s ním je třeba [SMALTHU95].
Java
Java je další silně (byť nikoliv čistě) objektově orientovaný programovací jazyk založený na interpretaci bytekódu. Má silnou podporu ze strany firem, standardizačních skupin, open source skupin i samostatných vývojářů, k dispozici je ohromné množství technologií, nástrojů a pomůcek, které řeší mnoho běžných i méně běžných programátorských úkolů.
Interpreter Javy se jmenuje Java Virtual Machine (JVM) a existuje skutečně pro cokoliv - PC s jakýmkoliv operačním systémem, handheld, mobilní telefon. Zakladatelem Javy a jejím silným podporovatelem je firma Sun Microsystems. Ale kromě standardní implementace JVM firmou Sun je možné použít i jiné - například IBM JVM nebo některou z open source, svými funkcemi se ale s oficiálním JVM nemohou příliš měřit. Na druhou stranu, pokud by Sun z nějakého důvodu přestal Javu podporovat, je dostatečně otevřená na to, aby se jí ujal kdokoliv jiný – ať již společnost nebo komunita.
Python
Python je interpretovaný, interaktivní, objektově orientovaný jazyk. Obsahuje velké množství modulů, které podstatně usnadňují práci. Interpret je k dispozici v mnoha systémech: Unix, Windows, DOS, OS/2, Mac, Amiga... Je sice rovněž opatřený Copyrightem, ale je volně použitelný a šiřitelný i pro komerční využiti. Příslušná licence je svobodnější než u konkurenční Javy
Důležitým pojmem zde je přenositelnost. Tu můžeme sledovat na různých úrovních:
přenositelnost zdrojových kódů
přenositelnost bytekódu
přenositelnost nativního kódu
přenositelnost používaných knihoven
Kromě toho můžeme zkoumat přenositelnost uživatelského rozhraní, dat apod., ale o tom se ještě zmíníme dále.
Pro zodpovězení otázky jaký vyšší programovací jazyk je dostatečně přenositelný je třeba poukázat na principiální rozdíly mezi jazyky z hlediska jejich schopnosti odstínit operační systém, a to ani ne tak v průběhu programování (to je spíše věc procesu vývoje než užití, o které nám jde především), ale zejména při běhu.
Nejdelší historii mají jazyky kompilované. Jejich výhodou je rychlost výsledných programů - relativně časově náročná kompilace ze zdrojového do nativního kódu, kterému rozumí přímo operační systém proběhne pouze jednou, při běhu se pouze spustí - na obrázcích jsem to znázornil překrývajícími se ovály.
Proces vytvoření a spuštění kompilovaného programu vypadá takto:
Výsledný program je nativní, tedy nutně nepřenositelný. Řešením by mohlo být (a bývá) použití specifických kompilátorů - a skutečně, kompilátory například jazyka C++ jsou dostupné prakticky pro všechny běžné platformy. V čem je tedy problém, když pomineme „drobnost“, že náš systém by musel být distribuován v různých vydáních pro jednotlivé platformy?
Zejména v knihovnách, které vaše aplikace použije, protože ty musí být také k dispozici pro každou podporovanou platformu. A dokonce ani mnohé standardní knihovny například již zmíněného jazyka C++ se nechovají všude stejně. Z těchto důvodů je zajištění přenositelnosti buď nepříjemné, nebo hodně nepříjemné, nebo (a bohužel velice často) nemožné.
Proto, kompilovaných jazyků se vyvarujeme.
O něco novější jazyky interpretované přinášejí zásadní změnu - vlastní kompilace probíhá až při spuštění programu a nazývá se interpretace. Do této skupiny patří LISP, Scheme, Prolog, ale i většina jazyků označovaných jako skriptovací jazyky, tedy PHP, Perl, Python, Tcl, JavaScript a v neposlední řadě Python.
Proces vytvoření a spuštění interpretovaného programu vypadá takto:
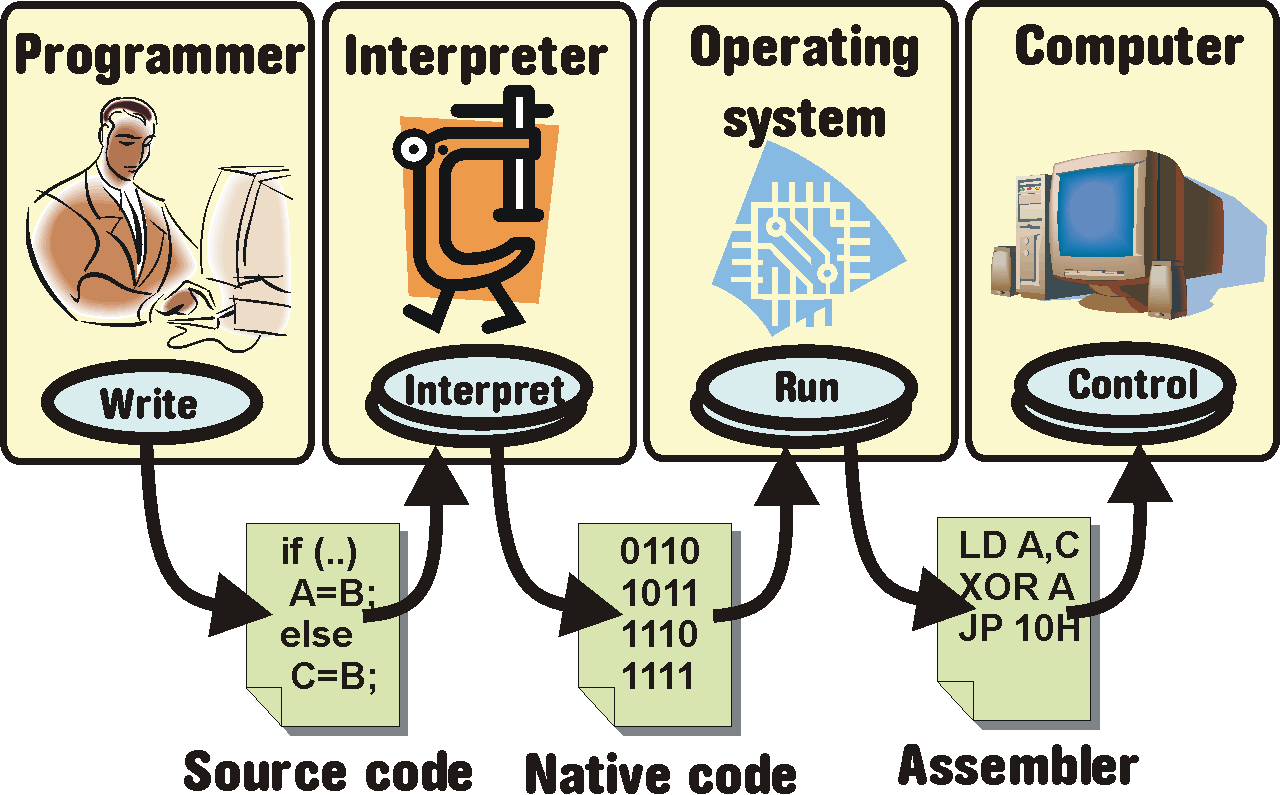
Z hlediska přenositelnosti je to dobré řešení - stačí aby existoval interpret pro každou platformu, která má být podporována. Pokud použijete výhradně přenositelné knihovny (např. v tom samém jazyce), je vše v pořádku. Nebezpečí se skrývá ve schopnosti využívat knihoven neinterpretovaných (a tedy nepřenositelných) jazyků, která je vlastní mnoha interpretovaným jazykům. Použijeme-li nativní knihovnu, přenositelnost se rázem zboří. Před volbou interpretovaného jazyka budeme muset prověřit, zda jsou k dispozici přenositelné knihovny ke všemu, co budeme využívat.
Nevýhody jsou dvě:
Dáme veřejně k dispozici svůj zdrojový kód, i kdybychom náhodou nechtěli a především by to nemuseli chtít případní uživatelé naší knihovny.
A dále, program je pomalý - časově náročná kompilace se provádí při každém spuštění. Tento problém již dnes ale tolik nepálí – kvalita interperterů je mnohem vyšší než dříve a hardware také pokročil..
Jazyky interpretované s bytekompilací jsou další generací jazyků interpretovaných. Rozdělují proces kompilace do dvou fází. Bytekompilátor převede zdrojový kód do tzv. bytekódu, což je operace časově srovnatelná s kompilací do nativní podoby, ale bytekód je platformně nezávislý . Interpretr bytekódu je již nutně platformně závislý, a proto musí existovat pro každou podporovanou platformu.
Proces vytvoření a spuštění bytekompilovaného programu je takovýto:
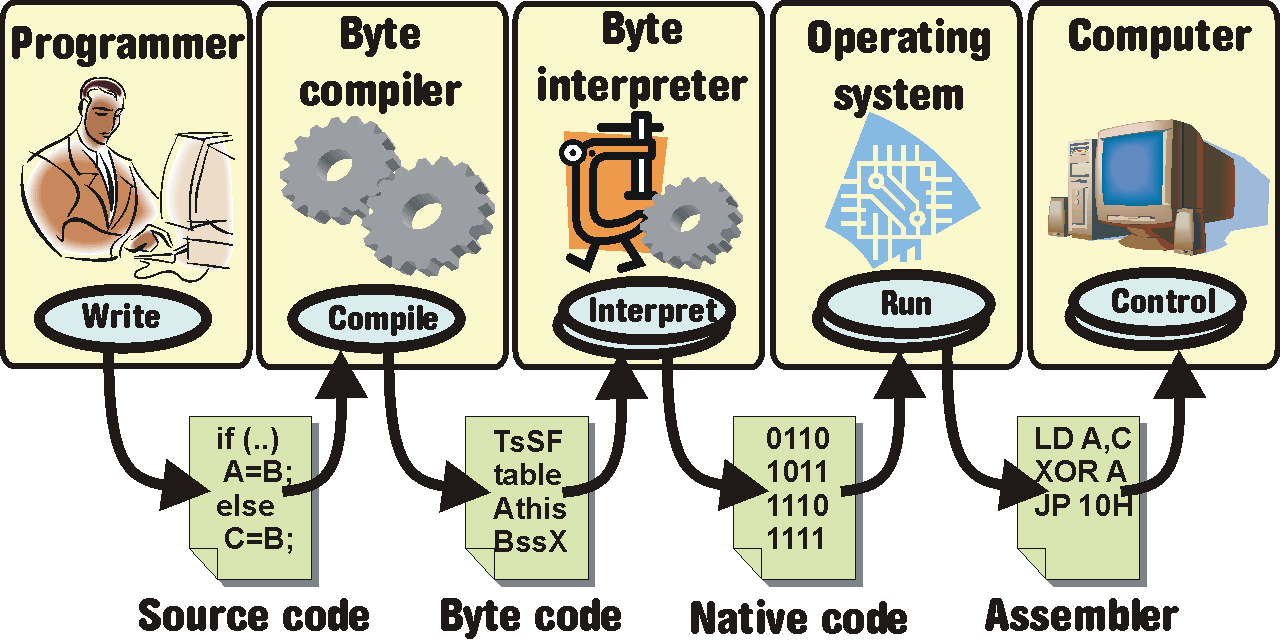
Z hlediska přenositelnosti je to řešení stejně dobré, jako čistá interpretace. Navíc přináší výhodu v podobě vyšší rychlosti běžících aplikací a odpadá nutnost zveřejnit zdrojový kód. Ovšem i zde musíme dbát na to, že využijeme pouze přenositelné knihovny.
Věřím ale, že cesta vede nejspíše právě tudy.
Otázkou je, který jazyk konkrétně je nejvhodnější? Odpověď nemůže být naprosto jednoznačná - protože záleží na konkrétních parametrech navrhované aplikace. Hledaný jazyk musí být široce rozšířený, široce podporovaný, dostupné nástroje musí být schopny zajistit vše potřebné bez pevné vazby na cokoliv nativního.
Co třeba Smalltalk? Je dobře navržený, výkonný, čistě objektově orientovaný, interpretovaný s bytekompilací, interprety existují pro mnoho platforem... Ovšem trpí právě nedostatkem kvalitních, dostupných knihoven a tento hendikep řeší možností využívat nativní knihovny C a dalších jazyků.
Zbývají dva kandidáti - Java a Python. Možná mají ve srovnání se Smalltalkem nějaké drobné chyby v základní specifikaci, ale u Javy jistě a u Pythonu téměř jistě nehrozí, že bychom museli použít cokoliv nativního proto, že nenajdeme vhodný nativní ekvivalent. Interpretery rovněž existují a jsou svobodně k dispozici.
K řešení postaveném na Pythonu se přikláním, zejména když si vzpomenu na studii využití v prostředí správy serveru. Java například na Linuxech k dispozici je, ale příliš velké oblibě se netěší kvůli svému korporátnímu pozadí, stále relativně restriktivní licenci a monolitické architektuře JVM. Mnozí správci systémů Javu považují pořád za příliš podezřelou, aby jí svěřili své bohatství.
Java je zase jasnou volbou pro e-business – šéfové velkých firem naopak neuznávají nic, za čím nestojí společnost dostatečného jména, tedy ani Python, byť by šlo o technicky nejvhodnější řešení. Java má přeci jenom o něco vyšší výkon a rovněž je pro ni k dispozici i více knihoven a nástrojů.
Pro implementaci prototypu zvolme Javu a uvidíme...
Umožnit datům přežít konec běhu programu, to patří mezi základní požadavky. Pokud bude chybět možnost ontologii, ale rovněž nastavení systému uchovat, těžko se najde pro systém nějaké reálné využití. Zdálo by se možná, že jde o samozřejmost nebo trivialitu, ale ukládání komplikovaných dat, když jsou tady požadavky výkonové a také požadavky stability a robustnosti, není nic snadného.
Bylo by ale chybou snažit se perzistenci řešit úplně po svém, když existuje nepřeberné množství různých databází, všech možných typů a parametrů. Chybou by rovněž bylo vybrat jedno z té záplavy možných úložišť a systém na něm udělat závislým. To by byl prohřešek proti snaze o maximálně univerzální použití – je zřejmé, že jiné úložiště bude používat domácí uživatel pro organizaci rodinných fotografií a úplně jiné úložiště zvolí nadnárodní korporace pro ukládání informací o svých produktech (a ještě jiné pro evidenci přijatých a vydaných úplatků – má dáti-dal :-).
Musíme najít nebo vytvořit univerzální perzistenční vrstvu, konkrétní úložiště bude využíváno s pomocí pro něj specifických adaptérů do této vrstvy.
Existuje nepřeberně možností, jak ukládat data z aplikace. Data můžeme ukládat jako soubory uvnitř souborového systému, můžeme vytvořit nějaký proprietární atypický ukládací systém, můžeme využít relačních databází, objektových databází, XML databází, LDAP struktur nebo třeba něčeho úplně jiného.
V dalším textu se zaměřím především na možnosti pro jazyk Java.
Serializace je nástroj standardní knihovny Javy, tedy je ihned k dispozici. Princip je stručně řečeno takový, že objekt je převeden do binárního datového proudu a nástroje pro zpracování datových proudů ho pak můžou uložit například do souboru. Ze souboru je možné objekt „zrekonstruovat“ do původní podoby.
Pokud nechceme promíchat kód specifický pro tento typ ukládání s vlastní aplikační logikou, musíme vytvořit nějakou vrstvu, která bude ukládání řídit... což znamená vytvořit v zásadě celý databázový systém. Ano, serializace je použitelná pro jednoduché nebo specifické úlohy.
O řešení některých nedostatků standardní serializace se pokouší různé nástroje, které uloží objekt nikoliv v binární podobě, ale do XML a z XML ho umí zpětně zrekonstruovat, tedy provádějí XML mapování. Produktů v této kategorii je více.
JOX
JOX je skupina Java knihoven, které usnadňují přenos dat mezi XML dokumentem a objektem odpovídajícím JavaBeans specifikaci. Můžete chápat JOX jako speciální formu serializace, kde použitým formátem je XML. JOX je tak snadno použitelný, jako samotná serializace. Výstupní XML soubor má ovšem poměrně plochý formát a nejde příliš (téměř vůbec) přizpůsobovat. Pro naše účely není vhodný. Více viz [JOX].
KBML - The Koala Bean Markup Language
KBML přístup zvládne mnohem více typů objektů než JOX, ale musíte se uvázat k použití jejich speciálního XML formátu. Koala XML serializace je nadstavbou standardní serializace. Proces je rozdělen do dvou fází: Všechny objekty jsou serializovány do java.io.ObjectOutputStream a následně převedeny do KOML dokumentu. Deserializace probíhá obráceně. Pro naše účely se jeví použitelnější, ale téměř jistě bychom narazili na problémy s výkonem u větších ontologií. Více viz [KBML].
JAXB
Sun si je rovněž vědom potřeby XML reprezentace objektů. Vybrali si širší řešení, nazvané „data binding“ (JAXB). Toto řešení je mnohem více řízeno daty, protože využívá XML schémata přímo pro generování tříd schopných XML data zpracovávat. Serializace má být nabízena spíše jako vedlejší efekt. Hlavní nevýhoda tohoto využití spočívá v nutnosti opatřit objekty specifickými serializačními a deserializčními metodami (nazvané marshal/unmarshal). Kromě proprietárnosti a přesahů do designu tříd bychom asi opět narazili na problémy s výkonem. [JAXB]
Každý ze zmiňovaných nástrojů má své výhody i nevýhody. Ovšem všechny nástroje řeší opět jenom mechanizmus převodu objektu do nějaké uložitelné formy a nikoliv pokročilejší funkce, které bychom potřebovali.
Objektově orientované systémy (OODBMS) umožňují ukládat objektová data ve tvaru, který je jim přirozený [SICO99] a jsou tak řešením, které se tak říkajíc na první pohled nabízí, má-li aplikace propracovaný objektový návrh.
ODMG
Již několik let starý standard vytvořený sdružením Object Database Management Group (ODMG). S ODMG je možné vytvářet transakce, přistupovat do databáze více vlákny, znovupoužívat připojení (connection pooling). Definuje komponenty:
objektový model
specifikační jazyky
dotazovací jazyk
vazby do programovacích jazyků
Avšak volně nabízené a otevřené OODBMS jsou stále (již několik let) v experimentální fázi vývoje a tak či onak nestabilní, zatímco komerční systémy ohromí svými cenami. Co je ale nejhorší, kromě ODMG existuje hned několik dalších dotazovacích jazyků a žádný není široce podporovaný.
Na rozdíl od objektově orientovaných, kde jsou data silně strukturovaná a logicky propojená, jediné co relační databáze (RDBMS) nabízejí, jsou tabulky propojené relacemi. Relační databázové technologie jsou vyspělé - jedny z nejstarších, přitom používané a stále nejpopulárnější ze všech. Přispívá k tomu jejich jednoduchost, efektivita, obecně nižší nákladnost. Existuje i mnoho poměrně pokročilých RDBMS úplně zdarma, například PostgreSQL.
Objektový přístup k tvorbě aplikací pracuje s objekty - strukturami, kombinujícími data a chování, zatímco relační přístup je zaměřený čistě na ukládání dat.
impedanční nesoulad (impedance mismatch)
Takzvaný impedanční nesoulad vyplyne na povrch, když porovnáme upřednostňované řešení přístupu. U objektového řešení je zvykem objekty procházet tak, jak jsou vystavěny příslušné závislosti, zatímco relační přístup duplikuje data při spojování řádků tabulek.
Tento základní rozdíl znesnadňuje kombinaci obou přístupů, ale, přiznejme si, kdy jste naposled použili dvě různé, primárně nesouvisející věci, aniž by to vyžadovalo pár triků? Jedním z tajemství úspěchu při objektově relačním mapování je porozumět oběma přístupům, jejich odlišnostem a na základě tohoto poznání je přimět ke spolupráci. Tyto postupy jsou již dnes docela dobře propracované a dobrým úvodem je [AMBL].
V současné době jsou také k dispozici použitelné nástroje, které značně usnadní mapování. Jsou to řešení proprietární, liší se funkcemi, podporovanými formáty popisu mapování, programátorským rozhraním, podporovanými RDBMS a mnoha dalšími vlastnostmi. Na Internetu je k dispozici celá řada srovnání.
Pan Ambler vzkazuje: „Již před lety samozvaní objektoví guruové nabádali, abychom nechodili cestou nesouladu. Ano, objektový přístup je jiný než relační, ale v 99% případů, kdy vývojové prostředí je objektově orientované, úložištěm bude relační databáze. Prosím, smiřte se s tím.“ [AMBL]
Ano, zdá se, že nejvhodnějším úložištěm ontologie bude relační databáze.
Mnoho výrobců databází, např. Oracle používá technologie, které zachovávají přednosti relačních databází a zároveň umožňují podle standardu SQL 99 specifikovat uživatelské datové typy (UDT), které logicky odpovídají objektům. Datový model je přímo v databázovém systému objektový a na jeho základě se tvoří jednotlivé tabulky. Toto řešení se principiálně neliší od O2R mapování popsaného výše, rozdíl je pouze v přímé podpoře ze strany databáze.
OLAP (On-Line Analytical Processing)
Je technologie, která umožňuje pohlížet na data tradiční relační databáze jako na mnoharozměrnou strukturu. Příklad inspirovaný [SICO99]:
Tradiční tabulka vypadá takto:

Příklad pohledu podél jiného rozměru:
Tento model včetně implementace a nezbytných nástrojů umožňuje rychlé, přirozené zpracovávání dat podél všech rozměrů. Má význam zejména pro velké databáze, kde jsou potřeba postupy označované jako data mining. Součástí mnoharozměrného pohledu mohou být hierarchie a mnoharozměrná aritmetika. OLAP analýza může být implementována nad tradičními (zejména relačními) databázemi, anebo nad speciálním optimalizovaným úložištěm - mnoharozměrnou databází (MDBMS). Jejich cena odpovídá typickému nasazení.
Možná by byly schopny zachytit ontologii, ale spíše se mi zdá, že jsou určeny pro jiné typy nasazení. Každopádně nemůžeme systém postavit na nich už pro jejich vysokou cenu.
Stromová datová forma je velmi vhodná pro některá silně strukturovaná data, např. pro dokumenty, hierarchie objektů (třeba uživatelů), reprezentaci plánů apod. Příslušné technologie jsou například:
LDAP
LDAP je specifická databáze určená pro ukládání stromových datových struktur. Používá se především pro administraci v prostředí počítačových sítí, ale může slouží pro ukládání v podstatě čehokoliv, co má smysl ukládat na síť a co potřebujeme častěji číst než zapisovat. Od databáze uživatelů až po televizní program...
Rozlišuje služby autorizované a neautorizované, globální a lokální, jak můžou být aktualizované záznamy a kým, co položky mohou obsahovat a mnoho dalších věcí. Je velice rychlá při čtení a vyhledávání, a to jsou operace prováděné mnohem častěji než zápis. Technologie je to zavedená a stabilní, existují otevřené implementace (OpenLDAP). [HEPP03]
Nativní XML databáze
Jsou databáze specializované na ukládání XML dokumentů, místo tabulek pracují s kolekcemi XML dokumentů. Dokumenty v kolekci obvykle mohou, ale nemusí odpovídat určitému schématu. Poskytují také prostředky pro manipulaci (výběr, změna, smazání, přidání) s libovolnou částí XML dokumentů.
Někdo možná namítne, že to vše lze obvykle provádět i bez specializované databáze s využitím rozhraní DOM. XML databáze k tomu přidávají možnost dokumenty indexovat a sofistikovaně prohledávat. K databázi lze obvykle přistupovat příkazovým řádkem, různými API nebo přes síť (nejčastěji protokol HTTP). Příklady: Tamino, Xindice, eXist, Xhive. [XMLKOSE00]
Kromě relačních databází v kombinaci s prostředky O2R mapování považuji právě tato úložiště za vhodná. LDAP zejména ve specifických nasazeních – např. pro systém pro správu serveru apod. a XML databázi i pro použití běžné.
Sami vidíte různorodost existujících řešení perzistence aplikací, z nichž každé má své výhody a nevýhody a to jsem se o mnoha možnostech vůbec nezmínil. Potřeba zastřešit takto různorodé zdroje dat nějakým jednotným rozhraním vyústila v definování konkrétních standardů.
Kromě příkladů specifických pro jazyk Java (níže) stojí za zmínku ještě jednou ODMG. Tento standard měl původně sloužit jako jednotné rozhraní objektových databází, ale teoreticky (díky svému poměrně univerzálnímu návrhu) by mohl splnit stejnou funkci. Je potřeba mít ovšem na mysli, že použitelný bude ten standard, jemuž se dostane podpory ze strany dodavatelů řešení úložišť.
JDO (Java Data Objects)
Standard JDO byl definován jako standardní rozhraní mezi objekty Java aplikací a úložišti persistentních dat, nejčastěji relačními databázemi. Snahou bylo oddělit vlastní logiku aplikací od konkrétního způsobu uložení dat, tedy od konkrétní databáze, ať relační či objektové. Použití JDO rozhraní usnadní programátorům práci tím, že se nemusí přímo zabývat konkrétním datovým modelem na úrovni databáze a mohou se plně soustředit na logiku aplikace. V současné době je nejsilnější podpora relačních databází. Od roku 2002, kdy byla zveřejněna specifikace a referenční implementace je standard již poměrně vyspělý a jeho podpora poměrně dobrá. Nevýhodou JDO je to, že spoléhá na modifikaci bytekódu tříd.
EJB CMP Enterprise JavaBeans Container Managed Persistence
EJB je komponentní architektura pro distribuované aplikace, která může být využita spolu s JDO. Komponenty EJB nabízejí svůj mechanismus pro ukládání dat, a to CMP. Na rozdíl od JDO je použití CMP omezeno pouze na komponenty EJB, ale zase umožňuje distribuované transakce, přístup k distribuovaným objektům a rovněž nabízí bezpečnostní služby. JDO zase operuje s bohatším, ale zase s lokálním objektovým modelem. Např. objekty CMP musí být z balíků java.util.Set nebo java.util.Collection. Ukazuje se tedy, že JDO a EJB se vhodně doplnují zejména při distribuovaném zpracování. Když komponenty EJB zapouzdří třídy JDO, tak bude možné přistupovat k instancím tříd JDO vzdáleně a přímo.
Použití CMP u navrhovaného systému vidím jako problematické – má příliš velké požadavky na objektový model systému, navíc nelze očekávat že každý bude instalovat J2EE aplikační server. JDO se jeví jako použitelnější. Uvidíme v co vyústí snahy spojit výhody JDO a CMP v návrhu JDO 2.0.
Jaký typ úložiště zvolit? Otázka to mnohdy není jednoduchá a její zodpovězení běžně (často negativně) ovlivní celou aplikaci včetně jejího objektového návrhu. Co je horší, v mnoha případech není vůbec jednoznačné, které řešení je to pravé, dokonce ani který druh úložiště. Navíc, pokud je něco „tím pravým“ nyní, nemusí tomu tak být natrvalo.
Opět, hledíme-li do budoucnosti, derou se nám do mysli otázky podobné, jaké jsme si již kladli v části o platformní nezávislosti: Co se stane, když výrobce použité databáze zbankrotuje? Co když databázový systém přestane vyhovovat, ale jiný by by byl lepší..
V našem konkrétním případě je problém ještě komplikovanější, protože pracujeme v heterogenním prostředí, které musí integrovat data z různých zdrojů – ontologie mají sloužit jako prostředek spojení a dorozumění. Stojíme před otázkami jak provázat systémy, aniž by to bylo za cenu kompromisů v čistotě návrhu? Jak si „nezavřít vrátka“ k jiným, modernějším možnostem ukládání, jakmile bude možné starý systém odstavit? Komplikovanost takových přechodů je zřejmá z návrhových vzorů a dalších informací z [MERGKELL].
Většina vyvíjených aplikací je silně svázána s konkrétním úložištěm. A to je chyba. Architektura podřízená modelu [ASMZEJ03] naopak doporučuje:
Výběr úložiště nesmí ovlivnit objektový návrh
Aplikace nesmí být pevně svázána s žádným konkrétním úložištěm a dokonce s žádnou konkrétní třídou úložišť.
Změna úložiště musí být proveditelná pouhou rekonfigurací či doplněním části podpůrného nástroje, který zajistí perzistenci objektovému modelu aniž by se to dotklo kterékoliv jiné části aplikace (zejména objektového modelu nebo uživatelského rozhraní)
Aplikace by měla být schopna integrovat data z různých úložišť a dokonce z různých tříd úložišť
Zajištění perzistence by mělo být z hlediska programátorů a vývojářů co nejsnadnější
První vývojovou fází většiny nástrojů je čisté objektově-relační mapování - nástroje zastřešují různé (ideálně všechny dostupné) RDBMS tak, aby se případná záměna nedotkla vlastní aplikace. Takových řešení je poměrně mnoho (možná desítky).
Druhá generace se snaží o skutečně univerzální přístup, jak byl popsán výše, tedy kromě RDBMS umožňují jednotně pracovat též s OODBMS, LDAP, souborovým systémem a většinou po doprogramování příslušného modulu obecně se vším. I těchto nástrojů existuje poměrně dost, populární je například Hibernate. Jeden systém ovšem vybočuje svým vysoce kvalitním návrhem a snahou jít cestou standardů všude, kde je to možné.
Jakarta OJB
Jakarta OJB (původně ObjectRelationalBridge, po kompletním přepracování a zuniverzálnění dále už jen OJB) je knihovna pro jazyk Java, která zpřístupňuje nejen relační databáze, ale teoreticky všechny běžné typy úložiště. Aplikace může přistupovat k úložišti přímo jednoduchým, ale proprietárním rozhraním nazvaným PersistenceBroker. OJB ale přidává další vrstvu abstrakce i směrem „dovnitř“, tedy k aplikaci a té tak umožňuje pracovat dle nejznámějších standardů - ODMG či JDO.
Tato architektura je dobře vidět z obrázku, který jsem si půjčil z [OJB]. Můžete si všimnout toho, že v návrhu se počítá se všemi typy úložišť, které pro naše použití připadají v úvahu – RDBMS, OODBMS, XMLDBMS a LDAP.
OJB dokáže pracovat jak ve vícevrstevné architektuře uvnitř EJB aplikačního serveru, tak u nevrstvené aplikace. Je, ostatně jako všechny jiné projekty Apache Jakarta, dobře dokumentována. Její novější verze se i docela snadno nastavují i používají. A je zadarmo, dokonce open-source. Sám jsem nepatrně jsem i přispěl k jejímu vývoji a její funkčnost odzkoušel na jednoduchých aplikacích. OJB je ale nasazena i v silně zatížených podmínkách.
Tato část je možná trochu rozsáhlejší, proto hned v úvodu zmíním, o co půjde. Uživatelské rozhraní budu chápat pouze jako slupku okolo vlastního API. Budu se zamýšlet nad možnostmi kombinovat uživatelské rozhraní ručně vyprojektované s částmi automatizovaně generovanými z ontologického modelu. Důraz budu klást na rozhraní typické pro web, ale zároveň budu doporučovat univerzální zobrazovací řešení se snadnou záměnou konkrétních uživatelských rozhraní. Opět si ukážeme, co znamená zásada „volná vazba – snadná změna“. Zmíníme se i o rozhraní pro hendikepované nebo pro intenzivní cestovatele...
Než se do toho pustíme, tak si neodpustím ještě jednu odbočku, která s tématem přeci jenom trochu souvisí – zmíníme co zahrnuji pod pojem dotazovací modul, aby bylo jasno, až na něj dále narazíme.
dotazovací modul
Co se dotazování a prohledávání týče, v systému zatím uvažujeme především klasické objektové řešení – dotazy bude možno klást formou volání metod objektů, reprezentujících prvky ontologie. Na jejich základě bude možné v případě potřeby vybudovat abstraktnější neobjektový dotazovací modul pracující s jazykem blízkým přirozenému ve stylu typu SQL nebo OQL. A právě tento modul bude tvořit dotazovací systém. Případné uživatelské rozhraní tak bude moci využívat jak přímých volání API, tak služeb dotazovacího modulu.
Zdaleka nejběžnějším typem uživatelského rozhraní je grafické uživatelské rozhraní (GUI). Jeho vytváření obvykle probíhá jako manuální skládání jednotlivých obrazovek z primitivních komponent, jakými jsou například vstupní pole, zaškrtávací políčka, výběrové seznamy ap. a následné propojení s modelem pomocí tzv. událostí. Komponenty uživatelského rozhraní bývají označovány též jako „widgety“.
Každý programovací jazyk má svou sadu takových komponent, podobně i například jazyk HTML má odpovídající sady formulářových tagů (Forms, XForms, XUL..). V následujících oddílech shrnu možné scénáře ui na příkladech konkrétních technologií. Pokud jsou implementace konkrétních scénářů závislé na konkrétním programovacím jazyce, použiji příklad z Javy.
Z grafických uživatelských rozhraní dosud drtivě převažuje právě tento typ. Vzhled je včleněn do „oken“, ta se skládají z běžných i méně běžných widgetů, převzatých z programovacího jazyka či vývojového prostředí, ve kterém je aplikace tvořena a z jejich derivátů. Je to typický vzhled aplikací vytvořených pro Windows, MacOS nebo třeba X Window. Aplikace postavené na těchto prostředcích pro budování uživatelského rozhraní se obvykle vyznačují například těmito přednostmi:
jednoduchost použití
bohaté možnosti
stabilita, vyspělost, spolehlivost
V Javě byl takovou sadou komponent AWT, tento balík je ovšem zastaralý, nahradil ho nověji JFC, jehož současné verze jsou známy pod kódovým jménem Swing.
Swing
Tato knihovna je svým návrhem, funkcemi a použitelností podle mého názoru jednou z nejlepších vůbec, byť je občas kritizována za svou komplikovanost. Přiblížíme některé její části a schopnosti, jak jsou uvedeny ve specifikaci [J2SDK150] a můžeme je považovat za etalon schopností widgetového systému:
Komponenty - zahrnují vše od tlačítek až k rozdělovačům obrazovky a tabulkám.
Výměnný vzhled a chování - Každý program, který využívá Swing komponenty, si může vybrat, jak mají vypadat a jak se mají chovat.
Například stejný program může jednou vypadat jako klasická MS Windows aplikace, podruhé jako Gnome a nakonec kovově („Metal“ l&f je výchozí). Kdokoliv může vytvořit balíček vzhledu a chování, pokud si z existujících nevybere - v úvahu připadá třeba i využití zvuku místo obrazu.
Usnadnění - API pro zapojení technologií jako např. čtečky obrazu, Braillovy panely
Java2D API - Možnost zahrnout 2D grafiku, text a obrázky
Drag and Drop - Schopnost přetahovat informace mezi Swing rozhraním a nativním prostředím
X Window
Systém X Window, dodávající grafické uživatelské rozhraní UNIXům předběhl dobu - už od svých počátků nabízel i přes „desktop“charakter aplikací možnost pracovat distribuovaně. Tento systém může běžet v režimu na způsob Windows, ale stejně snadno může server zobrazovat programy na dálku, tedy u klienta.
Nevýhodou jsou značné nároky na server a přenosový kanál a také nezbytné softwarové vybavení klienta, proto je použitelný prakticky výhradně na intranetech. Časem, s rozvojem Internetu, se to ale možná změní.
Java applety
Technologie, která umožňuje včlenit aplikaci se Swing uživatelským rozhraním (pouze některé funkce jsou omezené či zakázané) do HTML stránky a výsledek, pokud se zveřejní na internetu, je možné spustit prakticky odkudkoliv.
Zdálo by se, že applety jsou dokonalým řešením, jeho nevýhody ale nejsou zanedbatelné: Například vyžaduje stažení poměrně velikého programu před jeho spuštěním, prohlížeč musí být vybaven správnou verzí JVM a správně nakonfigurován, výsledný applet přeci jenom všechno neumí. Dáme-li vše výše uvedené dohromady, nepřekvapí nás, že tato technologie si udělala špatné jméno svou nespolehlivostí a nestabilitou a proto se používá téměř výhradně v rámci intranetů, kde tyto nevýhody nejsou až tak moc citelné.
Různé aplikace na Internetu jsou (a budou) čím dál významnější, prostředky pro jejich vytváření proto přibývají jako houby po dešti a jsou velice různorodé. Stručné a přehledné srovnání přístupů (nikoliv konkrétních nástrojů) jsem nikde nenašel, proto jsem se tomuto námětu věnoval o trošičku více – koneckonců zajímá nás především použití ontologií v prostředí Internetu. I tak jde ale spíše o pouhý rozcestník..
Populárním termínem v této oblasti je MVC, tedy model-view-controller architektura. I přes svou značnou popularitu toho MVC příliš mnoho neříká a prakticky cokoliv o sobě může prohlašovat, že je implementuje MVC přístup.
MVC
Klíčová myšlenka MVC by se mohla shrnout slovem „oddělenost“. Jednotlivé komponenty aplikace, tedy
model
view (vzhled)
controller (kontroler)
musí být maximálně oddělené jeden od druhého a komunikovat přes co nejužší, jasně vymezené rozhraní. Tato zásada je všeobecně přijímána jako důležitý předpoklad dosažení flexibility a snadné spravovatelnosti.
V dalších částech se zamyslíme nad konkrétními typy MVC technologií pro prostředí webu. Termín „model“ se poměrně dobře kryje s tím, jak zde chápeme „jádro“ – o něm jsme toho napsali už dost, tak jej dále zkoumat nebudeme. Z logického celku „view“ probereme postupy vytváření dynamického obsahu a poté se dotkneme standardů pro vlastní formulářové prvky. O části „controller“ se zmíním na závěr, hodně stručně.
Aplikace na webu, to je vlastně hrst běžných HTML stránek doplněných o dynamiku. Takové stránky musí na jedné straně určitým způsobem prezentovat model (jádro) a na straně druhé zpracovávat uživatelské vstupy. Je možné odlišit dva principiálně odlišné přístupy, jak toho dosahovat někdy označované jako „push“a „pull“.
pull
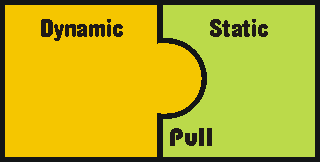
Historicky starší je pull přístup a funguje tak, že do jinak statické stránky „dotáhne“ dynamický obsah. Důležitým momentem je zde to, že tento proces je iniciován a řízen „z pohledu“ statické stránky.
Klasickým příkladem pull technologie jsou skripty včleněné do HTML stránky (ASP, PHP, JSP, ..). Výzkumy i zkušenosti čím dál tím jasněji ukazují, že tento přístup nevede k vytvoření snadno spravovatelné, flexibilní webové aplikace. Základní příčinou je jednoduchý fakt, že není technicky zaručeno, aby obsah, vzhled a logika byly maximálně odděleny a naopak jsou nabízeny prostředky k implementaci koncepčně špatných řešení, která jsou u push technologií technicky neproveditelná. Silná stránka skriptovacích jazyků („moc“ a značné schopnosti) je v důsledku slabinou.
O trochu méně výrazný, ale pořád ještě dostatečně nepříjemný je tento problém u „template engines“ (Velocity, WebMacro, FreeMarker, Tea,...), které jsou principiálně ekvivalentní skriptování. Jejich výhodou je, že to nejsou plnohodnotné programovací jazyky, a tak nabízejí o něco méně možností k prohřeškům. Více v tomto směru např [XMLCJSY02].
Technologie umožňující obojí přístup existují od samého začátku dynamických stránek. Mám na mysli CGI skripty, tedy samostatně spustitelné programy, jejichž jediným úkolem je generovat výsledný kód stránky. V zásadě shodné s CGI jsou servlety (vlastně CGI napsané v Javě). Jakým způsobem si výsledek sestaví, je jejich soukromou věcí - mohou kombinovat kód programu se statickým obsahem (pull) anebo načíst šablonu stránky a vhodně ji doplnit (push).
V zásadě všechny výše uvedené technologie oddělit vzhled, logiku a obsah umožňují, ale žádná z výše uvedených to nemůže zaručit.
Push technologie jsou naopak k takové záruce o dost blíže. Musíte se opravdu snažit, abyste princip oddělenosti porušili, a i to se vám podaří jen částečně.
push
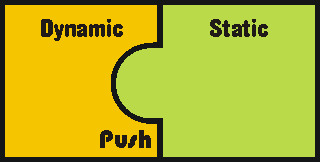
Zásadní, ale velice praktické omezení spočívá v tom, že šablona, zdrojová stránka (nejspíše XHTML) prostě je statická a není žádný způsob, jak to změnit. Program načte ve vhodné podobě tuto čistě statickou stránku a „vtlačí“ do ní na požadovaná místa dynamický obsah. Statická stránka je zde jakýmsi „substrátem“ na kterém program dodávající dynamický obsah pracuje.
 Příkladem
produktu, který implementuje push přístup je
open-source projekt Enhydra XMLC. Návrhář stránek
použije svůj oblíbený editor a pouze místa, kde
má stránka obsahovat dynamický obsah, označí
id atributem a o logiku „dotlačení“ dat se
nestará. XMLC kompilátor z takové stránky
sestaví specifickou DOM (stromovou) reprezentaci, a usnadní
programátorovi přístup k označeným místům,
určeným pro dynamický obsah. Programátor doplní
postup získání dynamického obsahu a
snadno ho včlení do stránky se zachováním
jednotného vzhledu. Tento postup schematicky znázorňuje
obrázek, který jsem si půjčil z [XMLCJSY02]:
Příkladem
produktu, který implementuje push přístup je
open-source projekt Enhydra XMLC. Návrhář stránek
použije svůj oblíbený editor a pouze místa, kde
má stránka obsahovat dynamický obsah, označí
id atributem a o logiku „dotlačení“ dat se
nestará. XMLC kompilátor z takové stránky
sestaví specifickou DOM (stromovou) reprezentaci, a usnadní
programátorovi přístup k označeným místům,
určeným pro dynamický obsah. Programátor doplní
postup získání dynamického obsahu a
snadno ho včlení do stránky se zachováním
jednotného vzhledu. Tento postup schematicky znázorňuje
obrázek, který jsem si půjčil z [XMLCJSY02]:
Obdobou desktopových „widgetů“ jsou pro webové vývojáře tzv. formulářové tagy.
HTML forms
Klasickým řešením jsou HTML forms, tedy HTML formuláře, součást specifikace HTML jazyka. Jsou široce rozšířené a široce podporované. Snadno se kombinují s jinými prvky HTML jazyka, takže výsledná aplikace vypadá v mnoha případech „moderněji“ a „lehčeji“ než její monoliticky působící desktopový dvojník.
Trpí ovšem některými chybami: příliš zjednodušující, míchá obsah a vzhled nežádoucím (správu znesnadňujícím) způsobem, na rozdíl od desktop řešení mají značně omezenou množinou použitelných grafických prvků...
Kandidátem na místo formulářových značek je kromě jiných zejména standard XForms.
XForms
Podpora všech typů prohlížečů včetně handheldů, televizí, počítačů, tiskáren a skenerů
Bohatší uživatelské rozhraní
Oddělení dat, logiky a vzhledu
Snadnější podpora více jazyků
Strukturovaná data
Pokročilá formulářová logika
Více formulářů na stránce a více stránek tvořících jeden formulář
Pozastavení a obnova
Integrace s dalšími XML značkovacími jazkyky
Zdá se, že XForms nemají chybu. Ano, je to dobrý standard, ale stejně jako HTML Forms má jedno podstatné funkční omezení, které způsobuje, že trochu pokulhává za desktop řešeními: vše co zná jsou formuláře. Formuláře je možné pouze vyplnit a odeslat, což je ve srovnání s komfortem desktop řešení docela málo. Více o nich viz [XFORMS].
S formuláři si vystačíme pro dotazovací rozhraní, ale pro další interaktivní práci s ontologií - její procházení, sledování vazeb, operativní úpravy apod. již nejsou příliš pohodlné. Další (a prozatím kritickou) nevýhodou je stále ještě nedostatečná podpora ze strany prohlížečů a vývojových nástrojů.
Jsou zde i další možnosti, například XUL prosazovaný Mozilla Foundation. XForms jsou ale nejdále a vznikly jednáním širokého vývojového týmu, tudíž lze alespoň do budoucna očekávat i jejich silnější podporu.
Existuje mnoho systémů, jejichž hlavním posláním je usnadnit navigaci uživatele po dynamicky generovaných stránkách, sledovat sezení apod. Většina těchto systémů řeší navíc další běžné úkoly související s vytvářením aplikací pro tak heterogenní prostředí, jakým je Internet - např. lokalizace či bezpečnost (security). Spolupracují se systémy pro generování dynamických stránek, z nichž některé jsme zmínili výše.
Patří sem Tapestry, Barracuda, Struts, Turbine a další.
Pěkné srovnání je například na stránkách [WAFEREW] a navíc uživatelské rozhraní jako takové nepatří do jádra navrhované aplikace, proto se tímto námětem nebudu blíže zabývat.
I s mobilními telefony a různými PDA zařízeními je nutno počítat - „mobilní aplikace“ budou pravděpodobně jedním z nosných směrů blízké budoucnosti. Existuje obdoba jazyka HTML (WML), dále speciálně upravený virtuální stroj Javy včetně nejnutnějších knihoven (J2ME) a různé další pomůcky, nástroje, standardy a technologie.
Nebudu zabíhat do podrobností, pouze připomenu, že uživatelské rozhraní na podobných zařízení má svá specifika, především si musí poradit s velikostí displeje zařízení, nesmí také vyžadovat nadbytečné datové přenosy nebo „myšově orientovanou“ výraznou interaktivitu... Každopádně je jasné, že i s mobilními zařízeními při vývoji uživatelského rozhraní bude třeba počítat.
Určité ambice v tomto směru má již zmíněný standard XForms.
Kromě grafických výstupů má význam uvažovat též rozhraní pro slabozraké a nevidomé, např. systémy s Braillovým písmem a zejména zvukové. Rozhraní pro hendikepované vyžadují mnohdy kompletně odlišný přístup.
Nové možnosti se otvírají v souvislosti s pokrokem systémů umělé inteligence z oblasti rozpoznávání mluvené řeči. Vytvoření podobného rozhraní pro složitější aplikace je zatím velice pracné a nevím o žádné běžně použitelné „knihovně zvukových widgetů“. Je pravda, že takováto rozhraní nemají tu nejvyšší prioritu, ale výslovně odmítnout hendikepované lidi by bylo diskriminující a koneckonců asi i obchodně neprozíravé, zejména pokud by řešení příliš nezkomplikovalo návrh jádra.
Například Swing teoreticky umožňuje vytvořit zvukový l&f. Potíž je v tom, že widgety jsou navrženy zejména pro grafická rozhraní, a tak obsahují mnoho informací o tom, jak mají vypadat, kde mají být ve formuláři apod., ale chybí jim specifické informace pro snadnou implementaci zásadně odlišných scénářů. Řešením by byla nějaká mezivrstva, která by obsahovala maximum informací o modelu a ty byla schopna převést či předat jak do specificky grafické reprezentace (např. Swingu), tak do jakékoliv jiné...
Jaké sady widgetů či tagů využít? Tato otázka je poměrně komplikovaná, zejména když je nutné počítat s různými typy klientů. Klasický vzhled má nesporné výhody, ale uživatelé potřebují svá data odkudkoliv, třeba i z internetové kavárny nebo mobilního telefonu. Situace je ještě více komplikovaná tím, že současný stav na poli technologií uživatelského rozhraní není jistě definitivní. Co když bude potřeba v budoucnosti podporovat nějaký další typ klienta? Co když klienti pro námi zvolený typ uživatelského rozhraní přejdou na jiný standard?
Tvrdím, že:
Navrhovaná knihovna by neměla nijak zužovat možnosti volby uživatelského rozhraní. S tím, že API bude sloužit i uživatelskému rozhraní a dotazovacímu modulu je třeba počítat, ale nesmí to snížit kvalitu objektového návrhu. Aplikace nesmí být závislá na použitém uživatelském rozhraní, naopak musí být snadno přizpůsobitelná jakémukoliv uživatelskému rozhraní pouhou rekonfigurací pomůcky, která vytvoří prezenční vrstvu, aniž by se to jakkoliv dotklo jakékoliv jiné části aplikace (objektového modelu, ontologie, jiných podporovaných uživatelských rozhraní či dokonce perzistenční vrstvy). Uživatelské rozhraní musí být odvozeno od objektového modelu, dynamicky se mu přizpůsobovat pokud možno co nejvíce automatizovaně, ale zároveň umožnit „doladění“ podle potřeb uživatelů.
Jak jsem již naznačil, konkrétní uživatelské rozhraní není předmětem našeho nejbližšího zájmu, ale neodpustím si zmínit nástroj, na kterém jsem pracoval a který by mohl pro jeho tvorbu posloužit nebo by mohl být alespoň inspirací. Nástroj dostal název Xermes.
Xermes
Serverová část generuje formuláře uživatelského rozhraní ve formátu nezávislém na konkrétním scénáři uživatelského rozhraní. Tyto formuláře jsou interpretovány klientskou částí Xermesu a přetvořeny do konkrétní podoby komponent uživatelského rozhraní. Veškerá komunikace mezi klientem a serverem probíhá v XML.
Prozatím je vytvořen klientský modul využívající primitivní komponenty knihovny Swing, počítá se ale s klientem pro prostředí Internetu, využívající nejspíše HTML formuláře a XMLC pro snadné včlenění do konkrétních stránek. Podstatné ovšem je, že architektura systému umožňuje doplnit klientskou část pro prakticky každý jmenovaný scénář.
Více informací o projektu najdete na jeho stránkách [XERMES], ty jsou ovšem trochu zastaralé, proto je berte s rezervou.
Pod tento pojem shrnuji několik na první pohled nesouvisejících rozhraní, které spojuje jedno – pokud vůbec vyžadují interakci uživatele, vystačí si s jednoduchým pokynem a jinak spoustu práce vykonají samostatně. Neprobíhá žádný skutečný dialog.
export / import ontologie
Tento modul zajistí interoperabilitu vytvořené ontologie s jinými nástroji pro práci s ontologiemi. Jednotlivé adaptéry budou rozumět konkrétním jazykům reprezentace ontologií (RDF, OIL, KAON...).
Bude třeba více rozebrat, jak si má systém poradit s takovými situacemi, kdy meta model importované / exportované ontologie bude nekompatibilní. Vzhledem k univerzálnosti navrhovaného systému takové situace asi budou nastávat často především při exportech do ontologií s nižší vyjadřovací schopnosti.
sestavy
Tím myslím především statistiky, různé informace o činnosti, součty, porovnání, analýzy, doporučení, všemožné přehledové tiskové sestavy... prostě různé informace vydolované z ontologie, požadované v konkrétním formátu buď pro další zpracování nebo pro tisk.
komunikace
Ostatní typy komunikace, jiné než o kterých jsme doposud mluvili – tedy nikoliv dialog s uživatelem, export nebo import ontologií, hlášení událostí naslouchačům ani sestavy navržené výše. Příkladem může být třeba výměna nastavení a profilů.
Tuším, že dospějeme k řešení, které bude alespoň z pohledu jádra a jeho nejbližšího okolí všechny tyto výstupy integrovat do jednoho univerzálního řešení neinteraktivního rozhraní.
Začněme běžnou věcí – tiskovými sestavami. Ty je možné řešit proprietárním způsobem (jako vše) nebo využít některého ze standardních formátů pro popsání textové informace s přihlédnutím k její grafické podobě. Uvedu některé zástupce a v další části se pak krátce zamyslím nad výstupy, které nesměřují na papír.
Když mluvím o grafické podobě výstupů, nemám na mysli pouze uspořádání textu na stránce, ale i skutečné grafické informace buďto načerpané z externích entit anebo vygenerované – číselné grafy, grafická zachycení struktury částí ontologie apod.
Rich Text Format (RTF)
RTF je formát pro zachycení textu včetně formátování, struktury, dalších vlastností s použitím tisknutelných znakových sad. Mechanizmus „kontrolních příkazů“ nabízí jmenný prostor, který může být využit k definování speciálních znaků, ale také různých vložených objektů, maker apod. [FFORMENM]
Jeho výjimečnost spočívá v tom, že je na rozdíl od silně proprietárních formátů (DOC, WLS, ...) je celkem dobře popsán. Díky tomu může sloužit jako výměnný formát mezi různými textovými editory a kancelářskými balíky, jejichž nativní formáty jsou vzájemně nekompatibilní, ale i jako výstup IS.
OOo 2.0
Nový formát balíku OpenOffice.org byl přijat jako standard sdružením OASIS OPEN a jedná se o jeho přijetí jako ISO standardu. Pravděpodobně se stane formátem výměny dokumentů mezi evropskými vládami a orgány Evropské unie.
Vnitřní struktura je velmi přehledná, tak jak tomu bylo již u formátu předchozího – je to sada XML souborů a použitých objektů zabalená do ZIP archivu – a tak je formát vhodný i pro různé dodatečné transformace.
PostScript (PS) a Portable Document Format (PDF)
PostScript je jazyk určený pro popis stránek dokumentu nezávisle na výstupním zařízení respektive na jeho rozlišení. Tvůrcem tohoto jazyka je firma Adobe. Mnoho laserových tiskáren ho přímo zná, proto stačí dokument na tuto tiskárnu přímo poslat. Pokud tiskárna PostScript nedokáže interpretovat, je k tomu potřeba softwarový interpretr, např. GhostScript.
Základní elementy v PostScriptu jsou Bézierova křivka, úsečka, text lze popsat přímo jako text avšak ve výsledku se písmena kreslí z oblouků. [PSCRPTM97] Rozdíl oproti RTF spočívá ve schopnosti stránku popsat přesně a precizně, tedy tak jak je to třeba pro profesionálnější tiskový vzhled.
PDF vychází z PS, je vnitřně komprimovaný, se zvýšenou přenositelností, podporou Unicode a mnoha jinými výhodami, princip i primární použití je ovšem stejné.
TeX
Viz TeX je fenomén pocházející původně z UNIXů. Pod touto zkratkou se skrývá jak vlastní formát, tak množina programových nástrojů pro sazbu. V současnosti existují různé implementace pro všechny myslitelné platformy.
Principiálně zhruba odpovídá PDF, jeho vyjadřovací schopnosti jsou ale ještě o trochu lepší..
SVG (Scalable Vector Graphic)
Jazyk pro popis dvourozměrné grafiky, založený na XML. SVG zná tři typy grafických objektů:
vektorové grafické tvary (např. cesty skládající se z rovných linií a křivek)
bitmapové obrázky
text.
Grafické objekty mohou být seskupovány, dolaďovány použitím stylů, transformovány, komponovány do předrenderovaných objektů. Mezi interní funkce patří vnořené transformace, ořezové cesty, alfa masky, efekty a šablony. [SVG]
Ano, SVG je především standardní grafický formát - schopnost uchovávat textové informace je až na druhém místě. Je to patrné i z toho, že MIME typ pro SVG je „image/svg+xml“.
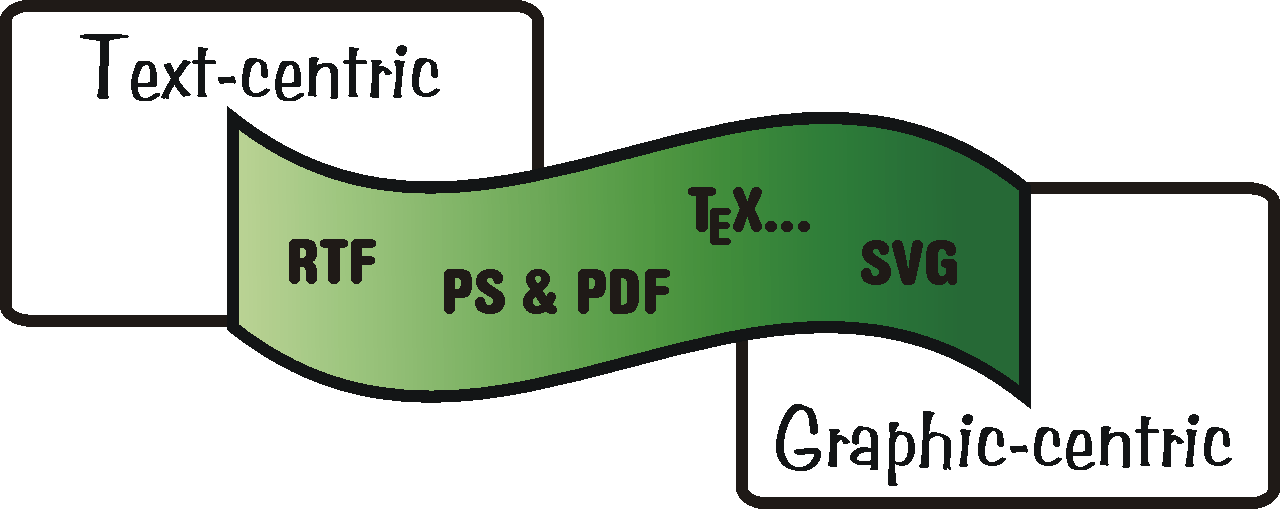 Uvedené
formáty se liší tím, jaký důraz
kladou na textovou a nebo spíše grafickou podobu
informací, které zachycují, proto mají
všechny své opodstatnění a všechny se
více či méně používají.
Uvedené
formáty se liší tím, jaký důraz
kladou na textovou a nebo spíše grafickou podobu
informací, které zachycují, proto mají
všechny své opodstatnění a všechny se
více či méně používají.
Zmiňujeme je všechny proto, že ani jeden z nich nelze zavrhnout a ideální formát se bude lišit podle charakteru a použití sestavy. Systém by je měl svým způsobem podporovat všechny. Klíčem k řešení je dekompozice vrstvy rozhraní na část obecnou, která bude produkovat pouze holá data pro zařazení do sestavy a na část specifickou. Vlastní formát sestaví specifický formátový adaptér. Než se zamyslíme nad detaily, vrhneme se na další kapitolu z kategorie neinteraktivních výstupů..
Již jsme o tom na mnoha místech mluvili, proto pro oživení jen pár příkladů:
prezentace (XHTML)
Elektronický obchod postavený na ontologii bude za běhu generovat XHTML obsah – katalog produktů.
cizí klasický systém (SQL)
Výstupem z ontologie může být být také například SQL INSERT příkaz, který doplní záznam v nějaké cizí databázi. Mám na mysli například nějaké logy, statistická data, informace pro prezentaci, objednávku, reklamaci...
cizí ontologický systém (RDF...)
Na ontologii postavený elektronický obchod našeho distributora průběžně (třeba každou) automaticky aktualizuje svoje data dotazem, který odešle našemu systému. Čeká nová data ve formátu RDF a ta také pokaždé dostane.
klient pro sledování stavu sítě (SNMP)
Administrátor chce mít vždy přehled o tom, co se děje v jeho síti. Systém pro správu je tvořený především několika propojenými ontologiemi. Je zvyklý používat nástroje pro sledování stavu aktivních síťových prvků využívající standardní protokol SNMP. Velmi se mu zamlouvá, že ontologický systém dokáže hlásit změny rovněž v podobě tohoto protokolu – pro sledování nemusí instalovat a zkoumat žádný další nástroj...
elektronické podání (XML)
Je libo daňové přiznání v elektronické podobě, ve formátu založeném na XML?
Základní nevýhoda formátů pro tiskový výstup spočívá v tom, že jsou nevhodné pro jiné použití - informace „chápou graficky“ a neznají význam informací.
Dejme tomu, že pro tiskové výstupy programu použijeme RTF. Ale co když si pořídíme PostScriptovou tiskárnu a budeme chtít využít její schopnosti pro zvýšení kvality výstupů? Tak je převedeme, možná řeknete a s jistými obtížemi se vám to podaří. Ano, tak jiná otázka: Co když podobné výstupy, jaké tisknete, budete posílat ke zpracování „cizímu“ informačnímu systému, spravovaného například ministerstvem financí.
A co když požadovaný formát bude vyžadovat VÍCE informací, než kolik jich je v RTF, takže automatizovaný převod bude znamenat spoustu práce při psaní nějakého převodního programu či schématu a nebo bude principiálně neproveditelný. Ano, přijde to nejhorší - zásah do vlastní aplikace (do metod uvnitř tříd modelu).
Shrneme-li výše uvedený příklad:
Pouze graficky formátované informace jsou takřka nepoužitelné jinak, zejména strojově.
Podobné otázky si můžeme klást i u netiskových výstupů:
Dejme tomu že náš systém bude produkovat SQL příkazy. Ale co když po čase zjistíme, že potřebujeme nikoliv SQL výstup, ale výstup například v nějakém proprietární textovém formátu? Bude to znamenat úpravu informačního systému? A co když budeme chtít ještě části výstupů tisknout? Tady není situace tak kritická, protože SQL, byť je pro výše uvedené použití nevhodný, obsahuje poměrně dost metainformací o charakteru posílaných dat - jsou skryty v použitých názvech tabulek a sloupců.
Změna konkrétního výstupního formátu možná a maximálně snadná a nesmí vyžadovat zásahy do modelu.
Nezbytným předpokladem úspěšného řešení je zachování co největšího množství informací a meta informací v primárním výstupu. Bude-li primární výstup dostatečně informačně bohatý, finálního výstupu docílíme poměrně snadno sestavením transformačního schématu, které ovšem nijak neovlivní vlastní ontologický systém. Transformace proběhne „vně“. Přiložený obrázek [XMLKOSE00] demonstruje snadnost transformace z informačně bohatšího zdroje do informačně chudšího formátu.
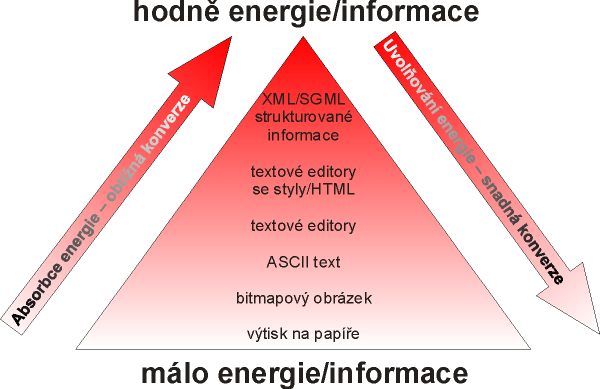
Jaký formát dokáže zachytit v zásadě libovolné informace, aniž by je nějak „okleštil“? Už nebudu dále chodit kolem horké kaše a řeknu to na rovinu: pro primární výstup použijeme XML s vhodným schématem, a ten transformujte dle XSLT šablony do výsledného výstupu.
Co je XML, XSLT, schéma a podobné věci vysvětlovat nebudu – o tom již byly popsány napsány mnohé stohy papíru. Pouze zmíním jeden nástroj, který by mohl usnadnit a zpřehlednit generování různých výstupů z různých XML zdrojů, pokud by se situace ve vašich výstupech stala nepřehlednou.
Apache Cocoon
Systém pro pro usnadnění provádění hromadných transformací. Je vhodný především pro generování stránek pro WWW prezentace z všemožných datových zdrojů - především z XML.
Je ale navržený natolik univerzálně, že by mohl výhodně posloužit i jako vrstva ontologického systému zodpovědná za vytváření konečných neinteraktivních výstupů, ovšem toto použití jsem zatím neověřil v praxi.
Jak bude vypadat architektura navrženého neinteraktivního rozhraní? Trochu jsem pozměnil původní návrh architektury a znázornil jsem pouze na ty části systému, které mají přímou souvislost:
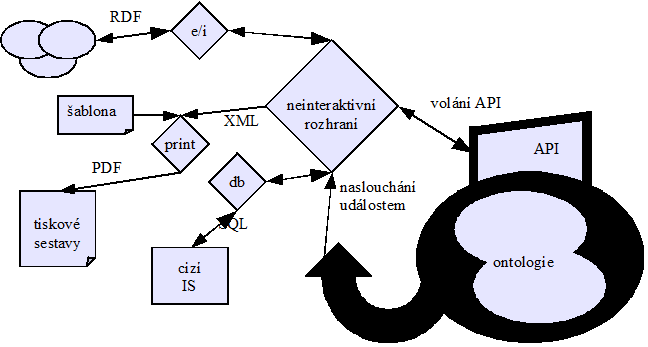
A co bude finálním výstupem? Cokoliv, pro co bude napsán adaptér. Jak jsme již zmiňovali, každý formát má svá pro a proti a zejména svá vhodná a nevhodná použití. Při implementaci pluginů budu sám dávat přednost formátům standardním před proprietárními, ale každý nechť sestaví adaptér pro to, co je mu milé.
Jádrem každé aplikace je její
vnitřní logika
struktura dat
a procesů nad nimi
To zde označuji jako model, v našem případě ontologický model. Modelu „slouží“
nějaké úložiště, které dodává datům trvalost
a dále uživatelské rozhraní.
Tyto funkční celky můžeme chápat v ideálním případě jako uzavřené subsystémy, které navenek komunikují pouze přes konkrétní veřejná rozhraní. Vzájemné vztahy mezi těmito subsystémy definují architekturu systému, tak jak jsme ji doposud chápali.
infrastruktura
Nasazení na konkrétních počítačích nebo počítačových systémech. U každého programového subsystému nás zajímá, ve spojení s kterým dalším programovým subsystémem je umístěn na společném počítačovém systému.
Ještě zmíníme nějaké ty standardy, vhodné pro realizaci komunikace mezi komponentami:
SOAP
SOAP definuje mechanismy pro výměnu strukturovaných a typových dat ve formátu XML mezi účastníky v decentralizovaném, distribuovaném prostředí. Specifikuje formální podobu zpráv (XML Infoset) včetně abstraktního popisu obsahu.
Je bezstavový, vybudovaný podle paradigmatu jednosměrné výměny a je až na konkrétních aplikacích, zda jej obohatí o složitější vzor interakce – požadavek/odpověď, požadavek/mnoho odpovědí atp. SOAP nedefinuje jaká data mohou být přenášena zabývá se zejména směrováním, garancí doručení, průchodem firewally.. Aplikacím pouze doporučuje, jak má být zpráva zpracována a jak mohou být vhodně reprezentována data. [SOAP12]
Použití ontologických dat uvnitř SOAP obálky se úplně nabízí..
RPC, XML-RPC, CORBA, RMI
Různé metody vzdáleného volání procedur a metod a využívání vzdálených komponent. Nosnou myšlenkou všech uvedených metod je integrace systémů v zásadě běžících v různém prostředí, na vzdálených počítačích, pod jinými systémy a kromě RMI i napsaných v rozdílných jazycích..
Připadá v úvahu několik typických infrastruktur.
Na okraj poznamenávám, že obrázky jsou UML diagramy nasazení, krabice v nich znamená hardwarový prostředek, nejspíše počítač.
Nejběžnějším řešením v jednouživatelském prostředí je nevrstvená infrastruktura. Obvykle všechny části aplikace běží na jednom stroji, výhodou je jednoduchost ve všech směrech - jednoduchá výroba, jednoduché testování, jednoduché nasazení. Implementačně jde o první řešení, které by nás asi napadlo, kdybychom se infrastrukturou vůbec nezabývali.
Není použitelná v distribuovaném prostředí, kde například s jednou ontologií pracuje více lidí.
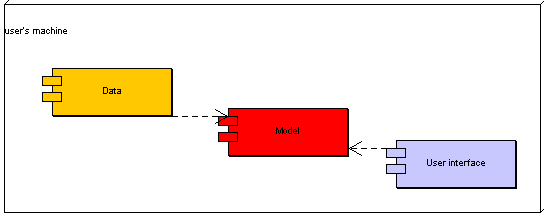
Z užití, kterými jsme se podrobně zabývali takto bude typicky vypadat třeba aplikace pro organizaci dat, provozovaná jediným uživatelem, který si v ní uspořádá třeba svou sbírku písniček a fotografií.
Základní způsob jak umožnit více uživatelům pracovat se sdílenými prostředky (v našem případě ontologií), je vytvořit server, který bude tyto prostředky poskytovat klientům, kteří je budou naopak využívat. V oblasti kritických aplikací je tato infrastruktura spíše na ústupu ve prospěch modernějších struktur, které popíšeme dále, přesto ji ale nemůžeme opomenout.
Data je nutné sdílet prakticky ve všech případech, ale z hlediska umístění aplikační logiky připadají v úvahu dvě varianty:
Pokud klient obsahuje kromě uživatelského rozhraní i aplikační logiku, je to mohutný klient (thick client). Pro nás by to nejspíše znamenalo pouze oddělení databáze od ontologického systému jinak nasazeného na jediném stroji. Z hlediska implementace je to řešení snadné, pouze v nastavení databázového konektoru bude třeba udat adresu počítače s databází a tím veškeré rozdíly oproti celodesktopovému řešení končí.
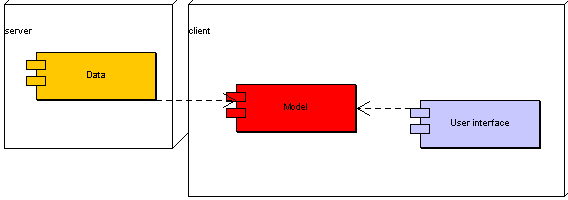
Tento model by se uplatnil třeba v situaci, kdyby bylo třeba ke stejné ontologii přistupovat z více míst, ale bez složitější spolupráce mezi uživateli – například správce sítě chce mít přehled i doma, tak vždy než odejde z práce ukončí ontologickou aplikaci a když přijde domů spustí si ji na svém soukromém počítači. Aplikace se připojí na vzdálenou databázi a administrátor má dále přehled a může ontologii třeba i upravovat.
Klient, který neumí nic jiného, než zprostředkovat uživateli přístup k datům a programové logice tím, že se spojí se serverem je tenký (thin). Takovým klientem může být například prohlížeč internetových stránek („browser“), který žádnou logiku konkrétní aplikace už ze své podstaty obsahovat nemůže.
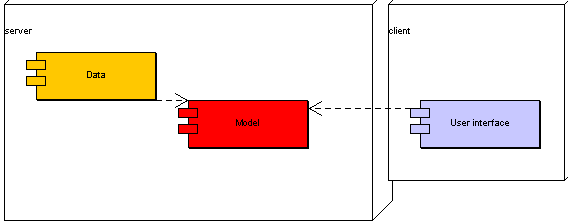
Typickým užitím je třeba elektronický obchod postavený na ontologii.
Je-li každý popisovaný systém maximálně autonomní, je to třívrstevná infrastruktura (three-tier, multilayered)
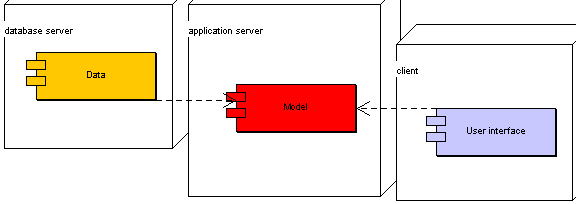
Tato varianta je každopádně nejsložitější, ale přináší mnohé výhody například: [TRILAYCH]
snadná zaměnitelnost úložiště nebo prezentační vrstvy
snadnější škálovatelnost a z toho plynoucí nižší nároky na hardware
snadnější integrace starých systémů
lepší odolnost a výkon
Tyto výhody ji předurčují pro použití ve složitých podnikových systémech, obchodních aplikacích, tam kde k jedné ontologii bude přistupovat spousta uživatelů, půjde o bezpečnost, výkon...
Tím jsme prozkoumali konvenční a klasické infrastruktury, teď přidáme pár méně běžných, o to ale zajímavějších a možná i perspektivnějších...
Nejde přímo o typ infrastruktury, ale úzce s tím souvicí.
SaaS je někdy popisována jako hlavní výzva pro komunitu výzkumníků v oblasti systémového inženýrství. Jde o souhrn technologií a metod pro rychlý a efektivní vývoj a evoluci (a to i ve smyslu dlouhodobé správy) počítačových systémů. Jádrem je premisa, že uživatel považuje software nikoliv za produkt, ale za službu. Když pořizuje software, nejde mu o krabici, ale o to, co mu přinese. [SAASLBM04]
Aplikace vystavěné podle zásad SaaS mají infrastrukturu, která přímo směřuje k dynamické integraci. Výhody takového pojetí jsou zřejmé – částečně čerpám z [SAASWHC04].
Jedna aplikace nabízí funkčnost, kterou potřebují mnozí. Díky tomu, že je pojímána jako služba je univerzálnější – neliší se v různých nasazeních.
Umožňuje nastavení a parametrizaci, ale SaaS model na druhou stranu brání klientům, aby si vymýšleli zbytečnosti. Vynucuje dobré mravy při vývoji i při používání. Brání znovuvynalézání kola. Šetří peníze a čas.
SaaS informační služba přináší informace agregované z mnoha zdrojů, prezentuje je unifikovaně, v příjemném webovém rozhraní. To je vlastně i původní myšlenka portálů.
Typickým modelem provozu SaaS software je hosting; hostované služby je snadnější provozovat. Částečně kvůli limitovaným možnostem parametrizace, částečně proto, že nemusíte kupovat hardware ani software, instalovat atp.
O to vše se postará poskytovatel – vám jde o službu. Vy nemusíte nic spravovat, opravovat, upgradovat, udržovat, kontrolovat – za to vše ručí on. Dostanete vyzkoušenou aplikaci sestavenou z komponent (služeb) a nemusíte najímat vývojáře a správce.
Ceny SaaS jsou predikovatelné (reprodukované) a typicky odvoditelné od intenzity používání.
Nezávislost. Pokud dodavatel neplní očekávání, je neobyčejně snadné se „přepnout“ na jiného. Toto vědomí udrží dodavatele bdělé a ochotné pomáhat a spolupracovat.
Do našeho ontologického pojetí to vše zapadá velmi dobře – rovněž usilujeme o integraci, nezávislost, flexibilitu.
Architektura, která má mnohé rysy společné se SaaS, zejména schopnost dynamicky vázat služby a protože jsou službami vlastně komplexní data, jde o Data as Service (DaaS). Ano, přímým cílem je integrace heterogenních datových zdrojů.
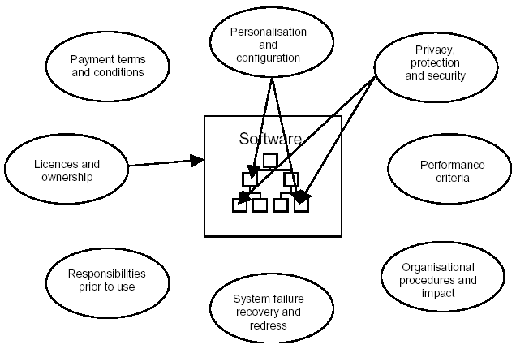
V
centru dění je broker (zprostředkovatel), který
agreguje informace z různých systémů, transformuje je a
zprostředkovává pro další použití.
Takovou integraci velmi usnadní sdílený slovník,
na kterém se třeba ve spolupráci s nějakou nezávislou
autoritou dohodnou zúčastněné subjekty.
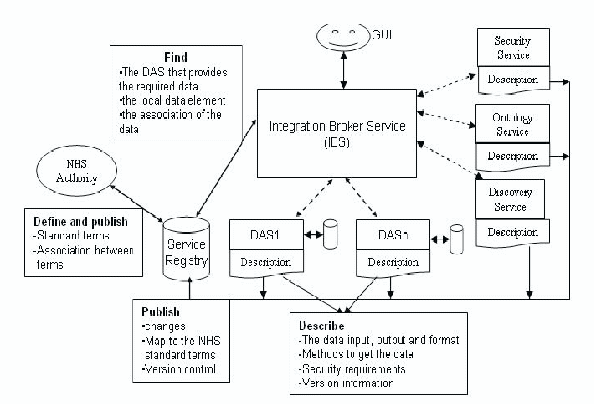
Zajímavý projekt architektury service brokeru v prostředí nemocnic a zdravotní péče dostal název IBHIS. Jeho cílem je poskytnout koncovým uživatelům unifikovaný pohled na data z mnoha zdravotnických zařízení a institucí. Autoři navrhli Architekturu integrace dat orientovanou na služby (SODIA). Na rozdíl od SaaS jejich systém nevyhledává poskytovatele služeb na základě funkcionality, ale spíše na poskytovaných dat. [IBROKER04]
Jak do tohoto scénáře zapadají ontologie?
mohou být těmi daty, která jsou agregována
mohou sloužit jako zprostředkovatel, jako společný slovník
mohou doplnit jiná data (relační, dokumenty..) o jejich význam – viz meta ontologie a třeba tématické mapy.
Další perspektivní a bouřlivě se vyvíjející typ infrastruktury. Systémy jsou občas popisovány v analogiích s přírodou – v pojmech jako ekosystém, společenstvo, symbióza. Základní myšlenka je prostá - na rozdíl od všech předchozích modelů zde není žádné centrum, žádný nadřazený kus softwaru, který by ostatním diktoval co mají dělat. Místo toho vedle sebe působí předem neurčený počet nezávislých programových instancí, ty se vzájemně vyhledávají, dorozumívají, poskytují a využívají služby.
Jaké to přináší výhody?
výhody architektury nezávislých agentů
Vyšší odolnost – nejsou zde žádná zranitelná centra. Živelná pohroma, útok konkurence, vládní agentura (ani všemocná RIAA), válka – nic z toho neohrozí systém samotný.
Vyšší výkon a škálovatelnost – nejsou zde úzká místa, výkon celku je teoreticky neomezený. Extrémní škálovatelnost předurčuje agentní systémy třeba pro využití pro budování výpočetních klastrů nebo technologie grid computingu.
Pro komunikaci mezi agenty je zřejmě ideální Internet. Takové distribuované pojetí Internetu mnohem více odpovídá záměrům původních jeho tvůrců, než současný systém službami napěchovaných, mnohdy mohutných a zranitelných serverů. Web je vlastně krok zpět k určité míře centralismu.
Kromě úplně decentralizovaných řešení existují různá přechodová stádia – některé spíše podpůrné služby může poskytovat jeden nebo více k tomu určených serverů. Nejde ale o řízení, ale spíše podporu – pomoc při objevování ostatních agentů, překládání komunikace mezi nimi apod. Častým řešením je, že sice existují servery, ale těch je předem neurčený počet. Seznamy aktuálně dostupných serverů jsou neustále dynamicky aktualizovány s přispěním klientů – ti se vzájemně o serverech informují, informace předávají serverům samotným a ty je opět šíří dále...
Ve všech těchto případech se přímo nabízí použití ontologie při komunikaci – pro sdělování požadavků, odpovědí, pro popisy nabízených dat a služeb.. Ve skutečnosti různé platformy pro budování agentních systémů s využitím ontologií počítají.
Takovou infrastrukturu mají dnes tolik oblíbené P2P systémy pro sdílení dat nové generace. Agenty a P2P systémy lze ale samozřejmě využít i ke skutečně seriózním účelům, například k budování samoučících se repozitářů, viz [P2PLTDN].
Inteligentní informační agent je opět autonomní a adaptabilní počítačový program, pracuje obvykle v prostředí počítačových sítí, spolupracuje s různými systémy a databázemi. Technologie kombinuje umělou inteligenci (uvažování, plánování, práce s přirozeným jazykem atd.) s technikami vývoje inteligentních systémů (objektově zaměřené plánování apod.). Inteligentní agent má tyto typické rysy [INTAGEM04]:
autonomní působnost
Schopnost provádět uživatelem definované úlohy nezávisle na uživateli a často i bez přítomnosti nebo vedení uživatele. Uživatel jednou specifikuje co, kde a kdy má agent vykonávat, a ten provádí daný úkol pouze tehdy, když nastanou vhodné podmínky.
přizpůsobivé chování
Schopnost napodobovat jednotlivé uživatelovy kroky během provádění úlohy. Například si agent může uložit do paměti různé reakce uživatele na dané situace a podle toho potom sám provádět rozhodnutí apod.
mobilnost
Schopnost volně procházet počítačovými sítěmi a vykonávat úlohy na vzdálených místech. Agenti jsou většinou tvořeni přeložitelným scriptem, který napomáhá bezproblémovému pohybu přes různé architektury sítí. Například komunikačně orientovaný script jako Telescript může ulehčit vzájemnou komunikaci mezi jinými agenty, kteří jsou uloženi na odlišných procesorech.
kooperativní chování
Schopnost dvousměrné komunikace mezi agenty, kteří pak mohou společně provádět větší a komplexnější úlohy.
Například pan X pošle panu Y elektronický dopis, který musí být neprodleně doručen. Agent nesoucí dopis od pana X se spojí s agentem pana Y a ten mu sdělí, že pan Y je na dovolené, tudíž je lepší zprávu odfaxovat sekretářce pana Y.
Agent může provádět takové věci, jako
filtrování elektronické pošty
organizování schůzek
lokalizování požadovaných informací
upozorňování na vhodnou možnost investice
zjištění nejvhodnějšího dopravního spojení.
Uživatelé jsou v současné době zahlceni obrovským množstvím informací, které se na ně ze všech stran valí – vede to k informační zahlcenosti, možná až úzkosti či apatii. Proto potřebují získat žádané informace v co nejkratší době, bez zbytečného šumu. Agenti mohou pomoci roztřídit a profiltrovat data do lehce manipulovatelného a přehledného množství relevantních informací, přesně podle požadavků a potřeb uživatele.
Čím dál více lidí intenzivně cestuje, ale zároveň musí být stále k zastižení. Elektronické zprávy je třeba inteligentně směrovat a filtrovat.
A obecně, jak se tempo života zrychluje, je třeba minimalizovat čas strávený nad rutinními úkoly, aby se člověk vůbec také někdy dostal k odpočinku, zábavě, ke svým koníčkům apod.
Při tvorbě konkrétní aplikace je zde dilema – funkce a komplexnost versus jednoduchost. Distribuované systémy na jedné straně umožňují dostat funkce a data tam, kde jsou potřeba, ale na druhé straně zvyšují složitost. Klient/server systémy mají tendenci být mnohem komplexnější než konvenční desktop architektury. Zmiňme jen pár zdrojů této složitosti: GUI, vrstva aplikačního serveru, heterogenní platformy. Je zřejmé, že je často nutné volit mnoho kompromisů v zájmu snížení složitosti na zvládnutelnou úroveň. [CLSERRK97] Jinými slovy někdy je chybou zvolit nevrstevnou architekturu, jindy je zase chybou distribuovat.
Ontologický systém proto nesmí infrastrukturu jej využívající aplikace v žádném případě diktovat. Musí být snadno škálovatelný, a to nejlépe z jednoduché desktop aplikace, přes různé klient server modifikace, až po třívrstevný model s aplikačním serverem uprostřed.
Celé jádro musí být navrženo co nejlépe, bez specifik pro nějaké konkrétní finální nasazení. Přechod mezi různými typy infrastruktury by měl být realizovatelný pouhou rekonfigurací podpůrných nástrojů, které „obalují“ ontologický model.
Přílohou práce je CD. Najdete na něm především:
první prototyp knihovny ELONT (ELastic ONTtology)

Tak jsem nazval knihovnu pro práci s široce konfigurovatelnými ontologiemi jejíž analýza a návrh byla předmětem značné části dokumentu. Na CD najdete především:
UML diagramy knihovny, především diagramy tříd, ve formátech
ZARGO – Formát open source modelovacího nástroje ArgoUML.
XMI – výměnný formát pro UML modely
Zdrojový kód v jazyce Java.
Jednotkové testy v jazyce Java pro ověření funkčnosti jednotlivých klíčových částí knihovny a zajištění kvality a konzistence i v případě budoucích úprav a rozšiřování.
API dokumentace - popis rozhraní pro programátory, kteří by knihovnu rádi vyzkoušeli.
HTML, podle zvyklostí JavaDoc
Binární podoba knihovny
JAR archiv pro použití v aplikacích
Všechny cizí knihovny, které jsou pro běh prototypu nezbytné
První prototyp aplikace (pro změnu nazvané) ELORD (ELastic ORDer)
Je to ta aplikace pro organizaci dat, kterou jsem zmiňoval v příslušné případové studii
UML diagramy knihovny, především diagramy tříd, opět ve formátech
ZARGO
XMI
Zdrojový kód v jazyce Java.
Binární podoba aplikace včetně cizích knihoven, které jsou pro běh nezbytné
A v neposlední řadě...
Tento text
Celá tahle práce v elektronické podobě, a co víc, krásně barevně, a k tomu ještě hned v několika formátech najednou:
OpenOffice.org – zdrojový formát, práci jsem vytvářel v textovém procesoru tohoto kancelářského balíku.
PDF – vyexportovaný z formátu zdrojového, je vhodný především pro tisk.
HTML – vyexportovaný z formátu zdrojového, je vhodný především pro prohlížení v elektronické podobě.
internetové aplikace
Prozkoumali jsme souvislosti, východiska internetových aplikací a trochu jsme je systematizovali. Také jsme prozkoumali trendy v této oblasti a pokusili jsme se predikovat budoucí vývoj. Za klíčový považujeme trend stále vyššího propojování až integrace, a to na mnoha úrovních - u aplikací, lidí i celých společností. Společnost budoucnosti bude virtuální.
ontologie
Probrali jsme také základní východiska ontologií a částečně i jiných formalismů. Zamysleli jsme se nad jejich současným významem a použitím a navrhli jsme mnohé další aplikace, z nichž některé jsou zatím na okraji zájmu a jiné zatím nebyly vůbec zvažovány. Provedli jsme několik projektových studií, abychom vybrané aplikace prozkoumali blíže, zejména s ohledem na navrhovanou knihovnu.
univerzální meta model
Především jsme rozebrali vlastní parametry této knihovny – meta model, provozní a konfigurační požadavky. Dospěli jsme při tom k zajímavým skutečnostem a návrhům. Za všechny jmenujme třeba:
dilema instance
výhody a nevýhody různých typů dědičnosti a jejich důsledky pro jednotlivé partie ontologie
dva obecné způsoby zachycení hierarchie (kategorizace a dědičnost)
doména atributů tvořená datovým typem a relevancí (inspirace rámci)
mnohé prostředky zvýšení robustnosti:
vyžádání a podsouvání
rozhodovací řetězce jako aplikace myšlenek z oblasti firewallů
celý mechanismus vynucené integrity
odvozené atributy, automatické vazby, vícenásobné a multilaterální vazby
přesun hierarchie vazeb z meta modelu na úroveň modelu
transakční modul jako důsledná aplikace návrhového vzoru naslouchače použitelný třeba pro
zachycení faktoru času a statistiky
návraty v historii úprav
informování zájemců protokolem RSS
pokročilé možnosti konfigurace, především režimy, módy a profily
analýza a návrh knihovny
Myslím že se nám tak nakonec podařilo splnit hlavní cíl, totiž navrhnout univerzálně použitelnou knihovnu pro práci s ontologiemi. Při návrhu jsme měli stále na paměti současný stav poznání v oblasti ontologií a zejména potřeby aplikací, které by na knihovně mohly být vystavěny. Nakonec jsme se zmínili o technologiích a možných architekturách těchto aplikací, abychom podchytili další důležité důsledky pro knihovnu samotnou. Po celou dobu jsme hledali možnosti spojení až integrace, lepší komunikace, a to zároveň s požadavky flexibility a nezávislosti, jako základem pro snadnou správu a možnost budoucího rozvoje.
prototyp
Myšlenky teoreticky odvozené jsme si částečně ověřili na prototypu. Jak již vyplývá i z jeho označení, ten sice není zatím použitelný v produkčním prostředí, ale poskytuje základ pro další zkoumání, zpřesňování návrhu, a především budování dalšího prototypu a snad časem i skutečně použitelné knihovny...
Myslím, že je mnoho cest, kterými by se mohl ubírat další výzkum námětu práce.
Zejména:
Podrobněji zkoumat důsledky integračních procesů
Rozpracovat další nastíněné aplikace ontologií do podoby projektových studií
Projektové studie rozvést do analýzy a návrhu konkrétních aplikací
Zkoumat další vlastnosti a důsledky meta modelu, jak byl v práci představen
Shrnout a podrobněji rozpracovat mechanismy vynucené integrity
Rozpracovat a přesně specifikovat prozatím neformálně uváděné jazyky pro definici různých parametrů meta modelu a tvorbu ontologie samotné anebo nalézt vhodné specifikace existující
Pokračovat v práci na knihovně pro reprezentaci ontologií, která je zatím pouze ve fázi prvního prototypu
S funkční knihovnou v ruce obohatit mnohé aplikace, o nichž byla řeč
Abecední rejstřík
A
agent
inteligentní 32, 45, 48, 224
webový 48
AIAI 34
API 111, 167, 170, 172, 174-176, 195, 199-201, 208, 227
ArgoUML 227
architektura
modelem řízená 26
modelu podřízená 172
asistent
informační 45
ASM 111, 172
atribut
doporučený 137
finální 131
konfigurace 165
nemodifikovatelný 138
odvozený 138
požadovaný 137
vazby 140
volitelný 137
výchozí 138
B
B2B 13, 14, 50, 73, 74
B2C 12-14, 49, 73-75
B2G 13, 14, 50
báze 153
BitTorrent 41
blog 9, 11
BMO 35
bot 48
brokering 50
C
C++ 127, 130, 183, 185
C2C 12, 49, 73
CGI 89, 203
CLIPS 181
clustering 39, 42, 113, 223
CMP 195, 196
Cocoon 89, 215
Compiere 110
CORBA 82, 217
CREAM 28
CRFreeNet 42
Cyc 30-32
CYCL 28
chainlink
decisive 146
D
D&S 41
DAML 28
dědictví
odmítnuté 151
selektivní 151, 168
zaručené 151
dekorátor 163, 167, 168
dilema instance 87, 115, 120
Direct Connect 41
discovery
semantic 45
DL-workbench 28
Dolce 34
dolování 11, 29, 32, 43, 45, 180
Dspace 28
E
e-marketplace 13
e-shop 12, 75
EDI 13, 74
eDonkey 10, 41
efekt 153
ELONT 227
ELORD 227
entita
externí 176
eXist 195
F
firma
virtuální 14, 47
FreeMarker 203
fulltext 39, 72
G
galerie 9
graf 9, 14, 17, 18, 20, 22, 25, 28, 85, 97, 140
grid computing 223
groupware 10, 37, 109, 110
H
hendikepovaní 81
Hibernate 197
hodnota
atributu 132, 154
hyperlink 39
I
ID3 46, 62
identifikátor
atributu 132
identita 124
inference 21, 25, 27, 28, 32
infrastruktura
nevrstvená 217
s mohutným klientem 218
s tenkým klientem 219
třívrstevná 219
instance
atributu 132, 138
vazby 139
Internet 13, 37, 38, 76, 206, 223
inženýrství
ontologické 27, 34
IRE 153
J
J2ME 206
JADE 153
JAR 227
Java 66, 81, 85, 127, 129, 135, 183, 186, 188-190, 195, 197, 201, 227, 228
Java applet 201
JavaDoc 227
JAXB 190
JDO 195-197
Jena 28
jméno
vazby 139
JOX 190
K
Kactus 28
Kaon 29
kategorizace 43, 46, 47, 123-125
dynamická 124, 155
KBML 190
KIF 28, 32
klient
mohutný 218
tenký 219
kompozice profilů 169
komunikace 23, 46, 202
komunita 27, 42
koncept
atributu 132, 133
vazby 139
konceptualizace 16, 22, 57, 90
kruh 18, 28, 124
KSL 27, 34
L
LDAP 47, 189, 194, 195, 197
LISP 180, 186
listener 82, 159
M
map
topic 29, 121
mapa
tématická 29, 121, 122, 222
mapování 27, 29, 77, 108, 190-192, 195, 197
matching 45, 50
MDA 11, 26
mechanismus
podsouvání 138
vyžádání 137, 168
MILO 32
mining 193
mód 170, 171
mříž 17, 19
MUD 10
MVC 202
N
naslouchač 78, 82, 84, 103, 158, 159, 165, 172, 174, 209
navigabilita 140, 141
název
atributu 132
negace 156
nekonzistence 40
nesoulad
impedanční 192
O
Object Pascal 183
ODMG 191, 195, 197
OIL 28, 30, 209
OilEd 28
OJB 176, 197, 198
OLAP 193
OntoKhoj 34
ontologie
doménově specifické 23, 64, 70, 71, 74, 78, 88, 98, 142
evoluce 30
meta 53
mnohojazyčná 41
oborových typů 134
pro podniky a obchod 30, 34
samohodnotná 53, 83, 103
spojování 29
top-level 23, 28, 30, 66, 78, 175
transformace 30, 77
znovupoužití 29, 108
OntoMap 34
OntoWeaver 28
OODBMS 191, 197
opaření
informační 46, 163
OpenCRX 11, 110
OpenLDAP 194
OWL 28
P
PDF 63, 122, 210, 211, 228
personalizace 42
Plone 9
popiska
atributu 132
vazby 139
portál 7, 8, 34, 38, 43, 109, 220
portlet 7
PostgreSQL 89, 90, 191
predikát 17, 138, 148, 153, 155, 156
probublávání 87, 159
profil 44, 49, 120, 163, 166-170, 175, 209, 225
profil
bezmocný 167, 168
jednoznačný 167
silný 167, 168
slabý 167
široký 167
úplný 167
úzký 167
prohledávání 39
Prolog 153, 181, 186
Protége 28
přejímání
atributů 125, 129, 131
hodnot 125, 130
přenositelnost 182, 184-187, 211
přetěžování
atributů 129
PS 210, 211
pull 202, 203
push 87, 202-204
Python 184, 186, 188
R
rámec 26, 27
RDBMS 178, 191, 192, 197
RDF 28, 30, 209, 212
RDFS 28
redundance 3, 40, 51, 57
relevance domény 136
režim 148, 170, 171
RMI 82, 217
robustnost 102, 137, 146, 179, 189
rozhodnutí
pomocné 147
ukončující 147, 149
RPC 217
RSS 160
RTF 122, 210, 211, 213
RuleML 28
S
SaaS 45, 220-222
samohodnotnost 53, 121, 168
sanity 100
sémantika
ontologická 45
sémantizace 43
serializace 189, 190
servlet 89, 203
Scheme 180, 181, 186
síla profilu 167
síť
charakterizační 87, 167
definiční 20, 22
hybridní 21
implikační 21
prohlašovací 21
sémantická 19-22
učící se 21
vykonatelná 21
Smalltalk 183, 188
SNMP 47, 213
SOAP 13, 82, 216, 217
součet
logický 156
součin
logický 156
SoulSeek 41
specializace profilů 169
strategie
duplicity 162
likvidace 160
vývoje 160
strom 17-19, 28, 47, 56, 63, 70, 121, 124, 194, 204
SUMO 28, 32, 33, 142
SVG 211
Swing 175, 200, 201, 207, 208
symlink 56
systém
adaptivní 48
aukční 13
CRM 11, 37, 79, 108-110
ERP 12, 110
inzertní 13
P2P 10, 41, 42, 48, 224
pro správu dokumentů 3, 8, 46, 56, 57, 109, 179
publikačně - aplikační 9
publikační 9, 147
redakční 9
wiki 9-11, 85, 124
znalostní 11, 12, 48
T
Tamino 195
tangled 18, 28
Telescript 225
testy
jednotkové 111, 227
TeX 211
transakce 100, 191, 196
typ
datový 104, 132, 133, 135, 137, 139
jednoduchý 134
komplexní 135
kořenový 136
literál 136
mapa 135
násobný 135
uživatelský 134
U
událost 78, 79, 84, 157-159, 165, 168, 176, 199, 209
UML 25, 217, 227
V
váhy 21
vazba
dynamická 155
jednosměrná 39, 140, 216
konfigurace 166
meta modelu 141
modelu 142
multilaterální 143, 144, 166
násobná 145
neorientovaná 139-141, 143
netypová 136, 139
obousměrná 39, 140
orientovaná 62, 115, 125, 139-141, 179, 181, 183, 191, 192
Velocity 203
vize 14, 37
VOM 28
vrstva
perzistenční 82, 189
vyloučení
generální 151
specifické 151
výraz
regulérní 72, 134
vyžádání
obecné 152
specifické 152
W
web
samoanotovaný 42
sémantický 29, 34, 42
WebMacro 203
webmail 10
Webmin 94
WebODE 28
widget 199, 200, 205, 207
wildcard 72
WML 206
WordNet 30, 33
workflow 10, 46, 109
X
X Window 200, 201
Xermes 82, 208
XForms 199, 205-207
Xhive 195
Xindice 195
XML 13, 61, 66, 67, 89, 90, 93, 122, 179, 189, 190, 194, 195, 205, 208, 210, 211, 213-217
XML databáze 89, 90, 194
XMLC 204, 208
XSLT 214, 215
Z
Z/EVES 28
ZARGO 227
znovupoužití 23, 25, 27, 41, 42, 78, 108, 169
ZoDB 85, 157
Zope 9, 157
Ř
řetězec
rozhodovací 146, 148, 166
Š
šíře profilu 167
ú
účastník
vazby 140
úzkost
informační 46, 225
Seznam použité literatury
BYZNETH99 Delejte byznys na Internetu - Jirí Hlavenka, 1999 Computer Press 8072261827
GRPWREB Collaborative Groupware Software - Grant Bowman, (http://www.svpal.org/~grantbow/groupware.html)
WIKIDEF What Is Wiki - kol., (http://wiki.org/wiki.cgi?WhatIsWiki)
OWIKIZF OpenWiki - Zejda David, Faust Michal, (http://www.o-it.info/) Open-IT cz, s.r.o.
FRDICTH The Free On-line Dictionary of Computing - Denis Howe, (http://www.foldoc.org/)
OPECRXK OpenCRX - CZ stránka projektu - David Klíma, (http://www.dknet.cz/Default.aspx?alias=www.dknet.cz/opencrx)
KMFAQ98 Answers to Frequently Asked Questions About Knowledge Management - kol., (http://www.mccombs.utexas.edu/kman/answers.htm) 1998 Graduate School of Business, University of Texas at Austin
ZTECHMP02 Znalostní technologie - ucební texty - Peter Mikulecký, Daniela Ponce, (https://oliva.uhk.cz/public/ZT2/index.html) 2002
SERVIYHP01 Service Deployment for Virtual Enterprises - J. Yang, W. J. van den Heuvel, M. R. Papazoglou, (http://portal.acm.org/ft_gateway.cfm?id=545634&type=pdf) 2001 IEEE, University of Tilburg, Infolab
VPRINBD01 Virtual Enterprises - Building Blocks for Dynamic e-Business - Nitin Nayak, Kumar Bhaskaran, Raja Das, (http://doi.ieeecomputersociety.org/10.1109/ITVE.2001.904491) 2001 IEEE, IBM
MATHBKS01 Mathematical Background - John F. Sowa, (http://www.jfsowa.com/logic/math.htm) 2001
DEFDICS97 Definitions, Dictionaries, and Meanings - Norman Swartz, (http://www.sfu.ca/philosophy/swartz/definitions.htm) 1997 Simon Fraser University
SEMNETS02 Semantic Networks - John F. Sowa, (http://www.jfsowa.com/pubs/semnet.htm) 2002
SEMNETG82 Three Principles of Representation for Semantic Networks - Robert L. Griffith, (http://www.sfu.ca/philosophy/swartz/definitions.htm) 1982 IBM
ONTADGL02 Ontology Applications and Design - Michael Gruninger, Jintae Lee, (http://portal.acm.org/citation.cfm?id=503124.503145) 2002
DATAONT05 Data Modeling vs. Ontology Engineering - Peter Spyns, Robert Meersman, Mustafa Jarrar, (http://www-scf.usc.edu/~csci586/ppt-2005/modeling.ppt) 2005
ONTPADE05 The Web of Patterns Project - Object-Oriented Software Design Ontology ODOL - Jens Dietrich, Chris Elgar, (http://www-ist.massey.ac.nz/wop/) 2005
EXPERTD01 Nepravidlové a hybridní expertní systémy - Jirí Dvorák, (http://www.uai.fme.vutbr.cz/jdvorak/vyuka/es/NonRuleES.ppt) 2001 VUTBR
ONTOLED03 Seminar Ontology Learning - Ying Ding, (http://www.deri.at/teaching/archive/docs/summer03/nextwebgen/seminar2.ppt) 2003 Next Generation Web Group, University of Innsbruck
KAEVOH04 Kaon: Szenario_1 - Creating ontologies, Evolution - hora, (http://kaon.semanticweb.org/Members/hora/S1/Szenario_1.txt) 2004
WORDNET WordNet - a lexical database for the English language - George A. Miller, Christiane Fellbaum, Randee Tengi, Susanne Wolff, Pamela Wakefield, Helen Langone, Benjamin Haskell, (http://wordnet.princeton.edu/) Princeton University
CYCORP Cycorp home - kol., (http://www.cyc.com/cyc)
OPENCYC OpenCyc: The Project - kol., (http://www.opencyc.org/)
SUMONP01 Origins of the Standard Upper Merged Ontology: A Proposal for the IEEE Standard Upper Ontology - Working Notes of the IJCAI-2001 Workshop on the IEEE Standard Upper Ontology - Niles, I., and Pease, A, (http://ontology.teknowledge.com/#FOIS) 2001
KSLSTANF Knowledge Systems, AI Laboratory (KSL) of Stanford University - kol., (http://www-ksl.stanford.edu/)
AIAI AIAI Enterprise - kol., (http://www.aiai.ed.ac.uk/project/enterprise/)
BUSMANONT The Open Source Business Management Ontology (BMO) - kol., (http://www.jenzundpartner.de/Resources/RE_OSSOnt/re_ossont.htm)
CPREDICT climateprediction.net - project page - kol., (http://www.climateprediction.net) BOINC, NERC, DTI
VIVISTAXO Vivisimo Clustering and Taxonomies - A Marriage Made.. Where? - kol., (http://vivisimo.com/docs/taxonomies.pdf) 2003 Vivisimo, Inc.
STUMBLEUP StumbleUpon - network of people and pages - kol., (http://www.stumbleupon.com/)
CRFREENET CRFreeNet - projekt neziskové broadband telekomunikacní síte v Ceské Republice - kol., (http://www.czfree.net/)
ANOTCHS04 Towards the Self Annotating Web - Philipp Cimiano, Siegfried Handschuh, Steffen Staab, (http://www.www2004.org/proceedings/docs/1p462.pdf) 2004 Institute AIFB, University of Karlsruhe
ONNAVCR00 Ontology-Supported and Ontology-Driven Conceptual Navigation on the World Wide Web - Michel Crampes and Sylvie Ranwez, (http://portal.acm.org/citation.cfm?id=336361) 2000 Laboratoire de Génie Informatique et d'Ingénierie de Production
AGENTRB95 A Planning Theory of Practical Rationality - Proceedings of AAAI'95 Fall Symposium on RationalAgency. 1-4. - Bell, J., (http://www.dcs.qmw.ac.uk/~jb/ratio/ptra.ps) 1995
VALPRBM00 Value Propositions - David Bovet and Joseph Martha, (http://www.fastcompany.com/magazine/37/ideazone.html) 2000 FastCompany
OJB Apache OJB - project page - kol., (http://jakarta.apache.org/ojb) Apache Software Foundation
EONUKMZ98 The Enterprise Ontology The Knowledge Engineering Review - Vol. 13, Special Issue on Putting Ontologies to Use - Mike Uschold, Martin King, Stuart Moralee, Yannis Zorgios, (http://www.aiai.ed.ac.uk/project/pub/documents/1998/98-ker-ent-ontology.ps) 1998
XERM Xermes - nástroj pro generování uživatelského rozhraní - , (xermes.sourceforge.net)
GHJV95 Design Patterns: Elements of Reusable Object-Oriented Software. Reading Mass. - E. Gamma, R. Helm, R. Johnson, J. Vlissides, 1995 Addison Wesley 0201633612
BMRSS96 A System of Patterns: Pattern-Oriented Software Architecture - F. Buschmann, R. Meunier, H. Rohnert, P. Sommerlad, M. Stal, 1996 John Wiley & Sons. 0471958697
ZOPE ZOPE - aplikacní server zalozený na jazyce Python - , (http://www.zope.org)
ASMZEJ03 Architektura podrizena modelu - David Zejda, (http://www.o-it.info/asm/) 2003 UHK
HMC00 The American Heritage® Dictionary of the English Language Fourth Edition - kol., 2000 Houghton Mifflin Company 0395825172
ORAVAN Tesla 4110U "Oravan" - Martin Hájek, (http://www.oldradio.cz/ts4110.htm)
XPATH XML Path Language (XPath) - James Clark, Steve DeRose, (http://www.w3.org/TR/xpath) 1999 W3C
XLINK XML Linking Language (XLink) Version 1.0 - Steve DeRose, Eve Maler, David Orchard, (http://www.w3.org/TR/xlink/) 2001 W3C
XTMSPEC XML Topic Maps (XTM) Version 1.0 - Steve Pepper, Graham Moore, (http://www.topicmaps.org/xtm/1.0/) 2001 TopicMaps.Org
PEPP02 The TAO of Topic Maps - Finding the Way in the Age of Infoglut - Steve Pepper, (http://www.ontopia.net/topicmaps/materials/tao.html) 2002 Ontopia
GARS02 What Are Topic Maps? - Lars Marius Garshol, (http://www.xml.com/pub/a/2002/09/11/topicmaps.html) 2002 O'Reilly
CPPKURP00 Kurz C++, díl 31. - Radek Pavienský, (http://www.eternal.cz/article.php?nID=261) 2000 Progres
CAIR02 Jade Tutorial: Application-defined content languages and ontologies - Giovanni Caire, (http://agentcities.cs.bath.ac.uk/docs/jade/CLOntoSupport.pdf) 2002 TILAB
OBSRLAM98 SENG 609.04 Design Pattern"Observer Design Pattern" - Stephen Lam, (http://sern.ucalgary.ca/courses/SENG/609.04/W98/lamsh/observerLib.html) 1998
PATTGOF95 Design Patterns - Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides, 1995 Addison-Wesley Professional 0201633612
ONTOSOW00 Ontology, Metadata, and Semiotics - Presented at ICCS'2000 in Darmstadt, Germany - John F. Sowa, (http://www.bestweb.net/~sowa/peirce/ontometa.htm) 2000 Springer-Verlag
ZOOPKR98 Základy objektove orientovaného programování - Ilja Kraval, 1998 Computer Press 8072260472
AMBL Mapping Objects To Relational Databases - Scott W. Ambler, (http://www.AmbySoft.com/mappingObjects.pdf) Ronin International
METADIB00 Metadata Integration using UML, MOF and XMI - Sridhar Iyengar, Steve Brodsky, (http://www.omg.org/news/meetings/workshops/presentations/uml_presentations/Tutorial%204-1%20-%20UML_Lecture4_R2.pdf) 2000 OMG and Tutorial Contributors
SCHEMED96 The Scheme Programming Language, Second Edition - Kent R. Dybvig, (http://www.scheme.com/) 1996 Electronically reproduced by permission of Prentice Hall
CLIPSMI99 Úvod do prostredí CLIPS - Peter Mikulecký, 1999 FIM UHK
SMALTHU95 Skolicka Smalltalku - Jan Hubicka, (http://www.ucw.cz/~hubicka/skolicky/skolicka12.html) 1995
JOX JOX, Linking Java Beans and XML With Ease - project page - Mark Wutka, (http://www.wutka.com/jox.html.)
KBML KBML - The Koala Bean Markup Language - project page - kol., (http://koala.ilog.fr/) Dyade
JAXB Java Architecture for XML Binding (JAXB) - project page - kol., (http://java.sun.com/xml/jaxb/) Sun Microsystems
SICO99 Cluster Profiling Project, phase 1 - Stéphane Simon, Michel Courson, (http://www.itl.nist.gov/div895/cmr/cluster/phase1/intro.html) 1999 National Institute of Standards and Technology
HEPP03 LDAP (Lightweight Directory Access Protocol) - referát - Michal Heppler, (http://www.fi.muni.cz/~kas/p090/referaty/2003-podzim/skupina10/ldap.html) 2003 MUNI
XMLKOSE00 XML pro kazdého - Jirí Kosek, 2000 8071698601
MERGKELL A Few Patterns for Managing Large Application Portfolios - Wolfgang Keller, (http://www.objectarchitects.de/ObjectArchitects/.) Generali Office Service Consulting AG, Austria
J2SDK150 Java(TM) 2 SDK, Standard Edition Documentation Version 1.5.0 - kol., (http://java.sun.com) Sun Microsystems
XMLCJSY02 A friendly game of tug of war: XMLC vs. JSP - David H. Young, (http://www.theserverside.com/articles/article.tss?l=XMLCvsJSP) 2002 The Server Side
XFORMS XForms - The Next Generation of Web Forms - project page - kol., (http://www.w3.org/MarkUp/Forms/) W3C
WAFEREW Wafer project - Anthony Eden, Thomas Wheeler, (http://www.waferproject.org/index.html) SourceForge
XERMES Xermes - interim project page - David Zejda, (http://xermes.sourceforge.org) 2002
FFORMENM File Format Encyclopedia 2.0 - Michael Metz, (http://pipin.tmd.ns.ac.yu/extra/fileformat/)
PSCRPTM97 First Guide to PostScript - E. Weingar, (http://www.cs.indiana.edu/docproject/programming/postscript/postscript.html) 1997 Indiana University
SVG Scalable Vector Graphics (SVG) 1.1 Specification - kol., (http://www.w3.org/TR/SVG/) 2003 W3C
SOAP12 SOAP Version 1.2 Part 0: Primer - kol., (http://www.w3.org/TR/soap/) 2003 W3C
TRILAYCH Trívrstvová architektura klient-server - Petr Cerha, Roman Hladký, (http://www.fi.muni.cz/~mara/odbc/3u_a/3t_a.html.iso-8859-1)
SAASLBM04 Service-Based Software: The Future for Flexible Software - Asia-Pacific Software Engineering Conference, Singapore - P. J. Layzell, K. H. Bennett, D. Budgen, O. P. Brereton, L. A. Macaulay, M. Munro, (http://www.service-oriented.com/publications/APSEC2000.pdf) 2000 Universities of Durham, Keele and UMIST
SAASWHC04 Why Software-as-a-Service? (blog) - David Coursey, (http://blog.ziffdavis.com/coursey/archive/2004/12/17/5112.aspx) 2004
IBROKER04 Using Web Service Technologies to create an InformationBroker: An Experience Report - Proceedings of the 26th International Conference on Software Engineering (ICSE'04) - Mark Turnera, Fujun Zhub, Ioannis Kotsiopoulosc, Michelle Russelld, David Budgena, KeithBennettb, Pearl Breretona, John Keanec, Paul Layzellc and Michael Rigbyd, (http://www.icse-conferences.org/2004/index.html) 2004 IEEE
P2PLTDN Using a P2P architecture to provide interoperability between LearningObjects - Stefaan Ternier, Erik Duval, Filip Neven, (http://www.cs.kuleuven.ac.be/~hmdb/publications/files/pdfversion/41251.pdf) Dept. Computerwetenschappen
INTAGEM04 Inteligentní agenti - Václav Matousek, (http://lucifer.fav.zcu.cz/uir/predn/P8/Folie_IntAg.pdf) 2004 ZCU
CLSERRK97 Client/Server Architectures for Business Information Systems A Pattern Language - Klaus Renzel, Wolfgang Keller, (http://www.sdm.de/g/arcus) 1997 EA Generali, Austria